文章目录
- COCO数据库:
- 安装:
- 数据集内容说明:
- COCO数据集的标注信息
- 补充阅读:
- 图像识别计算机视觉领域的数据集分类介绍:
- Image Classification:分类
- Object Detection:物体检测
- Semantic scene labeling:图像分割
- other
- 参考:
COCO数据库:
微软发布的COCO数据库, 除了图片以外还提供物体检测, 分割(segmentation)和对图像的语义文本描述信息.
COCO数据库的网址是:
MS COCO API - http://mscoco.org/
Github网址 - https://github.com/pdollar/coco
关于API更多的细节在网站:
http://mscoco.org/dataset/#download
数据库提供Matlab, Python和Lua的API接口. 其中matlab和python的API接口可以提供完整的图像标签数据的加载, parsing和可视化.此外,网站还提供了数据相关的文章, 教程等.
在使用COCO数据库提供的API和demo时, 需要首先下载COCO的图像和标签数据.
安装:
0)首先解压数据文件:
图像数据下载,解压到coco/images/文件夹中
标签数据下载, 解压到coco/annotations/文件夹中.
1)matlab, 在matlab的默认路径中添加coco/MatlabApi
2)Python. 打开终端,将路径切换到coco/PythonAPI下,输入make
数据集内容说明:

COCO数据集的标注信息
COCO的数据标注信息包括:
- 类别标志
- 类别数量区分
- 像素级的分割

COCO数据提供的像素级图像分割的例子:

