一 开发环境
作者:嘟粥yyds
时间:2023年1月9日
集成开发工具:jupyter notebook 6.5.2
集成开发环境:Python 3.10.6
第三方库:tensorflow-gpu、numpy、matplotlib.pyplot
二 三层神经网络实现
2.1 总览
从网络结构上看,如下图所示,函数的嵌套表现为网络层的前后相连,每堆叠一个(非)线性环节,网络层数增加一层。我们把输入节点????所在的层叫作输入层,每一个非线性模块的输出????????连同它的网络层参数????????和????????称为一层网络层,特别地,对于网络中间的层,叫作隐藏层,最后一层叫作输出层。这种由大量神经元模型连接形成的网络结构称为神经网络(Neural Network)。我们可以看到,神经网络并不难理解,神经网络的每层的节点数和神经网络的层数决定了神经网络的复杂度。
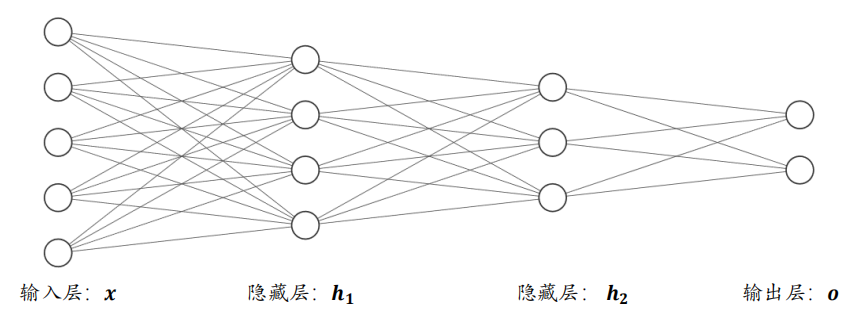
2.2 输入层到第一层信号传递
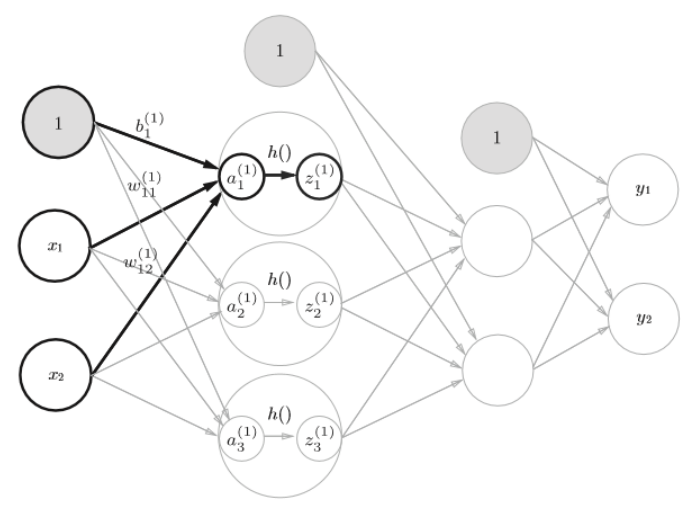
2.3 第一层到第二层的信号传递
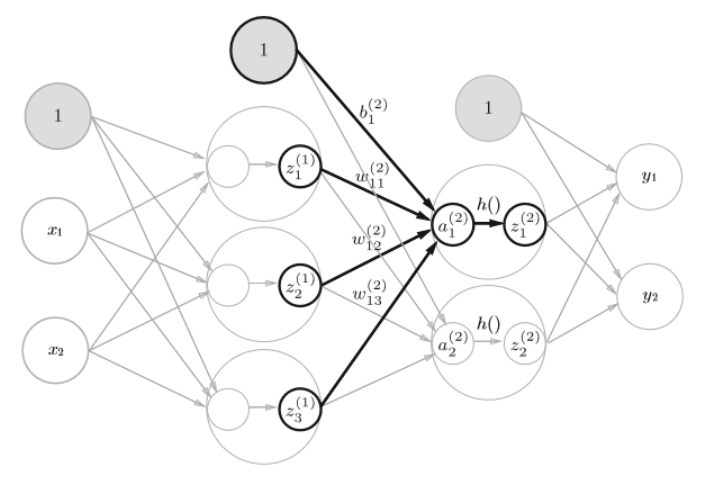
2.4 第二层到输出的信号传递
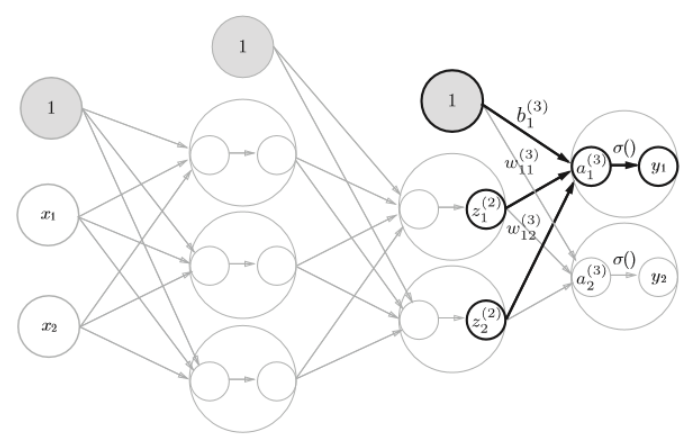
三 手写数字识别
3.1 MNIST数据集
3.1.1 MINST数据集概述
包含了 0~9 共 10 种数字的手写图片,每种数字一共有 7000 张图片,采集自不同书写风格的真实手写图片,一共 70000 张图片。其中 60000 张图片作为训练集????train(Training Set),用来训练模型,剩下 10000 张图片作为测试集????test(Test Set),用来预测或者测试,训练集和测试集共同组成了整个 MNIST 数据集。
3.1.2 MINST数据集数据
考虑到手写数字图片包含的信息比较简单,每张图片均被缩放到28 × 28的大小,同时只保留了灰度信息,如下图所示。这些图片由真人书写,包含了如字体大小、书写风格、粗细等丰富的样式,确保这些图片的分布与真实的手写数字图片的分布尽可能的接近,从而保证了模型的泛化能力。

MNIST 数据集样例图片
现在我们来看下图片的表示方法。一张图片包含了ℎ行(Height/Row),????列(Width/Column),每个位置保存了像素(Pixel)值,像素值一般使用 0~255 的整形数值来表达颜色强度信息,例如 0 表示强度最低,255 表示强度最高。
下图演示了内容为8的数字图片的矩阵内容,可以看到,图片中黑色的像素用0表示,灰度信息用0~255表示,图片中越白的像素点,对应矩阵位置中数值也就越大。
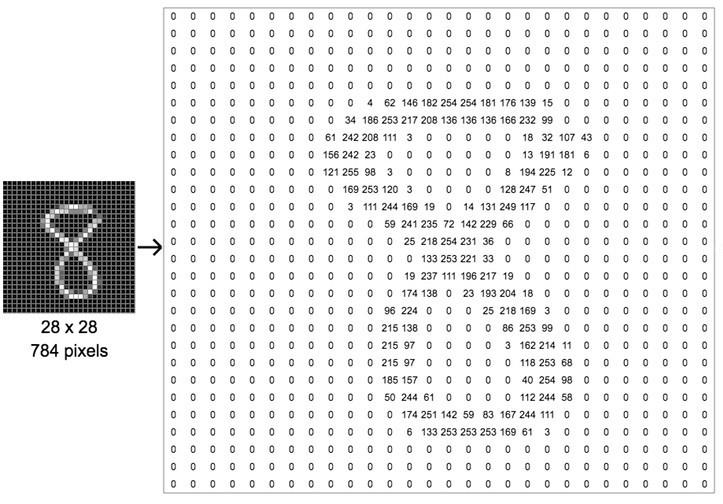
