Bi-Classifier Determinacy Maximization for Unsupervised Domain Adaptation
本文提出BCDM同样使用两个分类器来进行对抗适应,区别于MCD,CDD包含了所有双分类器的预测不一致的概率,其定义为双分类器不同类预测之间的乘积之和。训练时,先最大化CDD损失更新分类器,使双分类器产生跨类分歧,促进探索多样化的输出空间;再最小化CDD损失更新特征提取器,生成判别性特征使预测结果一致且确定,将两个领域的类推到一起。
https://blog.csdn.net/sinat_39207356/article/details/113806782
General Instance Distillation for Object Detection
近年来,知识蒸馏被证明是一种有效的模型压缩方法。这种方法可以使轻量级的学生模型从较大的教师模型中获取有效知识。然而,以往的蒸馏检测方法对不同检测框架的泛化能力较弱,严重依赖于GT,忽略了实例间有价值的关系信息。因此,我们提出了一种新的基于区分性实例的提取方法,即一般实例提取(GID),该方法不考虑区分negative和positive。
本文的方法包含通用实例选择模块(GISM):充分利用基于特征、基于关系和基于响应的知识进行特征蒸馏。大量的实验结果表明,学生模型在各种检测框架下都取得了显著的AP改进,甚至优于教师模型。具体来说,在COCO数据集上,ResNet-50的RetinaNet在mAP和GID中达到39.1%,比基线的36.2%高出2.9%,甚至比ResNet-101的教师模型(AP为38.1%)要好.
https://zhuanlan.zhihu.com/p/355205031
MeGA-CDA:用于类别感知无监督域自适应目标检测的记忆引导注意力
现有的无监督域自适应目标检测方法通过反向训练实现特征对齐。虽然这些方法在性能上得到了合理的改进,但它们通常会执行与类别无关的域对齐,从而导致特性的负迁移。为了克服这一问题,本研究试图通过提出“类别感知领域适应的记忆引导注意”(MeGA-CDA),将类别信息整合到领域适应过程中。该方法包括使用类别识别器来确保学习领域不变判别特征的类别感知特征对齐。然而,由于目标样本无法获得类别信息,我们建议生成记忆引导的类别特定注意图,然后用于将特征适当地路由到相应的类别识别器。在几个基准数据集上进行了评估,结果表明该方法优于现有方法。
文章提出了一种基于类别感知的特征对齐算法,用于域自适应目标检测。具体的是通过引入类别感知判别器将类别信息整合到域对齐过程中。为了克服缺乏类别标签的问题,特别是在目标领域,我们提出了记忆引导的注意机制,它生成类别特定的注意图,将特征路由到适当的特定识别器。通过这样做,可以减轻负迁移的问题,从而得到更好的整体对齐。通过在几个基准数据集上进行评估,发现性能很好。
Self-supervised Learning of Audio-Visual Objects from Video
从视频中自我监督学习视听对象
https://zhuanlan.zhihu.com/p/191105553?utm_source=wechat_session
具体工作是使用自监督的方法训练了一个模型,能将音频和视频中说话的对象关联起来,此外还用到了光流来做跟踪。最终效果就是该模型得到的Embedding可以成功用于四个下游任务,而此前这些任务使用的是许多是手工设计的有监督的pipeline。
StarGAN v2: Diverse Image Synthesis for Multiple Domains
多个领域的多样化图像合成
https://blog.csdn.net/huitailangyz/article/details/105851778
https://zhuanlan.zhihu.com/p/147043042
研究任务是多域的图像转换。在starGAN的基础上进行了多个改进,提高模型效果。
模型结构分四部分组成。生成器输入源域图像并通过一种方式获取风格编码,生成目标域图像。风格编码有两种获得来源,一种来自mapping网络,从而随机噪声生成风格编码,而每个不同的目标域分别对应一个mapping-head;另一种来自风格编码器,由输入的目标域图像来获得对应的风格编码。判别器输入一张图像,生成各个目标域的真假图像判断。
RepVGG: Making VGG-style ConvNets Great Again
本文提出一种简单而强有力的CNN架构RepVGG,在推理阶段,它具有与VGG类似的架构,而在训练阶段,它则具有多分支架构体系,这种训练-推理解耦的架构设计源自一种称之为“重参数化(re-parameterization)”的技术
https://blog.csdn.net/weixin_42764932/article/details/112695711
