概念
TF-IDF(term frequency–inverse document frequency)是一种用于资讯检索与资讯探勘的经常使用加权技术。TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的当中一份文件的重要程度。
字词的重要性随着它在文件里出现的次数成正比添加。但同一时候会随着它在语料库中出现的频率成反比下降。TF-IDF加权的各种形式常被搜寻引擎应用,作为文件与用户查询之间相关程度的度量或评级。
除了TF-IDF以外,因特网上的搜寻引擎还会使用基于连结分析的评级方法,以确定文件在搜寻结果中出现的顺序。
原理
在一份给定的文件中。词频 (term frequency, TF) 指的是某一个给定的词语在该文件中出现的次数。这个数字一般会被归一化(分子一般小于分母 差别于IDF),以防止它偏向长的文件。(同一个词语在长文件中可能会比短文件有更高的词频。而无论该词语重要与否。
)
逆向文件频率 (inverse document frequency, IDF) 是一个词语普遍重要性的度量。某一特定词语的IDF,能够由总文件数目除以包括该词语之文件的数目,再将得到的商取对数得到。
某一特定文件内的高词语频率。以及该词语在整个文件集合中的低文件频率。能够产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
TFIDF的主要思想是:假设某个词或短语在一篇文章中出现的频率TF高,而且在其它文章中非常少出现,则觉得此词或者短语具有非常好的类别区分能力。适合用来分类。TFIDF实际上是:TF * IDF,TF词频(Term Frequency),IDF反文档频率(Inverse Document Frequency)。
TF表示词条在文档d中出现的频率(还有一说:TF词频(Term Frequency)指的是某一个给定的词语在该文件里出现的次数)。IDF的主要思想是:假设包括词条t的文档越少。也就是n越小。IDF越大。则说明词条t具有非常好的类别区分能力。假设某一类文档C中包括词条t的文档数为m,而其他类包括t的文档总数为k。显然全部包括t的文档数n=m+k,当m大的时候,n也大,依照IDF公式得到的IDF的值会小,就说明该词条t类别区分能力不强。(还有一说:IDF反文档频率(Inverse Document Frequency)是指果包括词条的文档越少,IDF越大,则说明词条具有非常好的类别区分能力。)可是实际上,假设一个词条在一个类的文档中频繁出现,则说明该词条可以非常好代表这个类的文本的特征,这种词条应该给它们赋予较高的权重。并选来作为该类文本的特征词以差别与其他类文档。这就是IDF的不足之处.
在一份给定的文件中。词频(term frequency,TF)指的是某一个给定的词语在该文件中出现的频率。
这个数字是对词数(term count)的归一化,以防止它偏向长的文件。(同一个词语在长文件中可能会比短文件有更高的词数。而无论该词语重要与否。)对于在某一特定文件中的词语 ti 来说,它的重要性可表示为:
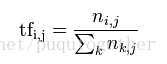
以上式子中 nij是该词在文件dj中的出现次数,而分母则是在文件dj中全部字词的出现次数之和。
逆向文件频率(inverse document frequency,IDF)是一个词语普遍重要性的度量。某一特定词语的IDF。能够由总文件数目除以包括该词语之文件的数目,再将得到的商取对数得到:
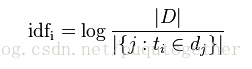
当中
- |D|:语料库中的文件总数
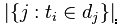 包括词语的文件数目(即nij!=0的文件数目)假设该词语不在语料库中,就会导致被除数为零,因此普通情况下使用
包括词语的文件数目(即nij!=0的文件数目)假设该词语不在语料库中,就会导致被除数为零,因此普通情况下使用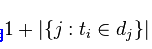
然后
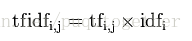
某一特定文件内的高词语频率。以及该词语在整个文件集合中的低文件频率。能够产生出高权重的TF-IDF。
因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
演示样例
一:有非常多不同的数学公式能够用来计算TF-IDF。
这边的样例以上述的数学公式来计算。
词频 (TF) 是一词语出现的次数除以该文件的总词语数。假如一篇文件的总词语数是100个,而词语“母牛”出现了3次,那么“母牛”一词在该文件里的词频就是3/100=0.03。一个计算文件频率 (DF) 的方法是測定有多少份文件出现过“母牛”一词。然后除以文件集里包括的文件总数。所以。假设“母牛”一词在1,000份文件出现过,而文件总数是10,000,000份的话,其逆向文件频率就是 log(10,000,000 / 1,000)=4。
最后的TF-IDF的分数为0.03 * 4=0.12。
二:依据keywordk1,k2,k3进行搜索结果的相关性就变成TF1*IDF1 + TF2*IDF2 + TF3*IDF3。比方document1的term总量为1000。k1,k2,k3在document1出现的次数是100,200。50。
包括了 k1, k2, k3的docuement总量各自是 1000, 10000。5000。document set的总量为10000。 TF1 = 100/1000 = 0.1 TF2 = 200/1000 = 0.2 TF3 = 50/1000 = 0.05 IDF1 = log(10000/1000) = log(10) = 2.3 IDF2 = log(10000/100000) = log(1) = 0; IDF3 = log(10000/5000) = log(2) = 0.69 这样keywordk1,k2,k3与docuement1的相关性= 0.1*2.3 + 0.2*0 + 0.05*0.69 = 0.2645 当中k1比k3的比重在document1要大。k2的比重是0.
