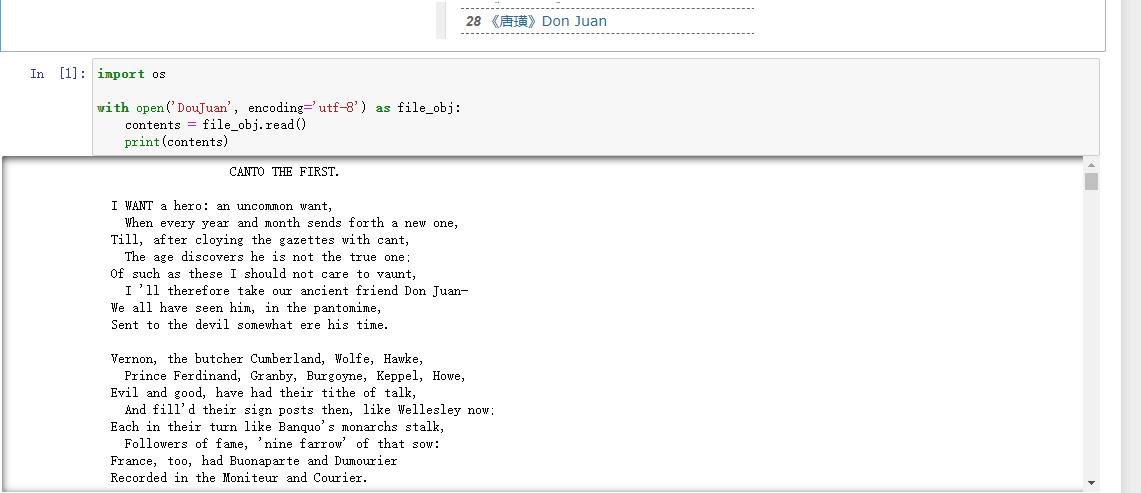
import os
with open('DouJuan', encoding='utf-8') as file_obj:
contents = file_obj.read()
print(contents)
string = contents.lower()
string = string.replace("n"," ")
# 删除字符串内除了字母与空格的字符 例如@#$%^&*()_+:<>.|}""?这些特殊符号
newstring = ""
for i in string:
if((i >= 'a' and i <='z') or i == ' '):
newstring += i
# print(newstring)
words = newstring.split(sep=' ')
#虚词数组,用于存放虚词这种没有统计意义的词,再用于过滤掉这些词
FunctionWord = [""," ","the","a","an","and","of","to","in","at","but","as","with","or"]
# print(words)
statisticsWords = ["start"]
for i in words:
if(not(i in FunctionWord)):
statisticsWords.append(i)
print(statisticsWords)

print(type(words))
# 统计单词个数并存到字典中
wordsDict = {}
for i in statisticsWords:
if(not(i in wordsDict.keys())):
wordsDict[i] = 1
else:
wordsDict[i] += 1
print(wordsDict)

# z=zip(wordsDict.values(),wordsDict.keys())
# sorted(z)
wordsDict = sorted(wordsDict.items(),key=lambda x:x[1],reverse=True)
statisticsDescirbe = ""
for i in wordsDict:
statisticsDescirbe += str(i[0]) + " : " + str(i[1]) + 'n'
print(statisticsDescirbe)

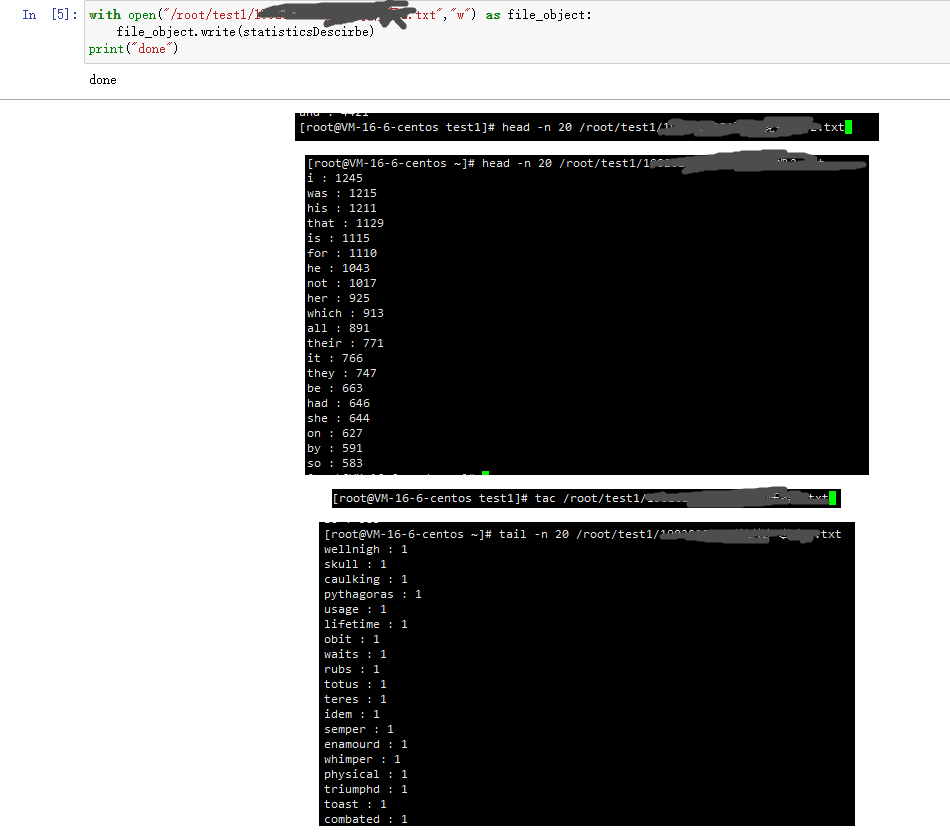
with open("/root/test1/XXXXXXXXXXXX","w") as file_object:
file_object.write(statisticsDescirbe)
print("done")
最后
以上就是现实香烟最近收集整理的关于python 统计小说词数(完整,无bug,优化版)的全部内容,更多相关python内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复