服务状态管理
注册中心提供的健康检测功能,是为了监控服务提供方节点,以便及时将不健康的节点从可用列表中及时移除。
为什么要有
- 因为有了集群,所以每次发请求前,RPC框架都会根据路由和负载均衡算法选择一个具体的IP地址。
- 而RPC通信过程中,服务的上线和下线是由服务端主动向注册中心注册、取消注册来实现的,这在正常的流程中是没有问题的。
- 但是,如果某一个服务端意外故障,比如说机器掉电,网络不通等情况,服务端就没有办法向注册中心通信,将自己从服务列表中删除,那么客户端也就不会得到通知,它就会继续向一个故障的服务端发起请求,也就会有错误发生了。那么这种情况应该如何避免呢?怎么保证选择出来的连接一定是可用的呢?
- 其实,这种情况是一个服务状态管理的问题
- 终极的解决方案是让调用方实时感知到节点的状态变化
怎么做
我们知道,当服务方下线,正常情况下我们肯定会收到连接断开的通知事件,那是不是在这个事件里面直接加处理逻辑不就可以了?
不行的,因为应用健康状况不仅包括TCP连接状况,还包括应用本身是否存活,很多情况下TCP连接没有断开,但应用可能已经僵死了。
针对上面的问题,一般会有两种解决思路。
主动探测
方法是这样
你的RPC服务要打开一个端口,然后由注册中心每隔一段时间(比如30s)探测这些端口是否可用,如果可用就认为服务仍然是正常的,否则就认为服务不可用,那么注册中心就可以把服务从列表中删除了。
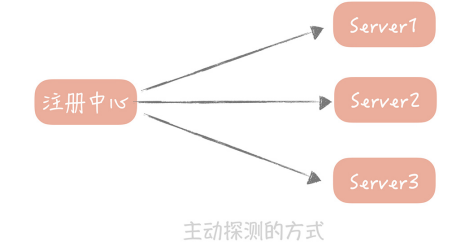
微博早期的注册中心就是采用这种方式,但是后面出现的两个问题,让我们不得不对它做改造。
- 第一个问题是:所有的RPC服务端都需要,开发一个统一的端口给注册中心探测,那时候还没有容器化,一台物理机上会混合部署很多服务,你需要开放的端口很可能已经被占用,这样会造成RPC服务启动失败
- 第二个问题是:如果RPC服务端部署的实例比较多,那么每次探测的成本也会比较高,探测的时间也比较长,这样当一个服务不可用时,可能会有一段时间的延迟,才会被注册中心监测到。
因此,我们后面把它改造成了心跳模式。
心跳机制
所谓心跳机制,就是服务调用方每隔一段时间就问一下服务提供方,“你还好吗?”,服务提供方就会告知调用方它目前的状态。
三种状态
服务提供方的状态一般会有三种状态,一个是我很好,一个是我生病了,一个是没有回复。即:
- 健康状态:建立连接成功,并且心跳探活也一直成功
- 亚健康状态:建立连接成功,单向心跳请求连续失败
- 死亡状态:连接连接失败
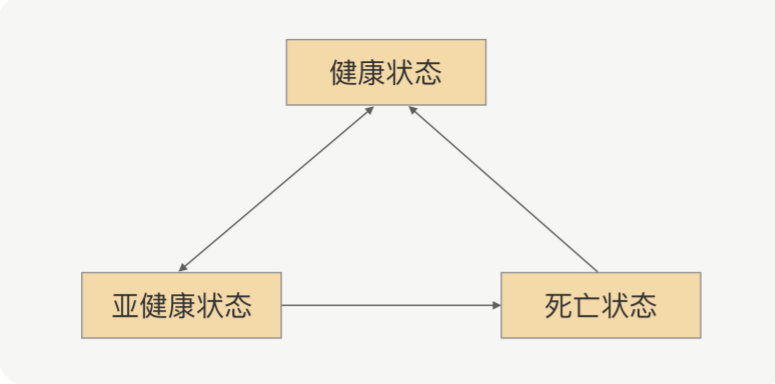
节点的状态不是固定不变的,它会根据心跳或者重连的结果来动态变化,具体状态间转换如下图:
-
首先,一开始初始化的时候,如果建立连接成功,那就是健康状态,否则就是死亡状态。这里没有亚健康这样的中间态。紧接着,如果健康状态的节点连续出现几次不能响应心跳请求的情况,那就回被标记为亚健康状态(生病)。
-
生病之后(亚健康状态),如果连续几次(可以配置)都能正常响应心跳请求,那就转为健康状态,证明病好了。如果病一直好不了,那就会被断定为是死亡节点,死亡之后还需要善后,比如关闭连接。
-
当然,死亡并不是真正的死亡,它还有复活的机会。如果在某个时间点里,死亡的节点能够重连成功,那么就可以重新标记为健康状态
当服务调用方通过心跳机制了解了节点的状态之后,每次发请求的时候,就可以优先从健康列表里面选择一个节点。当然,如果健康列表为空,为了提高可用性,也可以尝试从亚健康列表里面选择一个,这就是具体的策略了。
怎么实现
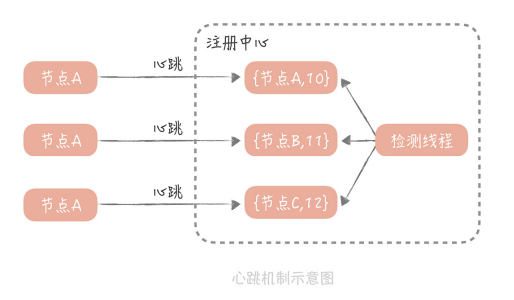
谁来提供?大部分注册中心提供的,检测连接上来的RPC服务端是否存活的方式。实现方法:
- 注册中心为每一个连接上来的RPC服务节点,记录最近续约的时间
- RPC服务节点在启动注册到注册中心后,就按照一定的时间间隔(比如30s),向注册中心发送心跳包。
- 正常情况下,我们大概30s会发一次心跳请求,
- 这个间隔一般不会太短,如果太短会给服务节点造成很大的压力;
- 也不会太长,太长会导致不能及时摘除有问题的节点
- 注册中心在接收到这个心跳包之后,会更新这个节点的最近续约时间。
- 然后,注册中心会启动一个定时器,定期检测当前时间和节点,最近续约时间的差值,如果到底一个阈值(比如90s),那么就认为这个服务不可用。
心跳时好时坏怎么办?
