目录
- IJCAI2020 Mucko
IJCAI2020 Mucko
- 题目
Mucko: Multi-Layer Cross-Modal Knowledge Reasoning for Fact-based Visual Question Answering
下载链接
代码链接
本文出自中科院自动化所+微软亚研+阿德莱德吴琦老师 - 动机
在现有的FVQA方法中,没有进行细粒度的选择,就将不同模态信息进行联合(共同嵌入),这为答案的推理带来了干扰(噪声)。 - 贡献
- 使用异构图对图片进行描述,包含了三种不同的信息(视觉、语义、知识),取得了显著超越SOTA方法的实验结果。
- 使用“模态感知方法”捕获不同模态中“面向question的信息”。
- 此方法具有良好的可解释性。
- 方法
本文方法的整体结构如下图所示,可以看出,有两个核心步骤:构造多模态异构图(Multi-Modal Heterogeneous Graph Construction)、跨模态异构图推理(Cross-Modal Heterogeneous Graph Reasoning)。其中,跨模态异构图推理又包含两个步骤:知识选择(Intra-Modal Knowledge Selection)、跨模态知识推理(Cross-Modal Knowledge Reasoning)。
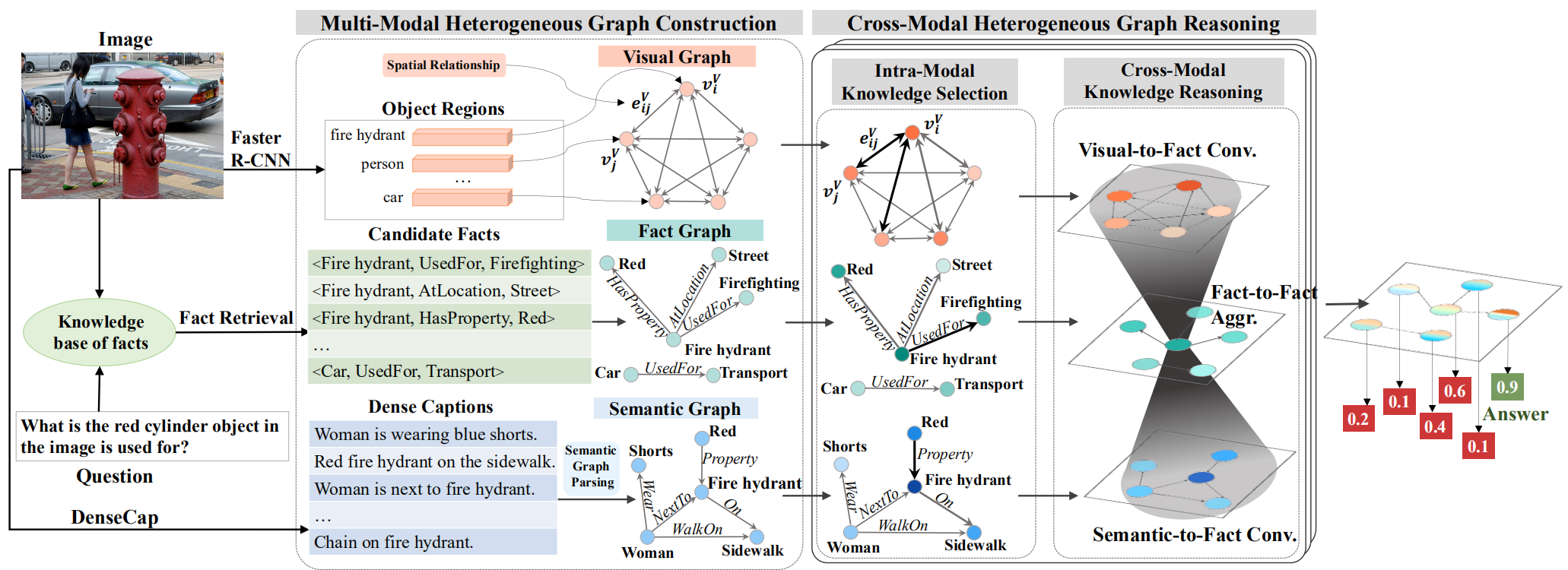
