在一个群里看到有个群友有个需求:有八门课的名单,每行名单为每门课的名单,想统计每个人选课的次数
数据形式如下:
思路:
读取所有名单,利用set集合创建不重复的list,然后创建字典,再利用字典的key对名单进行遍历
知识点:
- 利用with open 操作读取文件
- 利用set创建不重复的列表
- 利用zip用两个列表创建字典
- 利用sorted对字典按键或者值进行排序
代码:
# -*- coding: utf-8 -*-
__author__ = 'fff_zrx'
filepath='testdata.txt'
#读取数据
with open(filepath,encoding='utf-8') as file_obj:
contents=file_obj.read()
result=str(contents).replace('n',' ').split(' ')
#利用set创建不重复列表
name_list=list(set(result))
value_list=[0 for name in name_list]
#利用zip创建字典
count_dict=dict(zip(name_list,value_list))
for name in result:
count_dict[name]+=1
#利用value对字典进行降序排列
dict=sorted(count_dict.items(), key=lambda e: e[1],reverse=True)
print(dict)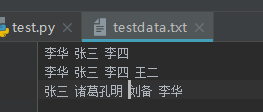
testdata.txt长这样

Python中字典的排序分为按“键”排序和按“值”排序
按值(value)排序:
sorted(dict.items(), key=lambda item:item[1], reverse=True)按键(key)排序:
sorted(dict.items(), key=lambda item:item[0], reverse=True)dict的items()函数返回的是一个列表,列表的每个元素是一个键和值组成的元组,
所以sorted(dict.items(), key=lambda e:e[1], reverse=True)返回的值同样是由元组组成的列表
item表示dict.items()中的一个元素,item[0]表示按键排序,item[1]则表示按值排序。
reverse=False可以省略,默认为升序排列。
最后
以上就是微笑星星最近收集整理的关于python利用dict统计每个文本的出现次数的全部内容,更多相关python利用dict统计每个文本内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复