我们提出了一种简单而强大的卷积神经网络结构,它具有类似VGG的推理时间体,由3x3卷积和ReLU组成,而训练时间模型具有多分支拓扑结构。这种训练时间和推理时间结构的解耦是通过一种结构再参数化技术来实现的,因此该模型被命名为RepVGG。在ImageNet上,RepVGG达到了80%以上的top-1精度,据我们所知,这是第一次使用普通模型。在nvidia1080tigpu上,RepVGG模型的运行速度比ResNet-50快83%,比ResNet-101快101%,精度更高,与EfficientNet和RegNet等最先进的模型相比,显示出良好的精度-速度折衷。
作者:Vinteuil
链接:https://www.jianshu.com/p/8e04c2728ceb
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
PaDiM: a Patch Distribution Modeling Framework for Anomaly Detection and Loc
一种面向异常检测和定位的补丁分布建模框架,用于在一个类学习设置下,同时检测和定位图像中的异常。PaDim利用预先训练的CNN进行修补,并利用多元高斯分布得到正态类的概率表示。它还利用CNN不同语义级别之间的相关性来更好的定位异常。
https://blog.csdn.net/sinat_24899403/article/details/111032279
SEED:用于场景文本识别的语义增强的编码器-解码器框架
场景文本识别是计算机视觉领域的一个研究热点,近年来,人们提出了许多基于编码器解码器框架的识别方法,这些方法可以处理透视失真和曲线形状的场景文本。然而它们仍然面临许多挑战如图像模糊、光照不均和字符不完整等。我们认为大多数编码器解码器方法是基于局部视觉特征,而没有明确的全局语义信息。本工作提出了一个语义增强的编码器解码器框架,可以识别低质量的场景文本。语义信息在编码器模块中用于监督,在解码器模块中用于初始化。特别的,先进的aster方法被集成到提议的框架中作为一个范例,大量的实验表明,该框架对低质量的文本图像具有更强的鲁棒性,并在多个基准数据集上取得了最先进的结果。
这个框架预测了一个额外的受来自一个预训练语言模型词嵌入监督的全局语义信息,利用预测的语义信息作为解码器初始化,可以提高识别精度,特别是对低质量图像。
Effectiveness of Self-Supervised Pre-Training for ASR
https://blog.csdn.net/pitaojun/article/details/108371443
我们比较了自我监督表示学习算法,既可以明确量化音频数据,也可以学习不进行量化的表示。我们发现前者更准确,因为它通过vq-wav2vec[1]构建了良好的数据词汇表,从而能够在随后的BERT训练中学习有效表示。与之前的工作不同,我们使用连接主义者时间分类(CTC)损失直接微调了预训练的BERT模型转录语音,而不是将表示输入特定任务的模型。我们还提出了直接从连续音频数据进行伯特风格的模型学习,并将原始音频的预训练与光谱特征进行比较。用avq-wav2vec词汇对10小时标记的libris演讲数据进行微调的艾伯特模型几乎与最著名的报告系统在100小时的标记数据上训练的test-clean一样好,同时在test-other上实现了25%的降低。当只使用10分钟的标记数据时,WER在test-other上是25.2,在test-clean上是16.3。这表明,自我监督可以使语音识别系统在几乎为零的转录数据上训练。
我们对语音识别的自我监督前训练方法进行了系统的比较。最有效的方法是首先用vq-wav2vec学习数据的离散词汇表,然后在这些离散单元上进行标准的BERT训练。这比直接从连续的音频数据中学习要好得多。与之前依赖于特定任务的ASR模型的工作不同,我们直接对转录语音数据的BERT模型进行微调,以作为语音识别模型。这种方法可以在测试中获得更好的准确性,而不是依赖于两个数量级较少标记数据的100小时标记数据的最佳结果。当模型仅在10分钟的数据上进行微调时,它仍然可以在test-other上获得WER 25.2,在test-clean上获得WER 16.3。
Learning Attentive Pairwise Interaction for Fine-Grained Classification
https://blog.csdn.net/wangkingj/article/details/105469692
在训练阶段,输入一对图像对到backbone中,分别提取特征,得到对应的特征向量x1,x2,然后我们得到一个mutual vector;
我们将xm与xi按通道进行点乘,即用xm查找哪个通道可能包含对比线索,然后再通过sigmoid函数,得到gate vector;
然后在gate vector的指导下进行成对的交互,交互后的向量放入softmax classifier中得到损失函数。
What Makes Training Multi-modal Classification Networks Hard?
