什么是支持向量机?
支持向量机,其英文名为support vector machine,一般简称SVM,通俗来讲,它是一种二类分类模型,其基本模型定义为特征空间上的间隔最大的线性分类器,其学习策略便是间隔最大化,最终可转化为一个凸二次规划问题的求解。SVM有很多实现,但是本篇文章只关注其中最流行的一种实现,即序列最小优化(Sequential Minimal Optimization,SMO)算法。
线性可分
对于二维空间来说,我们可以找到一条线,将两个不同类别的样本划分开来,我们就说这个样本集是线性可分的,如下图所示。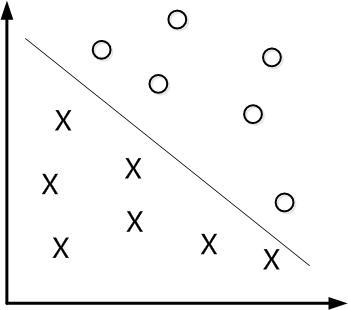
分隔超平面,支持向量与SVM
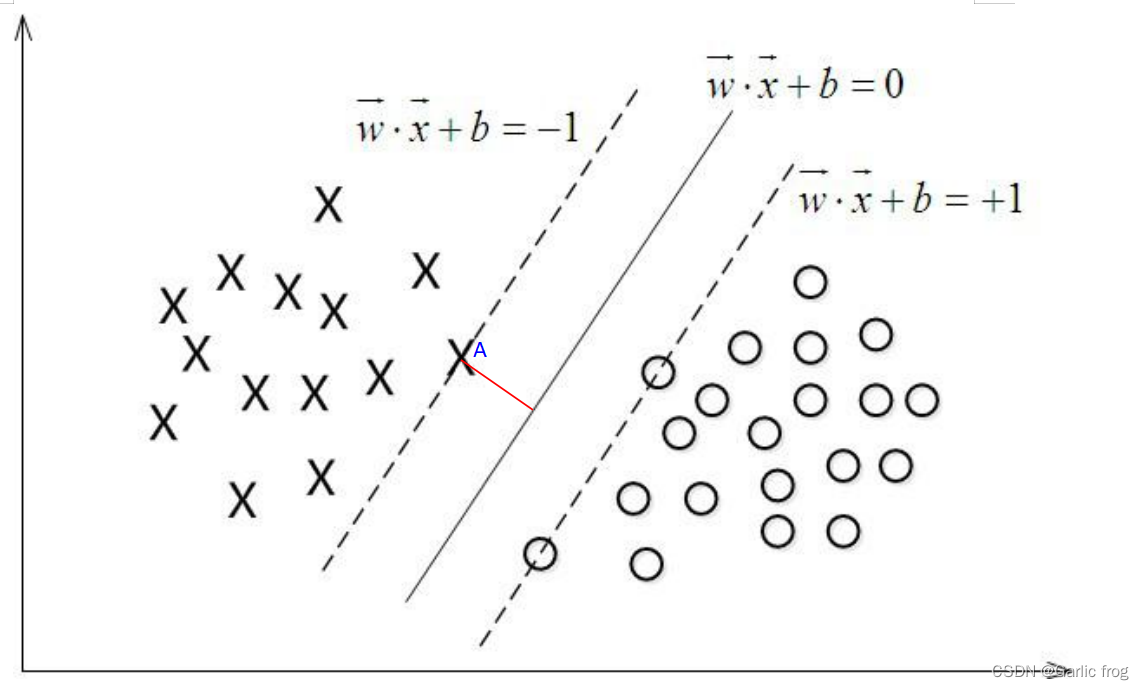
下图中有一个二维平面,平面上有两种不同的数据,分别用圈和叉表示。由于这些数据是线性可分的,所以可以用一条直线将这两类数据分开,而这条直线就叫做一个"分隔超平面",当然如果给定一个三维空间那么分割数据点的就是一个平面,因此给定一个n维空间,则其则需要n-1维的某某对象来进行分割,那么该某某对象就被叫做”超平面“。
而由上图我们也许会想到这个直线不这么画行不行呢?歪一点貌似也可以将不同数据点分割到两边,事实确实如此,所以我们希望找到离分隔超平面最近的点,确保它离这个分隔超平面尽可能远,其中点到分隔超平面的距离就被称为"间隔",我们希望间隔尽可能大,这是因为如果我们犯错或者在有限数据集上训练分类器的话,我们希望分类器尽可能健壮。
而其中离超平面最近的那些点则被称作为"支持向量"。
理解SVM,咱们必须先弄清楚一个概念:线性分类器。
给定一些数据点,它们分别属于两个不同的类,现在要找到一个线性分类器把这些数据分成两类。如果用x表示数据点,用y表示类别(y可以取1或者-1,分别代表两个不同的类),一个线性分类器的学习目标便是要在n维的数据空间中找到一个超平面(hyper plane),这个超平面的方程可以表示为(w 是垂直于超平面的一个向量,定义为法向量,而中的T代表转置):
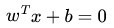
可能有读者对类别取1或-1有疑问,事实上,这个1或-1的分类标准起源于logistic回归。
我们尝试把logistic回归做个变形。首先,将使用的结果标签y = 0和y = 1替换为y = -1,y = 1,然后将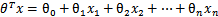 (
(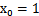 )中的
)中的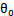 替换为b,最后将
替换为b,最后将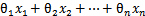 替换为(即
替换为(即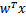 )。如此,则有了
)。如此,则有了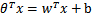 。也就是说除了y由y=0变为y=-1外,线性分类函数跟logistic回归的形式化表示
。也就是说除了y由y=0变为y=-1外,线性分类函数跟logistic回归的形式化表示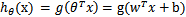 没区别。
没区别。
进一步,可以将假设函数中的g(z)做一个简化,将其简单映射到y=-1和y=1上。映射关系如下:
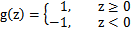
寻找最大间隔
上面我们谈到我们希望找到一个超平面距离支持向量尽可能的远,这个距离就叫做间隔,那么我们如何找到这个最大间隔呢?
我们看看下图其中分隔超平面的形式可以写成![]() ,要计算A到分隔超平面的距离,就必须给出点到分隔面的法线或垂线的长度该值为
,要计算A到分隔超平面的距离,就必须给出点到分隔面的法线或垂线的长度该值为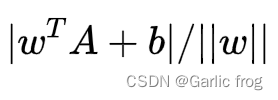
这里的常数b类似与logistic回归中的截距Wo。
最大化间隔的目标就是找出分类器定义中的w和b。为此,我们必须找到具有最小间隔的数据点,而这些数据点也就是前面提到的支持向量。一旦找到具有最小间隔的数据点,我们就需要对该间隔最大化。这就可以写作:
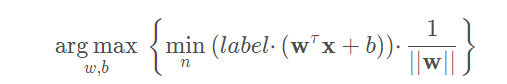