三:在某个一共同拥有一千词的网页中“原子能”、“的”和“应用”分别出现了 2 次、35 次 和 5 次。那么它们的词频就各自是 0.002、0.035 和 0.005。
我们将这三个数相加,其和 0.042 就是对应网页和查询“原子能的应用” 相关性的一个简单的度量。概括地讲,假设一个查询包括关键词 w1,w2,...,wN, 它们在一篇特定网页中的词频各自是: TF1, TF2, ..., TFN。 (TF: term frequency)。 那么,这个查询和该网页的相关性就是:TF1 + TF2 + ... + TFN。
读者可能已经发现了又一个漏洞。
在上面的样例中,词“的”站了总词频的 80% 以上,而它对确定网页的主题差点儿没实用。
我们称这样的词叫“应删除词”(Stopwords),也就是说在度量相关性是不应考虑它们的频率。
在汉语中,应删除词还有“是”、“和”、“中”、“地”、“得”等等几十个。
忽略这些应删除词后,上述网页的相似度就变成了0.007,当中“原子能”贡献了 0.002,“应用”贡献了 0.005。细心的读者可能还会发现还有一个小的漏洞。在汉语中,“应用”是个非常通用的词。而“原子能”是个非常专业的词。后者在相关性排名中比前者重要。
因此我们须要给汉语中的每个词给一个权重。这个权重的设定必须满足以下两个条件:
1. 一个词预測主题能力越强。权重就越大。反之,权重就越小。我们在网页中看到“原子能”这个词。或多或少地能了解网页的主题。我们看到“应用”一次。对主题基本上还是一无所知。
因此,“原子能“的权重就应该比应用大。
2. 应删除词的权重应该是零。
在信息检索中,使用最多的权重是“逆文本频率指数” (Inverse document frequency 缩写为IDF)。它的公式为log(D/Dw)当中D是所有网页数。比方,我们假定中文网页数是D=10亿,应删除词“的”在所有的网页中都出现。即Dw=10亿。那么它的IDF=log(10亿/10亿)= log (1) = 0。假如专用词“原子能”在两百万个网页中出现。即Dw=200万,则它的权重IDF=log(500) =6.2。又假定通用词“应用”,出如今五亿个网页中,它的权重IDF = log(2)则仅仅有 0.7。也就仅仅说,在网页中找到一个“原子能”的比配相当于找到九个“应用”的匹配。
利用 IDF,上述相关性计算个公式就由词频的简单求和变成了加权求和,即 TF1*IDF1 + TF2*IDF2 +... + TFN*IDFN。在上面的样例中,该网页和“原子能的应用”的相关性为 0.0161,当中“原子能”贡献了 0.0126,而“应用”仅仅贡献了0.0035。这个比例和我们的直觉比較一致了。
- # This demo can extract the TF-IDF features of each big class data.
- #We further use k words corresponding to the k bigges weights as the features set for each big class.
- import IndexOfClass #import the IndexOfClass.py, to obtain the row index of each big class in the original Rujia data
- import math # the math.log10 is in this module
- fileTF=open('TF features.txt', 'w')
- numBigClass=len(IndexOfClass.dictClassR_C)-1
- for index in range(1, numBigClass+1): # 1, numBigClass+1
- print 'the '+str(index)+' class is processing...'