https://zhuanlan.zhihu.com/p/137104163
多模态训练存在很多问题,比如两个特征提取网络不同时达到最佳的收敛效果,也就是一个训练的慢,一个训练的快。为了让两个网络以相同速度训练,可以通过调整参数的更新幅度,来调整网络训练的速度。根据梯度下降算法、参数的更新幅度,看上去主要受两方面影响:学习率,梯度。
核心问题:
如何知道哪个模态网络训练的快,哪个模态网络训练的慢;
知道了快慢后,如何跟据各个网络不同的训练速度,设置各个loss权重;
文章回答了这两个问题,定义了一个overfitting-to-generation-ratio来度量网络学习的质量。并通过OGR构造来一个目标函数,该目标函数的参数就是每个loss的权重参数。最后通过求解该目标函数,得到最优的权重系数。计算过程,本身也是使用了一个梯度下降算法的训练过程。
Funnel Activation for Visual Recognition
文章提出了一种概念简单但有效的图像识别激活函数,称为Funnel激活函数,它通过增加了微不足道的空间条件开销,将relu和Prelu扩展为二维激活函数。relu和prelu的形式分别为y=max(x,0)和y=max(x,px),Frelu的形式为y=max(x,T(x)),其中T(.)为二维空间条件。此外,空间条件以简单的方式实现像素级的建模能力,通过规则的卷积捕获复杂的视觉布局。通过实验证明了Frelu在视觉识别任务上有很大的改进和鲁棒性。
文章提出了一个漏斗激活特别设计的视觉任务,它可以使用像素级建模能力轻松捕捉复杂的布局。提出的方法简单有效,并与其他技术很好的兼容,为图像识别任务提供了一种新的激活方式。
Taking a Closer Look at Domain Shift: Category-Level Adversaries for Semantics Consistent Domain Adaptation
abstract
考虑了语义切分中的无监督领域自适应问题。这个策略的关键在于减少域的偏移,也就是说,强制两个域的数据分布相似。一种常见的策略是通过对抗性学习来对齐特征空间的边际分布。但是,这种全球联盟策略没有考虑到区域层面的联合分布。这种全局移动的一个可能的结果是,一些原本在源和目标之间对齐得很好的类别可能会被错误地映射,从而导致在目标领域分割的结果更差。为了解决这一问题,我们引入了类别级对抗网络,旨在增强全局对齐趋势下的局部语义一致性。我们的想法是仔细查看类别级的联合分布,并将每个类与自适应的对抗性损失对齐。具体地说,我们减少类别级对齐特征的抗辩损失权值,同时增加那些不匹配特征的抗辩力量。在此过程中,我们通过一种协同训练的方法来决定一个特征在源和目标之间的类别级对齐的程度。在GTA5→Cityscapes和syno - thia→Cityscapes这两个领域的自适应任务中,我们验证了所提出的方法在分割精度上符合目前的水平。
conclusion
这篇文章引入类级别对抗网络,旨在解决无监督域适应过程中全局特征对齐所引起的语义不一致问题。通过仔细观察分类级数据分布,CLAN根据分类级对齐的好坏自适应的对每个特征的对抗性损失进行加权。在这种精神下,每类都与适应性对抗损失相一致。我们的方法有效的防止了良好对齐的特征被纯全局分布对齐的副作用所不正确的映射。实验结果证明了CLAN算法的有效性。
- 本文提出了一种协同多模态的无监督领域自适应框架,也称为协同图像和特征自适应(SIFA)。以有效解决医学图像域迁移的问题。
- 传统无监督自适应框架通过两种方式进行迁移学习: 在图像级别将源域图像转化到接近目标域的图像,然后对网络进行微调。在特征级别进行对抗学习,使模型能够生成域不变的特征。
