前言
CLIP带给我的震撼是超过transformer的,这是OpenAI的重要贡献之一。就如官网所描述的:
CLIP: Connecting Text and Images
用对比学习(Contrastive Learning)来对齐约束图像模型和文本模型。用文本嵌入指导图像学习,图像嵌入指导文本学习。这样一来,图像分类进入了CLIP时代,不需像传统深度学习图像分类一样,先定义出类别范围,然后准备各类别的数据(比如MNIST的十分类,ImageNet的千分类)。
我们有了CLIP,可以直接任意给出一个class set如{“cat”,“dog”, “horse”,“Other”},然后给定一张图片,CLIP自然会给出图片的类别的score。
第一次见识到CLIP能力是在MSRA的分享会上,表现出的效果非常Impressive。首先,CLIP有强大的zero-shot功能,能够在零样本的基础下在ImageNet-1K的表现超过ResNet-50.
按照惯例:
论文标题:Learning Transferable Visual Models From Natural Language Supervision
论文链接:https://arxiv.org/abs/2103.00020
github: https://github.com/OpenAI/CLIP
CLIP
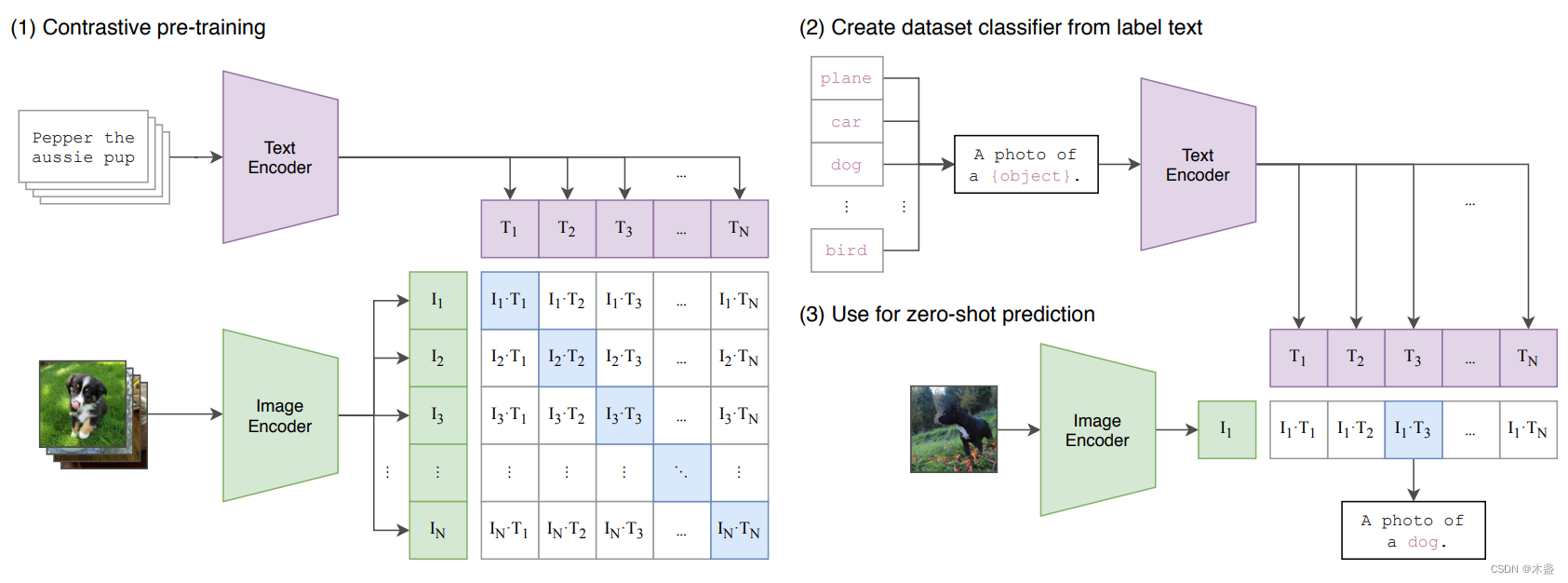
CLIP的大体思路就如上图所示,咱们有一个Image Encoder和一个Text Encoder分别把图像和文本编码为1024-d或者768-d的向量,我们叫做image embedding和text embedding。CLIP的思想是将image embedding和text embedding放到一个域里,让相应的image embedding和text embedding有更大的相似性。
这里相似性的评估是余弦相似性,概念十分简单,即两个向量夹角的余弦值。想进一步了解Cosine Similarity的可戳《【AI数学】余弦相似性(含python实现)》。