- fileRujia=open('Data_After_Split.txt', 'r') #open the original Rujia data file
- dictTF_IDF={}
- wordSum=0 #mark the sum of frequency of words, i.e. the denumerator of TF
- rowHead=IndexOfClass.dictClassR_C[index] # head row of the index class
- rowTail=IndexOfClass.dictClassR_C[index+1] # tail row
- for line in fileRujia.readlines()[rowHead-1:rowTail-1]: # within the index class
- #print rowHead, rowTail
- #print line
- for word in line.split(): # this FOR loop counts the term times
- wordSum+=1
- if dictTF_IDF.has_key(word):
- dictTF_IDF[word]+=1
- else:
- dictTF_IDF[word]=1
- for word in dictTF_IDF:
- dictTF_IDF[word]=1.0*dictTF_IDF[word]/wordSum # to obtain the TF
- numDocument=1
- for k in range(1, numBigClass+1): # search for the number of big class containing the current word
- r1=IndexOfClass.dictClassR_C[k]
- r2=IndexOfClass.dictClassR_C[k+1]
- #print r1, r2
- fileRujia=open('Data_After_Split.txt', 'r')
- for line in fileRujia.readlines()[r1-1:r2-1]:
- #print line
- if word in line.split():
- numDocument+=1
- #print 'abc'
- break
- #print numDocument
- dictTF_IDF[word]*=math.log10(1.0*numBigClass/numDocument) # IDF
- L=sorted(dictTF_IDF.iteritems(), key=lambda asd: asd[1], reverse=True)
- for k in L[0:5]:
- fileTF.write(k[0]+' '+str(k[1])+' ')
- fileTF.write('n')
JAVA版本号的程序我也实现了,当中有很多凝视和不必要的调试语句。
- import java.io.BufferedReader;
- import java.io.File;
- import java.io.FileInputStream;
- import java.io.FileOutputStream;
- import java.io.InputStreamReader;
- import java.io.PrintWriter;
- import java.util.ArrayList;
- import java.util.Collections;
- import java.util.Comparator;
- import java.util.Iterator;
- import java.util.Map.Entry;
- import java.util.Scanner;
- import java.util.HashMap;
- import java.util.List;
- import java.util.Arrays;
- public class demo {
- /**
- * @param args
- */
- public static void main(String[] args) throws Exception{
- // TODO Auto-generated method stub
- // TODO Auto-generated method stub
- java.io.File oriDataFile=new java.io.File("originalData.txt"); //读取文件
- java.io.File classIndexFile=new java.io.File("smallClassIndex.txt");
- if(!oriDataFile.exists() && !classIndexFile.exists()){
- System.out.println(" inputFile does not exist...");
- System.exit(0);
- }
- Scanner inputData=new Scanner(oriDataFile);
- Scanner inputIndex=new Scanner(classIndexFile);
- int totalClassNum=0; //小类的类别数
- int a[]=new int[1000];
- while (inputIndex.hasNext()){
- a[totalClassNum++]=inputIndex.nextInt(); //存储每一个小类的行号,最后一个无用
- }
- // System.out.println(totalClassNum);
- java.io.File featureFile=new java.io.File("TFIDFFeatures.txt");
- java.io.PrintWriter output = new java.io.PrintWriter(featureFile);
- for(int k=0; k<totalClassNum-1; k++){ //循环遍历每一个小类 totalClassNum-1
- // System.out.println(totalClassNum);
- System.out.println("The "+(k+1)+" class is processing ...");
- int headLine=a[k]; //当前小类起始行
- int tailLine=a[k+1];//终止行
- int numLine=tailLine-headLine;
- // System.out.println(numLine);
- //---------------------TF Features-------------------------//
- // 能够统计当前类中每一个word出现的次数,TF
- System.out.println("The TF features are extracting ...");
- HashMap<String, Integer> wordMap=new HashMap<String, Integer>();
- int totalCount=0;
- for(int i=0; i<numLine; i++){
- String str=inputData.nextLine(); //提取每一行
- // System.out.println(str);
- String[] strArray=str.split(" "); //按空格分割
- totalCount+=strArray.length;
- for(int j=0; j<strArray.length; j++){
- // System.out.println(strArray[j]);
- if(!wordMap.containsKey(strArray[j])){ //假设不存在,加入
- wordMap.put(strArray[j], 1);
- }
