Python爬虫学习记录(1)——BeautifulSoup爬取天气信息
上节学习了flask简单使用并且爬取网站,本节学习BeautifulSoup爬取天气信息
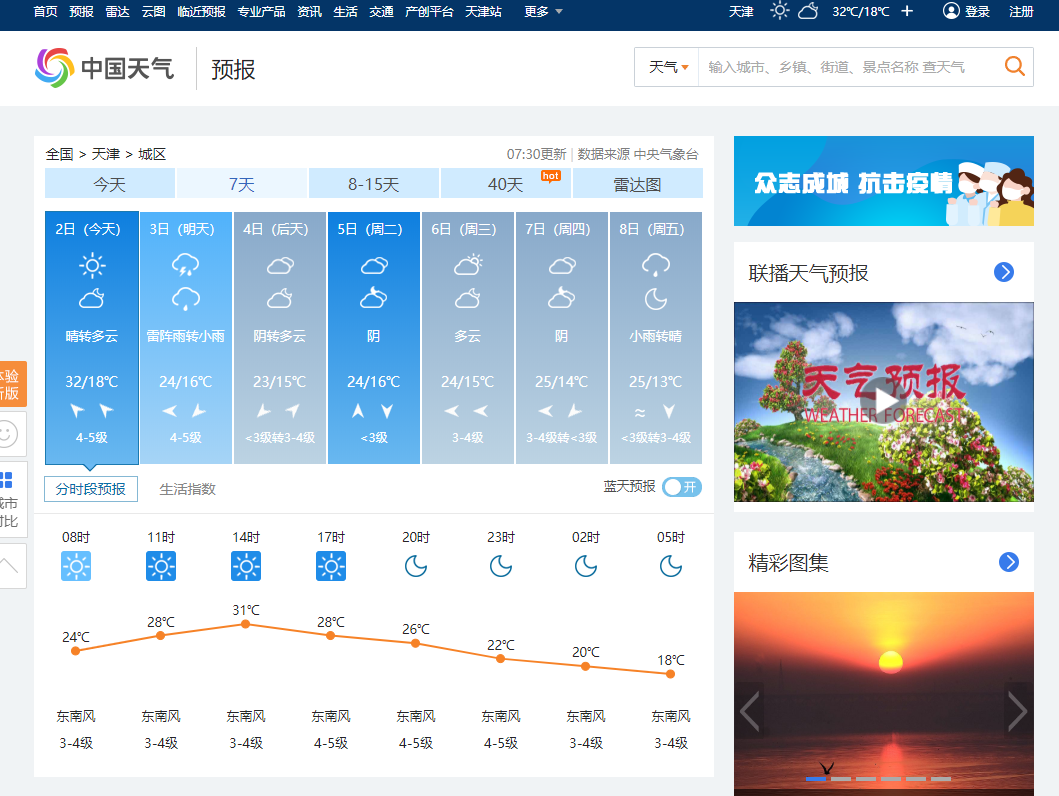
打开网站:http://www.weather.com.cn/weather/101030100.shtml 可以看到天津天气七天信息
查看网页源代码:分析一天的天气标签 ul li h1 p span i win

下面开始编写代码:
BeautifulSoup的详细使用方法就不再介绍网上应该有很多,这里只针对本练习使用。
1.首先导入requests、BeautifulSoup库
import requests
from bs4 import BeautifulSoup2.编写获取网页函数:
def getHTMLText(url):
try:
r = requests.get(url,timeout=10)#获取网页
r.raise_for_status()#确认编码方式
r.encoding = r.apparent_encoding#编码
return r.text#返回获取网页文本
except Exception as e:
print(e)
return ""3.编写处理网页文本函数:
def buildList(ulist,html):
soup = BeautifulSoup(html,"lxml")
lis = soup.select("ul[class='t clearfix'] li")
for li in lis:
try:
date = li.select('h1')[0].text
weather = li.select('p[class="wea"]')[0].text
temp = li.select('p[class="tem"] span')[0].text + "/" + li.select('p[class="tem"] i')[0].text
win = li.select('p[class="win"] i')[0].text
data = [date,weather,temp,win]
ulist.append(data)
except Exception as e:
print(e)4.编写显示天气函数:
def showList(ulist):
split = "{0:^10}t{1:{4}^10}{2:{4}^10}t{3:^10}"
isplit = "{0:^10}t{1:{4}^10}t{2:{4}^10}t{3:{4}^10}"
print(split.format("时间","天气","温度","风量",chr(12288)))
for list in ulist:
print(isplit.format(list[0],list[1],list[2],list[3],chr(12288)))5.主函数开始运行:
if __name__ == '__main__':
ulist = []
url = "http://www.weather.com.cn/weather/101030100.shtml"
html = getHTMLText(url)
buildList(ulist,html)
showList(ulist)运行成功结果:
时间 天气 温度 风量
2日(今天) 晴转多云 32/18℃ 4-5级
3日(明天) 雷阵雨转小雨 24/16℃ 4-5级
4日(后天) 阴转多云 23/15℃ <3级转3-4级
5日(周二) 阴 24/16℃ <3级
6日(周三) 多云 24/15℃ 3-4级
7日(周四) 阴 25/14℃ 3-4级转<3级
8日(周五) 小雨转晴 25/13℃ <3级转3-4级
记录学习过程
最后
以上就是唠叨黑夜最近收集整理的关于Python爬虫学习记录(1)——BeautifulSoup爬取天气信息的全部内容,更多相关Python爬虫学习记录(1)——BeautifulSoup爬取天气信息内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复