初学Python,想做一个小练习,结果发现自己出了很多问题。好在最后解决了,也收获了新的知识。学习笔记,分享给大家参考,一起共同进步。
一、练习要求
要求读取文件”只因你太美“,(歌词链接:https://zhidao.baidu.com/question/1547567757150363867.html)并且统计出其中的”只因你太美“出现的次数还有”baby“出现的次数(提示:可以根据每句歌词之后都有一个空格,利用空格拆分字符串,变成的列表进行for循环遍历统计出现的次数)
错误代码:
num_1=0
num_2=0
with open("d:鸡你太美.txt","r",encoding="utf-8") as f:
my_str=f.read()
my_list=my_str.split(" ")
for line in my_list:
if line=="只因你太美":
num_1+=1
print()
with open("d:鸡你太美.txt","r",encoding="utf-8") as f:
my_str=f.read()
my_list=my_str.split(" ")
for line in my_list:
if line=="baby":
num_2+=1
print(my_list)
print()
print(f"'只因你太美'出现的次数有{num_1}次")
print(f"'baby'出现的次数有{num_2}次")

可以看到运行的结果,其实并不正确,因为没有考虑到每句话之后换行,变成列表会产生n而这个n和我们的字符串连接在一起,就会干扰我们的判断,导致计数错误。应该想到使用字符串的strip()进行去除前后的空格和换行,那么就可以在使用split()分割转换成列表之后不会产生n了那么就可以更加方便的计数了。
更正代码:
num_1=0
num_2=0
with open("D:鸡你太美.txt","r",encoding="utf-8") as f:
for my_str in f:
my_str=my_str.strip()
my_str_n=my_str.split(" ")
#print(type(my_str_n))
#print(my_str_n)
for line in my_str_n:
if line=='只因你太美':
num_1+=1
with open("D:鸡你太美.txt","r",encoding="utf-8") as f_n:
for my_str in f_n:
my_str=my_str.strip()
my_str_n=my_str.split(" ")
#print(type(my_str_n))
print(my_str_n)
for line in my_str_n:
if line=='baby':
num_2+=1
print(f"'baby'的个数{num_2}")
print(f'"只因你太美"出现了{num_1}次')
print(f'"baby"出现了{num_2}次') 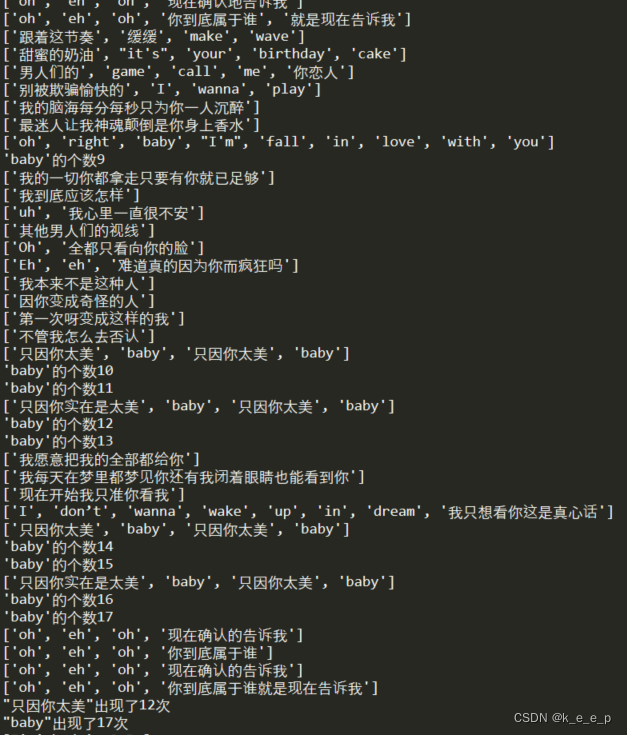
但是其实这个代码都还是统计结果有问题,至于为什么。先看看正确代码之后最后讨论
正确代码:
with open("D:鸡你太美.txt","r",encoding="utf-8") as f_m:
content=f_m.read()
print(type(content))
num_3=content.count("baby")
num_4=content.count("只因你太美")
print(f"'baby'出现的次数{num_3}n'只因你太美'出现的次数{num_4}")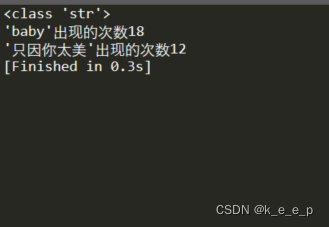
其实正确代码就是这么简单,怪自己学的不好没想到利用count()计数。这样一下子就解决问题了。那么现在再来说一下为啥第二个代码都还是有问题呢,其实是因为 最后其实发现,后两个的代码对于”baby”的计数不一致,其实产生这样的原因是因为。第一个方式是对列表进行遍历有一个列表是
![]()
当遇到这个列表的时候并没有的单独出现”baby”这个词所以没有计数。而后者方法就是对字符串进行操作,利用count()以关键词的形式进行计数,所以遇到”baby”就会计数。这也是导致两个运行结果相差1的原因
以上就是我的学习总结,欢迎大家参考,指正。第一次发希望大家多多建议,哈哈。一起进步!
最后
以上就是真实枕头最近收集整理的关于使用Python读取文件内容并对内容中的指定关键词计数的全部内容,更多相关使用Python读取文件内容并对内容中内容请搜索靠谱客的其他文章。








发表评论 取消回复