图片的表示示意图
3.2 神经网络的推理处理
输入层784个神经元(flatten=true 每张图片展开成一位数组)
输出层10个神经元(10个类别,0~9)
两个隐藏层,第一个隐藏层有256个神经元,第二个隐藏层有128个神经元,256和128可以设置成任意值
3.3 代码实现
3.3.1 模块准备
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import datasets
import numpy as np
import matplotlib.pyplot as plt3.3.1 数据准备并预处理
# 读取数据集
(x, y), (x_val, y_val) = datasets.mnist.load_data()
# 转换成浮点型张量,并映射到[-1, 1]区间
x = 2 * tf.convert_to_tensor(x, dtype=tf.float32) / 255. - 1
# 转换成整型张量
y = tf.convert_to_tensor(y, dtype=tf.int32)
# one-hot编码
y = tf.one_hot(y, depth=10)
# 改变视图 [b, 28, 28] => [b, 28*28]
x = tf.reshape(x, [-1, 28*28])3.3.2 神经网络层参数准备
# 首先创建每个非线性层的W和b张量参数
# 每层的张量都需要被优化,故使用Variable类型,并使用截断的正态分布初始化权值张量
# 偏置向量初始化为0即可
# 第一层的参数
w1 = tf.Variable(tf.random.truncated_normal([784, 256], stddev=0.1))
b1 = tf.Variable(tf.zeros([256]))
# 第二层的参数
w2 = tf.Variable(tf.random.truncated_normal([256, 128], stddev=0.1))
b2 = tf.Variable(tf.zeros(128))
# 第三层的参数
w3 = tf.Variable(tf.random.truncated_normal([128, 10], stddev=0.1))
b3 = tf.Variable(tf.zeros([10]))print(f"w1.shape = {w1.shape} b1.shape = {b1.shape}")
print(f"w2.shape = {w2.shape} b2.shape = {b2.shape}")
print(f"w3.shape = {w3.shape} b3.shape = {b3.shape}")