首先介绍,如何构造多模态异构图,这部分最终得到了三种不同模态的图,分别是视觉图、事实图和语义图。视觉图基于所有的regions进行构造,得到的是双向完全图,每个节点的特征即为 region的视觉特征,边的特征为两个节点的spatial feature的结合 r i , j V = [ x j − x i w i , y j − y i h i , w j w i , h j h i , w j h j w i h i ] r_{i,j}^V=[frac{x_j-x_i}{w_i},frac{y_j-y_i}{h_i},frac{w_j}{w_i},frac{h_j}{h_i},frac{w_j h_j}{w_i h_i}] ri,jV=[wixj−xi,hiyj−yi,wiwj,hihj,wihiwjhj]。语义图部分使用dense caption生成局部语义信息,将object或attribute作为节点,关系作为边,word embedding方法使用的是GloVe。事实图部分,先使用一个基于分数排序的方法,选出100个候选事实,具体做法为:计算“事实”中的每个单词的embedding和question中每个单词embedding、检测到的视觉概念中的每个单词embedding的余弦相似度,再进行平均,得到每个“事实”的分数。对于得到的100个候选事实,还要进行筛选,规则是——基于MLP预测question的relation类型,取top3,依次将100个候选事实和top3进行对比,不一致则删除。最后,基于筛选得到的事实建图。
