文章目录
- 前言
- 一、Introduction
- 二、Related Works
- One-stage Imbalance Learning
- Two-stage Imbalance Learning
- 三、Approach
- Distribution Alignment
- Adaptive Calibration Function
- Alignment with Generalized Re-weighting
- 总结
前言
论文链接: https://arxiv.org/pdf/2103.16370.pdf.
尽管深度神经网络最近取得了成功,但在视觉识别任务中如何有效地对长尾类分布进行建模仍然具有挑战性。为了解决这个问题,首先通过消融研究来研究两阶段学习框架的性能瓶颈。基于这一发现,作者提出了一种面向长尾视觉识别的统一分布对齐策略。具体地说,开发了一个自适应校准功能,使能够调整每个数据点的分类分数。然后,在两阶段学习中引入了一种广义的重权重方法来平衡类优先级,为视觉识别任务中的不同场景提供了灵活统一的解决方案。通过对图像分类、语义分割、目标检测和实例分割四个任务的大量实验来验证我们的方法。通过一个简单而统一的框架在所有四个识别任务中实现了最先进的结果。
一、Introduction
虽然深卷积网络在许多视觉任务中取得了巨大的成功,但它通常需要为每个视觉类别提供大量的训练样本。更重要的是,以前的研究主要集中于从平衡的数据集中学习,其中不同的对象类大致均匀分布。然而,对于大规模的视觉识别任务,部分原因是自然对象类的分布不均匀和标注成本的变化,通常从具有长尾类标签分布的数据集学习。在这样的场景中,每个类的训练实例数量差别很大,从尾类的一个例子到头部类的成百上千个例子
视觉数据固有的长尾特性给野外的识别带来了许多挑战,因为深度网络模型必须同时处理头部和中等大小类之间的不平衡注释,以及尾部类中的小样本学习。一个原始的学习模型将在很大程度上由这几个头部类主导,而它的性能对于其他许多尾部类则会大大降低。
重新平衡数据分布的早期工作集中于学习一阶段模型,由于其策略缺乏原则性设计,这些模型取得的成功有限。最近的努力旨在通过解耦表示学习和分类器头部学习来改善长尾预测。然而,这种两阶段策略通常依赖于启发式设计来调整最初学习的分类器头部的决策边界,这在实践中往往需要繁琐的超参数调整。这严重限制了其解决不平衡的训练数据分布和平衡的评估度量之间的不匹配的能力。
在这项工作中,首先对两阶段学习策略进行了消融分析,以揭示其性能瓶颈。具体地说,研究使用平衡的数据集来重新训练分类器头部,同时保持第一阶段的表示不变,从而估计出“理想的”分类精度。有趣的是,如图6所示,我们发现这一理想性能与基线网络之间存在很大差距,这表明数据不平衡的第一阶段学习提供了很好的表征,但由于决策边界的偏差,第二阶段的学习还有很大的改进空间。
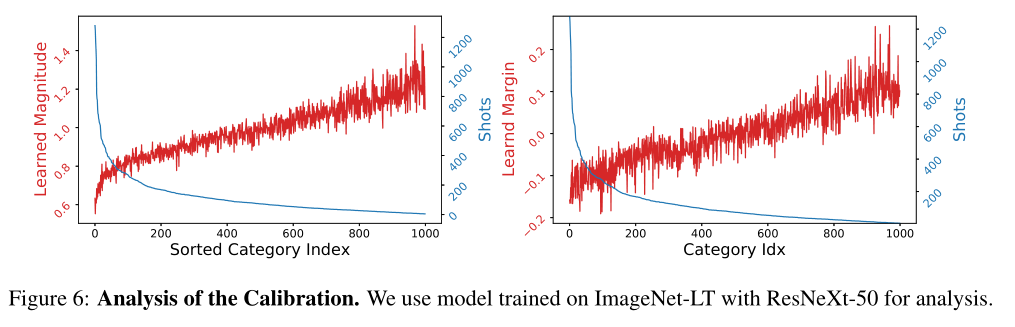
作者开发了一个用于校准分类分数的轻量级分布对齐模块,该模块由两个主要部分组成。在第一部分中,引入了一个自适应校准功能,它为类分数配备了依赖于输入的、可学习的幅度和差值。这使能够为每个数据点实现灵活、可靠的分布对齐。第二个组件通过对参考类分布采用通用的重新加权设计,显式地合并了平衡类先验,这提供了一个统一的策略来应对不同视觉识别任务中标签不平衡的不同场景。
- 对长尾识别的性能瓶颈进行了实证研究,揭示了决策边界偏向造成的关键差距。
- 本文提出了一种简单有效的分布对齐策略,该策略采用广义的重加权方法,可以很容易地对各种长尾识别任务进行优化,而不会出现繁琐的设置
二、Related Works
One-stage Imbalance Learning
