要求:任给一个英文文本文件,统计该文本的所有单词(不区分大小写),包括其出现的总次数,频度,以及出现的行号和位置
1.进行数据结构的准备(链表)
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
typedef struct Coordinate {
int line; //行号
int row; //列号
struct Coordinate* next;
} Coord;
typedef struct NUM {
char Num[100]; //单词
float i; //次数
Coord *P;
struct NUM* next;
} number;
void Sum();
int main() {
Sum(); //统计单词总数
return 0;
}
2.Sum函数的具体描述
void Sum() {
int i,j,row_1=1,line_1=1;
float sum=0;
char ch;
number *N,*head,*end;
head=(number*)malloc(sizeof(number));
end=head;
FILE*file;
if((file=fopen("sum.txt","r"))==NULL) { //选择相应的文本文件
printf("不能打开文件");
exit(0);
}
N=(number*)malloc(sizeof(number));
while(fscanf(file,"%s",N->Num)!=EOF) {
N->P=(Coord*)malloc(sizeof(Coord));
N->i=1;
end->next=N;
end=N;
sum++;
fscanf(file,"%c",&ch);
if(ch!='n') {
N->P->row=row_1;
N->P->line=line_1;
row_1++;
} else {
N->P->row=row_1;
N->P->line=line_1;
row_1=1;
line_1++;
}
N=(number*)malloc(sizeof(number));
}
end->next=NULL;
fclose(file);
printf("这篇文章共有%.0f个单词n",sum);
number *A,*B;
Coord* HEAD,*M,*END;
A=head->next;
B=A->next;
while(A->next!=NULL) {
HEAD=(Coord*)malloc(sizeof(Coord));
HEAD=A->P;
END=HEAD;
while(B->next!=NULL) {
if(strcasecmp(A->Num,B->Num)==0) {
M=(Coord*)malloc(sizeof(Coord));
A->i=A->i+B->i;
B->i=0;
M=B->P;
END->next=M;
END=M;
B=B->next;
} else
B=B->next;
}
if(strcasecmp(A->Num,B->Num)==0) {
A->i=A->i+B->i;
B->i=0;
M=B->P;
END->next=M;
END=M;
}
A=A->next;
B=A->next;
END->next=NULL;
}
HEAD=(Coord*)malloc(sizeof(Coord));
HEAD=A->P;
END=HEAD;
END->next=NULL;
number*Node;
Node=(number*)malloc(sizeof(number));
Node=head->next;
while(Node->next!=NULL) {
if(Node->i!=0) {
printf("%+10s 出现频率为%.2f 共%.0f次 : ",Node->Num,(Node->i)/sum,Node->i);
while(Node->P->next!=NULL) {
printf("在第%d行 第%d列、",Node->P->line,Node->P->row);
Node->P=Node->P->next;
}
printf("在第%d行 第%d列 ",Node->P->line,Node->P->row);
printf("n");
Node=Node->next;
} else
Node=Node->next;
}
if(Node->i!=0) {
printf("%+10s 出现频率为%.2f 共%.0f次 : ",Node->Num,(Node->i)/sum,Node->i);
while(Node->P->next!=NULL) {
printf("在第%d行 第%d列、",Node->P->line,Node->P->row);
Node->P=Node->P->next;
}
printf("在第%d行 第%d列 ",Node->P->line,Node->P->row);
}
}
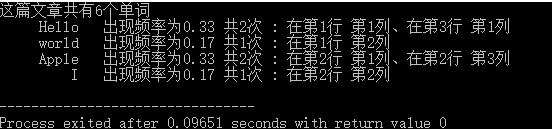
运行结果:
最后
以上就是虚拟鸡最近收集整理的关于文本单词统计(C语言)的全部内容,更多相关文本单词统计(C语言)内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复