w1.shape = (784, 256) b1.shape = (256,) w2.shape = (256, 128) b2.shape = (128,) w3.shape = (128, 10) b3.shape = (10,)
3.3.3 训练参数设置
# 设置训练次数epochs及学习率lr
epochs = 100
lr = 0.01
# 记录每次的损失
list_loss = np.zeros([epochs])
list_epoch = np.arange(epochs)3.3.4 数据训练
for epoch in range(epochs):
with tf.GradientTape() as tape: # 构建梯度记录环境
# 第一层计算 [b, 784]@[784, 256]+[256] => [b, 256]+[256] => [b,256]+[b, 256]
h1 = x@w1 + tf.broadcast_to(b1, [x.shape[0], 256])
h1 = tf.nn.relu(h1) # 通过激活函数
# 第二层计算 [b, 256] => [b, 128]
h2 = h1@w2 + b2
h2 = tf.nn.relu(h2)
# 输出层计算 [b, 128] => [b, 10]
out = h2@w3 + b3
# 计算y与out的均方差
loss = tf.square(y - out)
loss = tf.reduce_mean(loss)
list_loss[epoch] = loss
# 自动梯度,需要求梯度的张量有[w1,b1,w2,b2,w3,b3]
grads = tape.gradient(loss, [w1,b1,w2,b2,w3,b3])
w1.assign_sub(lr * grads[0])
b1.assign_sub(lr * grads[1])
w2.assign_sub(lr * grads[2])
b2.assign_sub(lr * grads[3])
w3.assign_sub(lr * grads[4])
b3.assign_sub(lr * grads[5])3.3.5 运行结果
plt.plot(list_epoch, list_loss)
plt.title('MINST neural networks model')
plt.xlabel('Epoch')
plt.ylabel('MSE')
plt.show()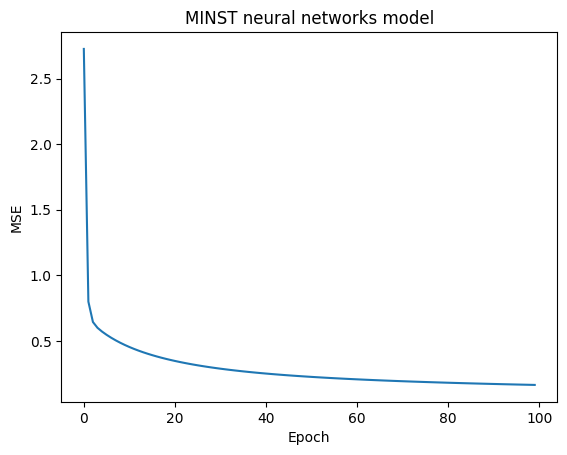
最后
以上就是留胡子睫毛膏最近收集整理的关于全连接神经网络实现MNIST手写数字识别一 开发环境二 三层神经网络实现三 手写数字识别的全部内容,更多相关全连接神经网络实现MNIST手写数字识别一内容请搜索靠谱客的其他文章。








发表评论 取消回复