为了缓解长尾类分布在视觉识别中的不利影响,以往的工作已经广泛研究了一步法,这些方法要么利用再平衡的思想,要么探索头部类别的知识转移。基于重采样的方法的基本思想是在训练过程中对少数类别进行过采样或对频繁类别进行欠采样。类感知采样提出以相等的概率选择每个类别的样本,这在视觉任务中被广泛使用。重复因子抽样是一种对尾部类别进行重复抽样的平滑抽样方法,在实例分割中显示了其有效性。此外,建议在每个训练周期之后提高低性能类别的采样率,并平衡低特权类别的特征学习。
另一种策略是在训练中重新加权损失函数。类别水平方法通常使用与样本分布相关的类别特定系数来重新加权标准损失。样本级方法试图为不平衡学习引入更精细的损失控制。其他工作旨在通过转移来自头部类的知识来增强尾部类别的表示或分类器头部。然而,这些方法需要设计特定于任务的网络模块或结构,这通常很难推广到不同的视觉任务。
Two-stage Imbalance Learning
最近的努力旨在通过解耦表示和分类器头部的学习来提高长尾预测。Disouple提出了一种实例平衡采样方案,该方案在适当地重新平衡分类器头部后,生成了更多的泛化表示,并获得了很强的性能。文献[42,43,24]也采用了类似的思想,为长尾目标检测任务开发了有效的策略。[30,39]通过引入后处理来调整预测得分,改进了两阶段思想。然而,这样的两阶段策略通常依赖于启发式设计来调整初始学习的分类器的决策边界,并且在实践中需要繁琐的超参数调整。
三、Approach
目标是解决大规模长尾视觉识别的问题,它的训练数据通常具有大量的类和严重的类不平衡。为此,采用了两阶段学习框架,首先从不平衡的数据中学习特征表示和分类器头部,然后是调整分类分数的校准阶段。受现有两阶段方法的开拓性研究的启发,提出了一种原则性的校准方法,该方法将模型预测与有利于平衡评估度量的参考类别分布相一致。
首先研究在不平衡数据集上学习的特征表示是否对平衡性能有限制。为此,从学习不平衡ImageNet-LT训练集上的特征提取器开始,使用几种重新平衡策略(例如,实例平衡、类平衡或平方根采样)。然后,保持表示不变,并用理想的平衡ImageNet训练集(不包括ImageNet-LT Val集)重新训练分类器头部。结果显示在图2的左面板中,这表明第一阶段产生了强大的特征表示,这可能会导致较大的性能增益,而基于实例的采样获得了更好的整体结果。
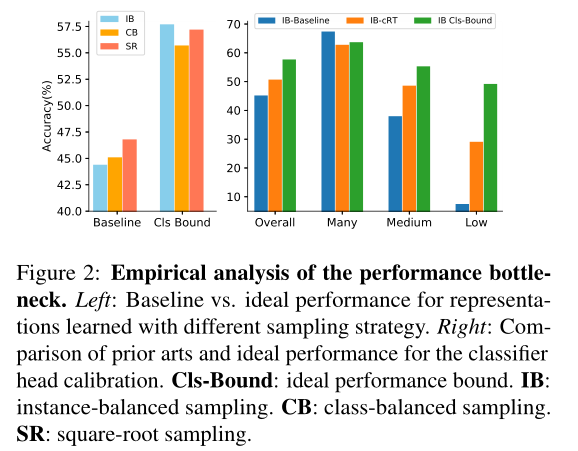
此外,对最近的解耦方法(例如CRT[20])与上述理想的分类器头部学习的有效性进行了实证研究。图2的右侧面板显示,现有方法与上限之间仍有很大的性能差距。这些实验结果表明,特征空间中有偏的决策边界似乎是现有长尾方法的性能瓶颈。因此,解决这个问题的更好的策略将进一步改进长尾分类的两阶段学习。
Distribution Alignment
为了解决上述问题,引入统一的分布对齐策略,通过将分类器输出与有利于平衡预测的类的参考分布进行匹配来校准分类器输出。在这项工作中,对所有视觉识别任务采用了两阶段学习方案,包括联合学习阶段和分布校准阶段,如下所示。
1)联合学习阶段。在第一阶段,特征提取器
f
(
⋅
)
f(·)
f(⋅)和原始分类器头部(记为
h
o
(
⋅
)
h_{o}(·)
ho(⋅))基于不平衡的
D
t
r
D_{tr}
Dtr使用实例平衡策略进行联合学习,其中原始
h
o
(
⋅
)
h_{o}(·)
ho(⋅)由于数据分布的不平衡而严重偏向。
2)分布校准阶段。对于第二阶段,
f
(
⋅
)
f(·)
f(⋅)的参数被冻结,我们只关注分类器头部来调整决策边界。为此,我们引入了自适应校准函数和具有广义重新加权的分布对齐策略校对类别分数。