心跳时好时坏,也就意味着失败次数根本没有到达阈值,调用方只会觉得它是生病了,并且很快就好了。怎么解决呢?
能不能调低阈值呢?可是可以,但是治标不治本。
- 第一,调用方和服务节点之间的网络瞬息万变,出现网络波动的时候会导致误判
- 第二,在负载高情况,服务端来不及处理心跳请求,由于心跳时间会很短,会导致调用方很快触发连续心跳失败而造成断开连接。
我们回到问题的本源,核心是服务节点网络有问题,心跳间歇性失败。我们现在判断节点状态只有一个维度,那就是心跳检测,那是不是可以再加上业务请求的维度呢?但是又有问题:
- 调用方每个接口的调用频次不一样,有的接口可能 1 秒内调用上百次,有的接口可能半个小时才会调用一次,所以我们不能把简单的总失败次数当做判断条件
- 服务的接口响应时间也不一样,有的接口可能1ms,有的接口可能10s,所以我们也不能把TPS当做判断条件
可以使用可用率。可用率的计算方式是某一个时间窗口内接口调用成功次数的百分比(成功次数 / 总调用次数)。当可用率低于某个比例就认为这个节点有问题,把它挪到亚健康列表,这样既考虑了高低频的调用接口,也兼顾了接口响应时间不同的问题。
小结:
- 健康检测能够帮助我们从连接列表里面过滤掉一些存在问题的节点,避免在发请求的时候选择出有问题的节点而影响业务。
- 但是在设计健康检测方案的时候,我们不能简单的从TCP连接是否健康、心跳是否正常等简单维度考虑,因为健康检测的目的就是要保证“业务无损”
- 所以在设计方案的时候,我们可以加入业务请求的可用率因素,这样能最大化的提升RPC接口可用率
心跳机制在其他系统中的使用
除了在RPC框架里面我们会采用定时“健康检测”,其实在其他分布式系统设计的时候也会用到“心跳探活”机制。
- 比如在设计应用监控系统的时候,需要对不健康的应用实例进行报警,好让运维人员及时处理。和RPC例子一样,也不能简单的依赖端口的连通性来判断应用是否存活,因为在端口连通正常的情况下,应用也可能僵死了
- 那有啥其他方法能处理应用僵死的情况吗?我们可以让每个应用实例提供一个“健康检测”的URL,检测程序定时通过构造HTTP请求访问该URL,然后根据响应结果来进行存活判断,这样就可以防止僵死状态的误判
- 加完心跳机制,是不是就没有问题了呢?当然不是,因为检测程序所在的机器和目标机器之间的网络可能还会出现故障,如果真的出现了故障,不是会误判吗?你以为人家生病或者挂了,其实是心跳仪器坏了
- 要想减少误判的记录,可以把检测程序部署在多个机器里面,分布在不同的机架,不同的机房。因为网络同时故障的概率非常低,所以只要任意一个检测程序实例访问目标机器正常,那可以说明该目标机器正常
服务中心自己故障了怎么办?
有了心跳机制之后,注册中心就可以管理注册的服务节点的状态了,也让你的注册中心成为了整体服务最重要的组件,因为一旦它出现问题或者代码出现 Bug,那么很可能会导致整个集群的故障。
我们需要给注册中心增加保护的策略:如果摘除的节点占到了服务集群节点数的 40%,就停止摘除服务节点,并且给服务的开发同学和,运维同学报警处理(这个阈值百分比可以调整,保证了一定的灵活性)。
另外一个问题是通知风暴。 比如你的服务有 100 个调用者,有 100 个节点,那么变更一个节点会推送 100 * 100 = 10000 个节点的数据。那么如果多个服务集群同时上线或者发生波动时,注册中心推送的消息就会更多,会严重占用机器的带宽资源,这就是“通知风暴”
- 可以通过扩容注册中心节点的方式来解决;
- 也可以规范一下对于注册中心的使用方式,如果只是变更某一个节点,那么只需要通知这个节点的变更信息即可;
- 可以在其中加入一些保护策略,比如说如果通知的消息量达到某一个阈值就停止变更通知。
小结
- 注册中心可以让我们动态的变更RPC服务的节点信息,对于动态扩缩容,故障快速恢复,以及服务的优雅关闭都有重要的意义;
- 心跳机制是一种常见的探测服务状态的方式
- 我们需要对注册中心管理的节点提供一些保护策略,避免节点被过渡摘除导致服务不可用
最后
以上就是落后煎蛋最近收集整理的关于RPC:注册中心是如何检测服务方节点是否存活的?服务状态管理服务中心自己故障了怎么办?小结的全部内容,更多相关RPC:注册中心是如何检测服务方节点是否存活内容请搜索靠谱客的其他文章。








发表评论 取消回复