直接求解上述问题相当困难,所以我们将它转换成为另一种更容易求解的形式。我们通过引入拉格朗日乘子将目标函数写成: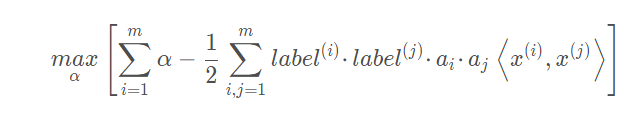
约束条件为:
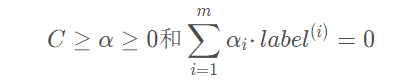
其中常数C 用于控制 “最大化间隔” 和 “保证大部分点的函数间隔小于1.0” 这两个目标的权重。在优化算法的实现代码中,常数C 是一个参数,因此可以通过调节该参数得到不同的结果。一旦求出了所有的 α,那么分隔超平面就可以通过这些 α 来表达。
注:要理解上述公式还需要大量的知识,如果你有兴趣我建议你去查阅相关教材,获得公式推到细节,再次不多赘述。
SVM应用的一般框架
收集数据:可以使用任何方法
准备数据:需要数值型数据
分析数据:有助于可视化分隔超平面
训练算法:SVM的大部分时间都源自训练,该过程主要实现两个参数的调优
测试算法:十分简单的过程就可以实现
使用算法:几乎所有分类问题都可以使用SVM,值得一提的是,SVM本身是一个二分类器,对多类问题应用SVM需要对代码做一些修改
优点:泛化错误率低,计算开销不大,结果易解释。
缺点:对参数调节和核函数的选择敏感,原始分类器不加修改仅适用于处理二类问题。适用数据类型:数值型和标称型数据SMO算法实现
数据集
依旧使用logistic回归那篇文章的数据但是将其中0改为-1

代码实现:
from time import sleep
import matplotlib.pyplot as plt
import numpy as np
import random
import types
def loadDataSet(fileName):
dataMat = []; labelMat = []
fr = open(fileName)
for line in fr.readlines(): #逐行读取,滤除空格等
lineArr = line.strip().split('t')
dataMat.append([float(lineArr[0]), float(lineArr[1])]) #添加数据
labelMat.append(float(lineArr[2])) #添加标签
return dataMat,labelMat
def selectJrand(i, m):
j = i #选择一个不等于i的j
while (j == i):
j = int(random.uniform(0, m))
return j
def clipAlpha(aj,H,L):
if aj > H:
aj = H
if L > aj:
aj = L
return aj
def smoSimple(dataMatIn, classLabels, C, toler, maxIter):
#转换为numpy的mat存储
dataMatrix = np.mat(dataMatIn); labelMat = np.mat(classLabels).transpose()
#初始化b参数,统计dataMatrix的维度
b = 0; m,n = np.shape(dataMatrix)
#初始化alpha参数,设为0
alphas = np.mat(np.zeros((m,1)))
#初始化迭代次数
iter_num = 0
#最多迭代matIter次
while (iter_num < maxIter):
alphaPairsChanged = 0
for i in range(m):
#步骤1:计算误差Ei
fXi = float(np.multiply(alphas,labelMat).T*(dataMatrix*dataMatrix[i,:].T)) + b
Ei = fXi - float(labelMat[i])
#优化alpha,更设定一定的容错率。
if ((labelMat[i]*Ei < -toler) and (alphas[i] < C)) or ((labelMat[i]*Ei > toler) and (alphas[i] > 0)):
#随机选择另一个与alpha_i成对优化的alpha_j
j = selectJrand(i,m)
#步骤1:计算误差Ej
fXj = float(np.multiply(alphas,labelMat).T*(dataMatrix*dataMatrix[j,:].T)) + b