Adaptive Calibration Function
为了在第二阶段学习分类器头部
h
(
⋅
)
h(·)
h(⋅),我们提出了一种自适应校正策略,该策略以依赖于输入的方式融合原始分类器头部
h
o
(
⋅
)
h_{o}(·)
ho(⋅)(
h
o
(
⋅
)
h_{o}(·)
ho(⋅)的参数被冻结)和学习的类先验。如下所示,与以前的工作(例如CRT[20])不同,我们的设计不需要从头开始重新训练分类器头部,并且具有更少的自由参数。这使我们能够减少Tail类别有限的训练数据带来的不利影响。此外,我们还引入了一种灵活的融合机制,能够根据输入特征控制校准的大小。
具体地说,将
h
o
(
⋅
)
h_{o}(·)
ho(⋅)中的类分数表示为
z
o
=
[
z
o
1
,
⋅
⋅
⋅
,
z
o
K
]
z_{o}=[z_{o}^1,···,z_{o}^ K]
zo=[zo1,⋅⋅⋅,zoK],我们首先引入特定于类别的线性变换来调整分数,如下所示:
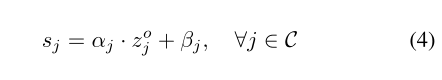
其中,
α
j
α_{j}
αj和
β
j
β_{j}
βj是每个类别的校准参数,这些参数将从数据中学习。如上所述,然后我们定义置信度分数函数
σ
(
x
)
σ(x)
σ(x),以自适应地组合原始和转换后的类别分数:
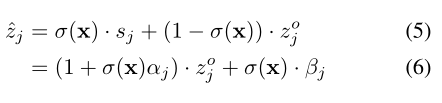
其中置信度分数具有
g
(
v
T
x
)
g(v^{T}x)
g(vTx)的形式,其被实现为线性层,后面跟随着非线性激活函数(例如,Sigmoid函数)。置信度σ(X)控制对于特定输入x需要多少校准。给定校准的类别分数,我们最后使用Softmax函数定义模型的预测分布:
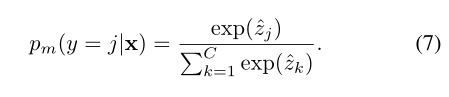
Alignment with Generalized Re-weighting
在给定训练数据集
D
t
r
=
{
(
x
i
,
y
i
)
}
i
=
1
N
D_{tr}=left {(x_{i},y_{i})right }^{N}_{i=1}
Dtr={(xi,yi)}i=1N的情况下,我们引入了一种基于模型预测
P
m
(
⋅
)
P_{m}(·)
Pm(⋅)与有利于均衡预测的类的参考分布之间的分布对齐的校准策略。
形式上,将参考分布表示为
P
r
(
y
∣
x
)
P_{r}(y|x)
Pr(y∣x),我们的目标是最小化
P
r
(
y
∣
x
)
P_{r}(y|x)
Pr(y∣x)和模型预测
P
m
(
y
∣
x
)
P_{m}(y|x)
Pm(y∣x)之间的预期KL散度,如下所示:
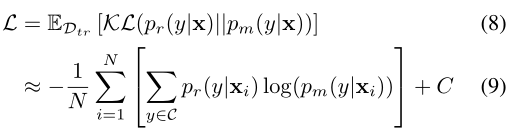
动态重加权。个人感觉这个东西影响不大。
总结
感觉这个方法从头到尾人工的干预太多了吧。先训练一个原始的模型,然后对原始的模型的输出进行校正分类。最后这个对KL散度的优化感觉不错。但是那个动态重加权有点硬加工作量的意思,个人感觉效果不大。这篇论文给我的感觉就是,通过提供人工干预的先验信息来取得一个好的效果。
最后
以上就是凶狠小懒猪最近收集整理的关于论文阅读:CVPR2021 | Distribution Alignment: A Unified Framework for Long-tail Visual Recognition前言一、Introduction二、Related Works三、Approach总结的全部内容,更多相关论文阅读:CVPR2021内容请搜索靠谱客的其他文章。








发表评论 取消回复