- 本文融合了图像和特征的两个角度进行协同性的域迁移。首先跨域变换图像的外观,将源域图像转换为目标域类似的图像,使用源域标签进行有监督训练,同时在特征级别通过对抗学习进行域迁移,促使模型生成域不变的特征。两种域迁移使用相同的权重参数,在不使用任何目标域标注的情况下进行端到端的训练,学习到两个域共有的特征。
论文的主要贡献包括以下几点:
- 提出了一种新颖的无监督域自适应框架SIFA,该框架利用图像和特征自适应来通过互补的角度解决域偏移。
- 通过在语义预测空间和重构图像空间两个方面使用鉴别器来增强特征自适应。两个紧凑空间都有助于进一步增强提取特征的域不变性。
- 验证了的SIFA在跨模态心脏结构分割挑战中的有效性。并且在性能上远远超过了最新方法。
LISTEN, ATTEND AND SPELL: A NEURAL NETWORK FOR LARGE VOCABULARY CONVERSATIONAL SPEECH RECOGNITION
本文提出了一个基于神经网络的语音识别系统,能够将语音直接转录为文字。
进步性:LAS将声学、发音和语言模型融合为一个神经模型,因此可以实现端到端。LAS只包含两部分:收听器和拼写器。收听器是一个金字塔循环网络编码器,拼写器是一个基于注意力机制的循环网络解码器。
Strong-Weak Distribution Alignment for Adaptive Object Detection
在图像分类中无监督域适应方法中,大多数是尽量使得目标域数据和源域数据完全匹配。作者认为,在目标检测任务中,由于不同的域有着不同的场景布局和目标组合,完全匹配目标域和数据域的分布将降低模型的 performance。但是,由于 low-level 局部特征匹配不会改变原有的类别语义信息,所以可以将它们进行强匹配。基于上面两个原因,作者提出了:
1、核心contribution 弱对齐模型(weak alignment model) : 使用对齐 loss 更多的强调整体相似的样本对齐,不强调整体不相似的样本对齐。
2、强域对齐:加强对齐feature map的局部感受野,如纹理、颜色等。
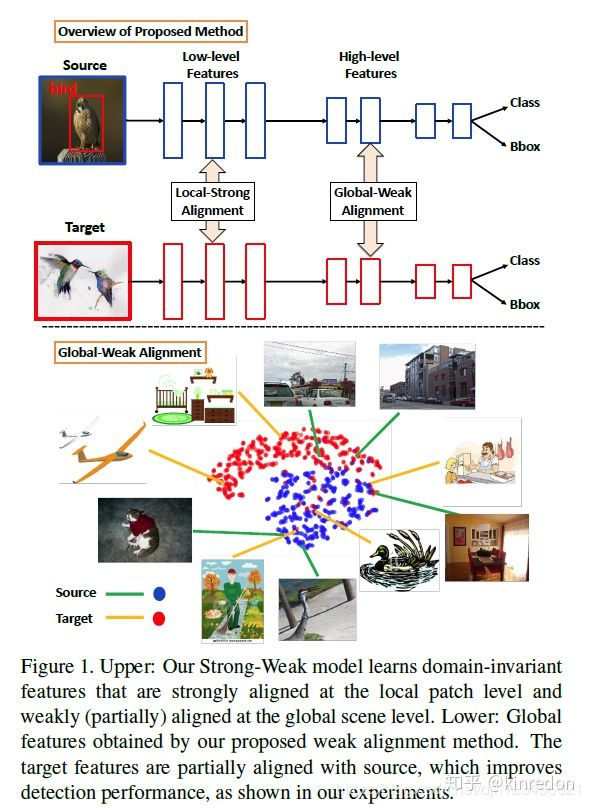
学习域不变的特征,局部特征上的强对齐,全局场景上的弱对齐。
Categorical Reparameterization with Gumbel-Softmax
分类变量是表示离散结构的自然选择。然而随着神经网络无法对样本进行反向传播,很少使用分类潜变量。
在这项工作中,文章提出了一个有效的梯度估计器,使用一个新的Gumbel-softmax分布的可微样本代替分类分布的不可微样本。这种分布的基本性质是它可以顺利的退火成一个分类分布。
最后证明了提出的估计器在有分类潜变量的结构化输出预测和无监督生成建模任务上优于最先进的梯度估计器,并使半监督分类的速度大大提高。
Speech-driven Facial Animation using Cascaded
GANs for Learning of Motion and Texture
问题:当前最先进的方法无法从未知面孔上的任何语音生成逼真的动画,这是因为它们对不同的面部特征,语言和口音的概括性很差,其中一些失败可归因于端到端学习语音和视频的多种形式之间的复杂关系。
方法:提出一个新的策略来分割问题,并分别学习运动和纹理。首先,训练一个GAN网络,利用深度语音特征来学习典型landmark中的嘴唇运动,并诱导眨眼,然后将运动转移到特定人脸上。接下来,使用另一个基于GAN的纹理生成器网络来生成与特定人的landmark上的运动相对应的高保真人脸。使用元学习来使纹理生成器GAN更加灵活,以适应推理过程中未知对象的面部特征。
StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation
为了处理多个域之间进行图片变换的问题,starGAN被提出。他可以使用单个模型进行多个域之间的图像转换。