- else{ //假设已存在。count+1
- int v=wordMap.get(strArray[j]);
- wordMap.put(strArray[j], v+1);
- }
- }
- }
- // System.out.println(totalCount);
- HashMap<String, Double> tfMap=new HashMap<String, Double>();
- Iterator it=wordMap.keySet().iterator();
- while (it.hasNext()){
- String key=(String) it.next();
- int v=wordMap.get(key);
- tfMap.put(key, 1.0*v/totalCount); //TF Map
- // System.out.println(key+1.0*v/totalCount);
- }
- //---------------------IDF Features----------------------//
- System.out.println("The IDF features are extracting ...");
- HashMap<String, Double> idfMap=new HashMap<String, Double>();
- Iterator it1=wordMap.keySet().iterator();
- while (it1.hasNext()){
- String key=(String) it1.next(); //取当前word
- // System.out.println("Searching for "+key);
- //在其余小类中查找是否出现过key
- int otherClassNum=1; //记录每一个word在其它类出现的次数
- for (int m=0; m<totalClassNum-1; m++){ //遍历全部的类 totalClassNum-1
- int beginning=a[m]; //当前其它类的起始行
- int ending=a[m+1]; //终止行
- // System.out.println(beginning);
- // System.out.println(ending);
- InputStreamReader I=new InputStreamReader(new FileInputStream("originalData.txt"), "gbk"); //编码是gbk,只是最好统一为utf-8
- BufferedReader sr = new BufferedReader(I);
- String txt=sr.readLine(); //readLine读取一行。字符串
- int next=1; //记录读取的行数
- while(txt!=null){
- if(next>=beginning-1 && next<ending){ //一定要在当前其它类才好推断
- // System.out.println(txt);
- String []str2Array=txt.split(" ");
- int l;
- for (l=0; l<str2Array.length; l++){
- if(str2Array[l].equals(key)){
- // System.out.println("Find "+key); //输出找到
- otherClassNum++;
- break; //跳出while该类的推断。期待
- }
- }
- if(l<str2Array.length) //说明已经找到
- break; //break出while循环
- }
- txt=sr.readLine(); //继续读取下一个问题
- next++;
- }
- }
- // System.out.println(key+"appears "+otherClassNum+" times"); //输出当前word在其它类其中出现的次数
- idfMap.put(key, Math.log10(1.0*(totalClassNum-1)/otherClassNum));
- // System.out.println(Math.log10(1.0*(totalClassNum-1)/otherClassNum));
- }
- //-----------TF和IDF特征的融合,并排序,取每一个小类的前五名-----------------//
- HashMap<String, Double> tfIdfMap=new HashMap<String, Double>();
- // Iterator it1=tfIdfMap.keySet().iterator();
- Iterator it2=tfMap.keySet().iterator();
- Iterator it3=idfMap.keySet().iterator();
- while(it2.hasNext() && it3.hasNext()){
- String key1=(String) it2.next();
- String key2=(String) it3.next();
- Double v=tfMap.get(key1)*idfMap.get(key2); //tf*idf
- tfIdfMap.put(key1, v); //idfTfMap
- }
- //排序
- List<Entry<String, Double>> infoIds =
- new ArrayList<Entry<String, Double>>(tfIdfMap.entrySet());
- Collections.sort(infoIds, new Comparator<Entry<String, Double>>() {
- public int compare(Entry<String, Double> o1, Entry<String, Double> o2) {
- if(o2.getValue() - o1.getValue()>0){
- return 1;
- }
- return -1;
- //return (int)(o2.getValue() - o1.getValue());
- // return (o1.getKey()).toString().compareTo(o2.getKey());
- }
- });
- int selectNum;
- if(infoIds.size()<5){ //防止有些小类问题数量少
- selectNum=infoIds.size();
- }
- else
- selectNum=5;
- for (int q=0; q<selectNum; q++){ //仅仅取前五名
- String id = infoIds.get(q).toString();
- // System.out.println(id);
- int equalIndex=id.indexOf('=');
- char []strChar=id.toCharArray();
- String fea=new String();
- for (int d=0; d<equalIndex; d++){
- fea=fea+strChar[d];
- }
- System.out.println(fea);
- output.print(fea);
- output.print(' ');
- }
- output.print('n');
- System.out.println("The "+(k+1)+" class ends...");
- }
- output.close(); //close 输出的文件
- }
- }
转载于:https://www.cnblogs.com/ljbguanli/p/7098489.html
最后
以上就是聪慧百合最近收集整理的关于TF-IDF算法及其编程实现的全部内容,更多相关TF-IDF算法及其编程实现内容请搜索靠谱客的其他文章。








发表评论 取消回复