2014年版本的数据为例,一共有20G左右的图片和500M左右的标签文件。标签文件标记了每个segmentation+bounding box的精确坐标,其精度均为小数点后两位。一个目标的标签示意如下:
{"segmentation":[[392.87, 275.77, 402.24, 284.2, 382.54, 342.36, 375.99, 356.43, 372.23, 357.37, 372.23, 397.7, 383.48, 419.27,407.87, 439.91, 427.57, 389.25, 447.26, 346.11, 447.26, 328.29, 468.84, 290.77,472.59, 266.38], [429.44,465.23, 453.83, 473.67, 636.73, 474.61, 636.73, 392.07, 571.07, 364.88, 546.69,363.0]], "area": 28458.996150000003, "iscrowd": 0,"image_id": 503837, "bbox": [372.23, 266.38, 264.5,208.23], "category_id": 4, "id": 151109},
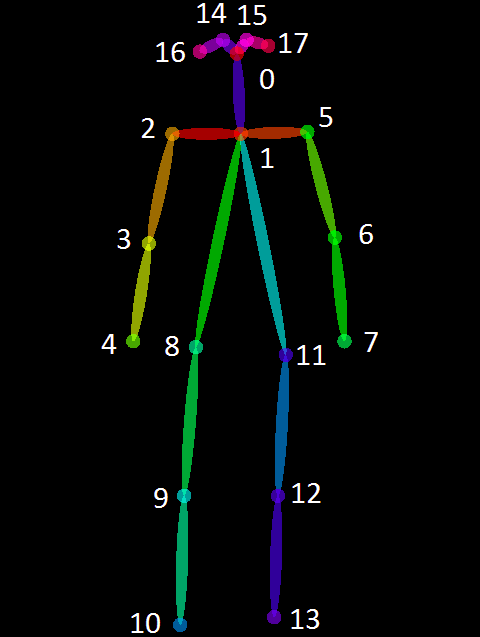
人体的keypoint也是类似的数据结构, 保存在.json文件中:
数据的基本结构是:
[{“image_id”:[],
“category_id”:[],
“keypoints”:[],
“score”:[]
}]
例如:
[{"image_id":136,"category_id":1,"keypoints":[36,181,2,20.25,191,0,35,166,2,20.25,191,0,8,171,2,20.25,191,0,2,246,2,20.25,191,0,20.25,191,0,20.25,191,0,20.25,191,0,20.25,191,0,20.25,191,0,20.25,191,0,20.25,191,0,20.25,191,0,20.25,191,0],"score":0.897},...]
“keypoints”是长度为3K的数组,K是对某类定义的关键点总数,这里人体的keypoint就是17个.位置为[x,y],关键点可见性v.
如果关键点没有标注信息,则关键点位置[x=y=0],可见性v=1;
如果关键点有标注信息,但不可见,则v=2.
如果关键点在物体segment内,则认为可见.
(1-‘nose’ 2-‘left_eye’ 3-‘right_eye’ 4-‘left_ear’ 5-‘right_ear’ 6-‘left_shoulder’ 7-‘right_shoulder’ 8-‘left_elbow’ -‘right_elbow’ 10-‘left_wrist’ 11-‘right_wrist’ 12-‘left_hip’ 13-‘right_hip’ 14-‘left_knee’ 15-‘right_knee’ 16-‘left_ankle’ 17-‘right_ankle’ )
这里提一下的是OpenPose的姿态识别用了COCO数据库,coco有17个keypoint,OpenPose增加了一个,就是编号为1的人体中心点.
COCO matlab API文件CocoApi - 加载COCO标注文件,准备数据存储结构
% getAnnIds - Get ann ids that satisfy given filter conditions.
% getCatIds - Get cat ids that satisfy given filter conditions.
% getImgIds - Get img ids that satisfy given filter conditions.
% loadAnns - Load anns with the specified ids.标注
% loadCats - Load cats with the specified ids.分类
% loadImgs - Load imgs with the specified ids.图像
% showAnns - Display the specified annotations. 显示标注
% loadRes - Load algorithm results and create API for accessing them.
% download - Download COCO images from mscoco.org server.
补充阅读:
图像识别计算机视觉领域的数据集分类介绍:
Image Classification:分类
分类需要二进制的标签来确定目标是否在图像中。
- MNIST手写数据库;顾名思义,手写数字,位于空白背景下的单一目标
- CIFAR-10/100:在32*32影像上分别提供10和100类的图片中物品的分类信息.网址https://www.cs.toronto.edu/~kriz/cifar.html
- ImageNet,22,000类,每类500-1000影像。
Object Detection:物体检测
经典的情况下通过bounding box确定目标位置,期初主要用于人脸检测与行人检测,数据集如
-
Caltech Pedestrian Dataset数据集,包含350,000个bounding box标签。
-
PASCAL VOC数据集, 包括20个目标超过11,000图像,超过27,000目标bounding box。其数据集图像质量好,标注完备,非常适合用来测试算法性能.网址:http://host.robots.ox.ac.uk/pascal/VOC/
-
ImageNet数据下的detection数据集,200类,400,000张图像,350,000个bounding box。
由于一些目标之间有着强烈的关系而非独立存在,在特定场景下检测某种目标是是否有意义的,因此精确的位置信息比bounding box更加重要。也就是下面所述的图像分割.
Semantic scene labeling:图像分割
这类问题需要像素级别的标签,其中个别目标很难定义,如街道和草地。数据集主要包括室内场景和室外场景的,一些数据集包括深度信息。
- SUN dataset包括908个场景类,3,819个常规目标类(person, chair, car)和语义场景类(wall, sky, floor),每类的数目具有较大的差别(这点COCO数据进行改进,保证每一类数据足够)。
other
-
Middlebury datasets,包含立体相对,多视角立体像对和光流.
-
KITTI由德国卡尔斯鲁厄理工学院(Karlsruhe Institute of Technology)和丰田芝加哥技术研究院(Toyota Technological Institute at Chicago)于2012年联合创办,是目前国际上最大的自动驾驶场景下的计算机视觉算法评测数据集。网址:http://www.cvlibs.net/datasets/kitti
-
Cityscapes,也是自动驾驶相关方面的数据集,重点关注于像素级的场景分割和实例标注。网址:https://www.cityscapes-dataset.com/
-
人脸识别数据集LFW(Labeled Faces in the Wild),网址:http://vis-www.cs.umass.edu/lfw/
参考:
COCO DataSet数据特点: http://blog.csdn.net/zziahgf/article/details/72819043
计算机视觉相关的数据集和比赛: http://www.cnblogs.com/lionsde/p/7347590.html
COCO数据集介绍:
http://blog.csdn.net/u012905422/article/details/52372755?locationNum=2&fps=1
最后
以上就是虚拟日记本最近收集整理的关于COCO数据库COCO数据库:补充阅读:参考:的全部内容,更多相关COCO数据库COCO数据库内容请搜索靠谱客的其他文章。








发表评论 取消回复