跨模态异构图推理由迭代的两部分(知识选择、跨模态知识推理)组成,共重复 T T T次。知识选择就是在每个图上,基于question分别对节点和边添加attention,然后使用图卷积进行节点更新。跨模态知识推理先基于事实图中的每个实体(entity)+question对视觉图和语义图的节点添加注意力,再基于此注意力计算出互补信息(计算过程就是注意力和节点特征的加权平均)。分别得到视觉图和语义图的互补信息后,使用一个门机制将它们和事实图的节点信息融合。最后,使用和知识选择部分一样的操作,对事实图中的信息进行Aggregation。 - 实验
本文在三个knowledge-based VQA数据集上进行了实验,分别是FVQA、OK-VQA和Visual7W+KB。
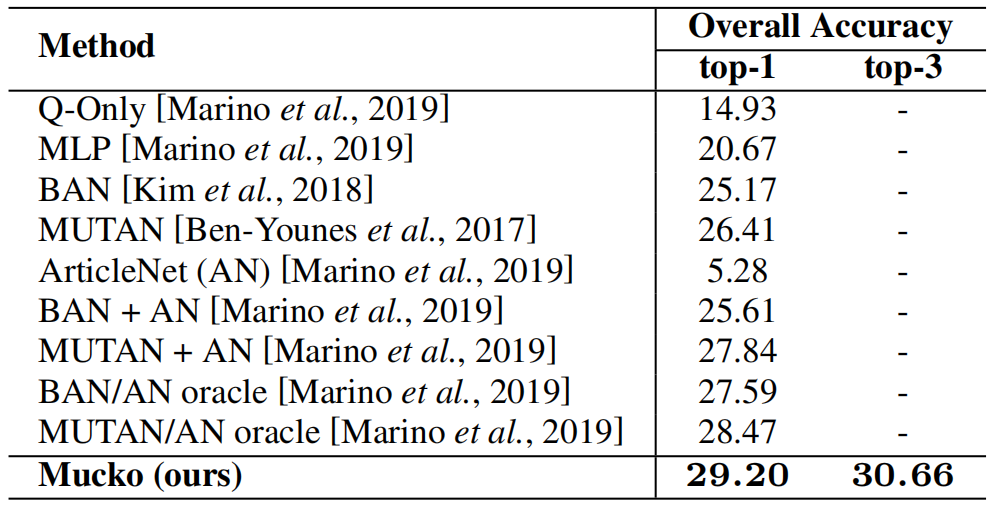
在FVQA数据集上,和SOTA方法的对比,在top1上已经要接近人类水平了。
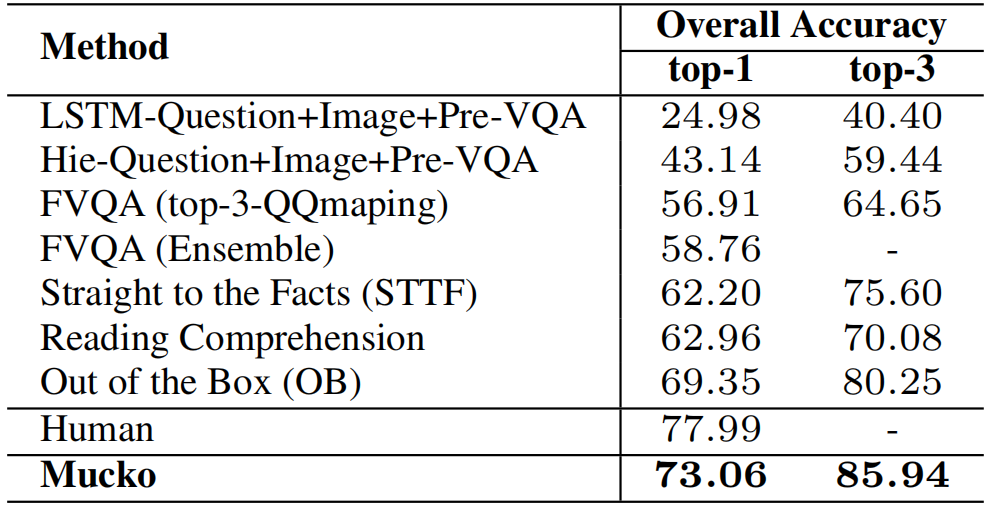
在Visual7W+KB数据集上的实验:
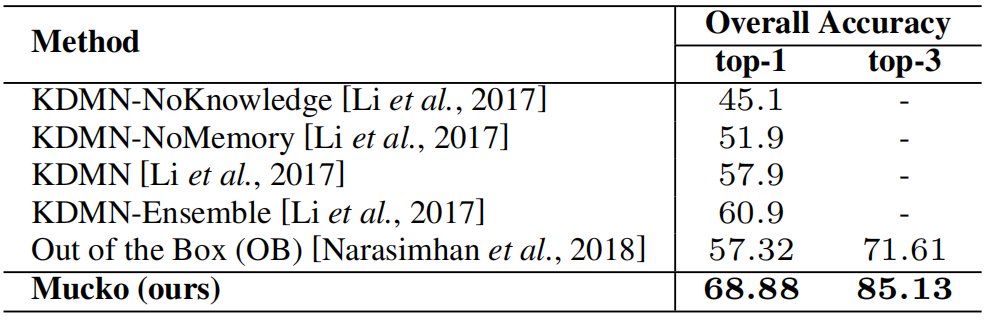
在OK-VQA数据集上的实验结果:
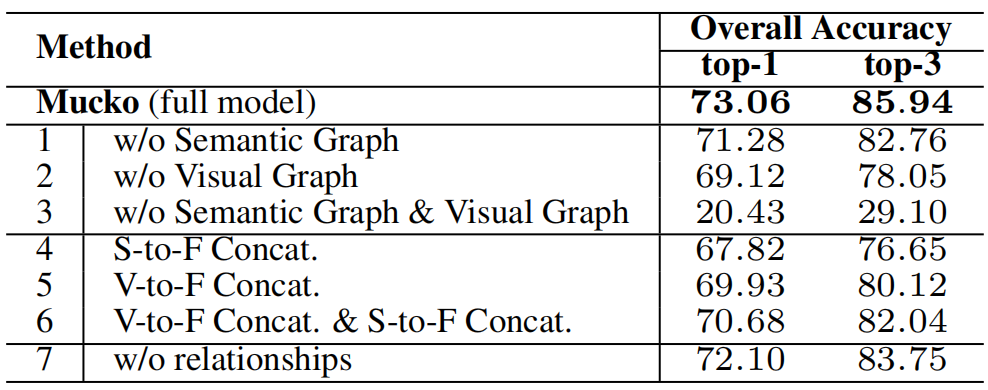
在FVQA上的消融实验:
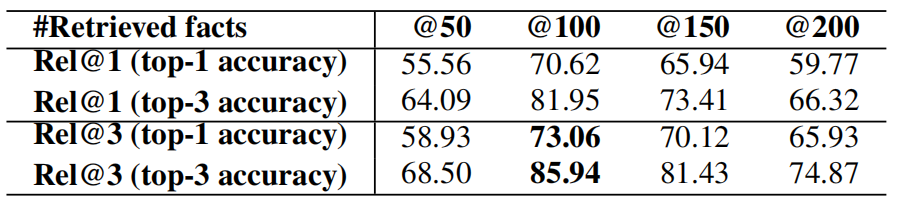
在FVQA上的超参实验:

可视化的实验结果:

最后
以上就是义气指甲油最近收集整理的关于FVQA论文汇总IJCAI2020 Mucko的全部内容,更多相关FVQA论文汇总IJCAI2020内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复