贡献
提出一个starGAN,只使用一个生成器和鉴别器来学习多个域之间的映射,有效的训练所有域的图像。
展示了如何成功学习多个数据集之间的多域图像转换,利用mask vector使starGAN可以控制所有可用的域标签。
提供定性定量实验显示其优越性。
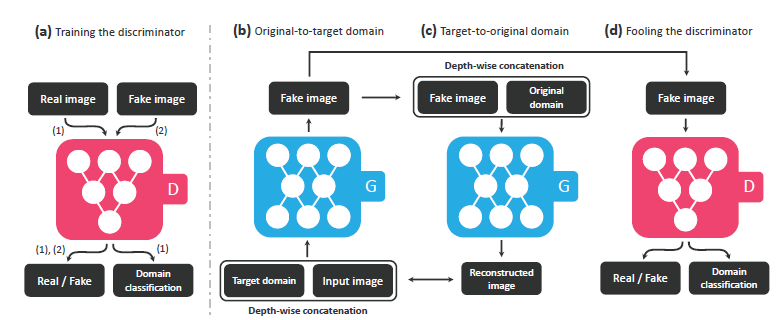
由两个模块构成,判别器学习区分真假图像,并将真实图像分类到相应的域;生成器将图像和目标域标签作为输入,生成假图像。目标域标签在空间上复制并与输入图像连接;生成器在原始域标签中从假图像中构造原图像;生成器试图生成无法区分的图像。
Towards Universal Object Detection by Domain Attention
文章提出了一个通用的目标检测系统,适用于不同图像领域而不需要该领域的先验知识。通过引入一个新的适应层(基于SE和新的域注意力机制)。在所提出的通用检测器中,所有参数和计算都在领域之间共享,并且单个网络始终处理所有领域。
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
文章提出了一个叫做bert的语言表示模型,它用transformer的双向编码器表示,通过在所有层的上下文联合调节来预训练深层双向表示。因此,预训练的bert可以添加一个额外的输出层进行微调,可以在广泛的任务上产生目前最好的效果.
与近年来提出的语言模型不一样的地方在于,bert不再仅仅是只关注一个词前文或后文的信息,而是整个模型的所有层都去关注其整个上下文的语境信息。实验结果表明,使用预训练过的bert模型,仅仅在后面在包一层输出层,并对其进行微调训练,就可以取得不错的结果。
REDUCING TRANSFORMER DEPTH ON DEMAND WITH STRUCTURED DROPOUT论文阅读
过参数化网络虽然在很多领域取得很好的效果,但是这些模型计算量大,容易出现过拟合。文章研究了结构化dropout方法layer dropout。它在训练期间具有正则化的效果,并允许在推理阶段进行高效的修剪。
结构化dropout是神经网络在预测时有更强的鲁棒性,文章将重点放在结构是层的设置上,以实现对任何所需深度的浅层和高效模型的修剪。在各种文本生成和预训练任务中,层dropout可以实现并稳定深度更深的网络的训练,同时允许提取性能良好的不同深度的模型。
Uninformed Students: Student–Teacher Anomaly Detection
with Discriminative Latent Embeddings论文阅读
提出一种新的框架来解决自然图像中无监督异常分割的挑战性问题。异常分数是由学生网络集合的预测方差和回归误差得出的。这些学生网络集合针对描述性教师网络中的嵌入式向量进行训练。集成训练可以在无异常的训练数据上进行端到端训练,不需要对数据进行预先注释。该方法可以很容易的扩展到检测多个尺度的异常。
- 我们提出了一种新的基于师生学习的无监督异常检测框架。来自预先训练过的教师网络的本地描述符可以作为学生集合的替代标签。我们的模型可以在大的未标记图像数据集上进行端到端训练,并利用所有可用的训练数据。
- 我们引入基于学生预测方差和回归误差的评分函数,以获得密集异常图,用于分割自然图像中的异常区域。我们描述了如何通过适应学生和教师的接受域来扩展我们的方法在多个尺度上进行异常分割。
- 我们在三个真实的计算机视觉数据集上演示了最先进的性能。我们将我们的方法与一些直接适合教师特征分布的浅层机器学习分类器和深层生成模型进行比较。我们也比较了它与最近介绍的基于深度学习的方法未被允许的异常分割。
最后
以上就是无聊唇膏最近收集整理的关于论文阅读梗概的全部内容,更多相关论文阅读梗概内容请搜索靠谱客的其他文章。








发表评论 取消回复