对于n个图文对,咱们可以得到一个nxn的余弦相似性矩阵,只要使对角线的位置尽可能的接近1,而其他位置尽可能接近0,这就达到了我们优化的目的。先不急着看loss function,先看对比学习的思想,作者也引用了这篇2016年的文章《Improved Deep Metric Learning with
Multi-class N-pair Loss Objective》,大概看一张图就可以:
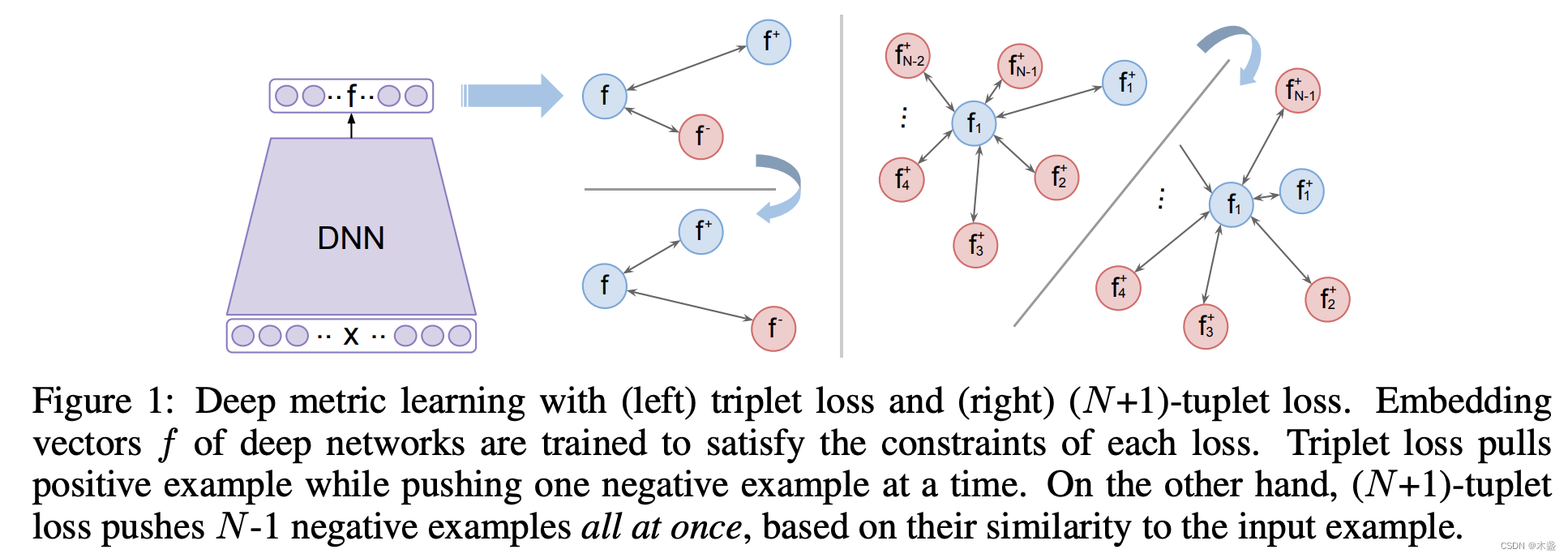
传统的深度神经网络训练方法是比较输出值和标注值的差别,让正例离近一点,让负例远离一点;而对比学习找一大堆样例,互相之间的异类尽量远。回到CLIP,对于每一个batch,只有绑定的图文对(自己)才是正例,而其他所有图文对,都构成两两之间的负例关系。
在这里我分享自己做实验的经验,CLIP这种大规模数据集的对比学习训练依赖超大的batch size,理论上batch size越大越好,一般参考值也在4096以上。而且,如果没有较大的batch size,CLIP甚至训不收敛(与训练时间无关),因为每个batch没有足够大的对比视野。想训标准版CLIP,请考虑16卡A100以上的训练条件。
我们看CLIP的训练伪代码:

这里构造了一个symmetric cross entropy,也很简单。只是把针对image部分和针对text部分的交叉熵损失函数加到一起。
我学习到这里的时候有一个疑问,为什么labels用np.arange(n)而不是用one-hot?相信很多同学也有这个疑问。我们想让相似性矩阵到对角线接近1,而其他位置为0,难道不是用一个对角阵当label吗?
事实上,代码中构造的labels等价于构造对角阵label,仔细对比我们可以发现,labels的维度是n,而logits的维度是nxn,labels维度低于logits,这是one-hot的另一种表达方式,等价于nxn的对角阵。对这点还有不明白的,可戳《【AI数学】交叉熵损失函数CrossEntropy》, 最后面有这种用法的详解。
有疑问可留言交流~
最后
以上就是含蓄酒窝最近收集整理的关于图文多模态模型CLIP的全部内容,更多相关图文多模态模型CLIP内容请搜索靠谱客的其他文章。








发表评论 取消回复