Ej = fXj - float(labelMat[j])
#保存更新前的aplpha值,使用深拷贝
alphaIold = alphas[i].copy(); alphaJold = alphas[j].copy();
#步骤2:计算上下界L和H
if (labelMat[i] != labelMat[j]):
L = max(0, alphas[j] - alphas[i])
H = min(C, C + alphas[j] - alphas[i])
else:
L = max(0, alphas[j] + alphas[i] - C)
H = min(C, alphas[j] + alphas[i])
if L==H: print("L==H"); continue
#步骤3:计算eta
eta = 2.0 * dataMatrix[i,:]*dataMatrix[j,:].T - dataMatrix[i,:]*dataMatrix[i,:].T - dataMatrix[j,:]*dataMatrix[j,:].T
if eta >= 0: print("eta>=0"); continue
#步骤4:更新alpha_j
alphas[j] -= labelMat[j]*(Ei - Ej)/eta
#步骤5:修剪alpha_j
alphas[j] = clipAlpha(alphas[j],H,L)
if (abs(alphas[j] - alphaJold) < 0.00001): print("alpha_j变化太小"); continue
#步骤6:更新alpha_i
alphas[i] += labelMat[j]*labelMat[i]*(alphaJold - alphas[j])
#步骤7:更新b_1和b_2
b1 = b - Ei- labelMat[i]*(alphas[i]-alphaIold)*dataMatrix[i,:]*dataMatrix[i,:].T - labelMat[j]*(alphas[j]-alphaJold)*dataMatrix[i,:]*dataMatrix[j,:].T
b2 = b - Ej- labelMat[i]*(alphas[i]-alphaIold)*dataMatrix[i,:]*dataMatrix[j,:].T - labelMat[j]*(alphas[j]-alphaJold)*dataMatrix[j,:]*dataMatrix[j,:].T
#步骤8:根据b_1和b_2更新b
if (0 < alphas[i]) and (C > alphas[i]): b = b1
elif (0 < alphas[j]) and (C > alphas[j]): b = b2
else: b = (b1 + b2)/2.0
#统计优化次数
alphaPairsChanged += 1
#打印统计信息
print("第%d次迭代 样本:%d, alpha优化次数:%d" % (iter_num,i,alphaPairsChanged))
#更新迭代次数
if (alphaPairsChanged == 0): iter_num += 1
else: iter_num = 0
print("迭代次数: %d" % iter_num)
return b,alphas
def showClassifer(dataMat, w, b):
#绘制样本点
data_plus = [] #正样本
data_minus = [] #负样本
for i in range(len(dataMat)):
if labelMat[i] > 0:
data_plus.append(dataMat[i])
else:
data_minus.append(dataMat[i])
data_plus_np = np.array(data_plus) #转换为numpy矩阵
data_minus_np = np.array(data_minus) #转换为numpy矩阵
plt.scatter(np.transpose(data_plus_np)[0], np.transpose(data_plus_np)[1], s=30, alpha=0.7) #正样本散点图
plt.scatter(np.transpose(data_minus_np)[0], np.transpose(data_minus_np)[1], s=30, alpha=0.7) #负样本散点图
#绘制直线
x1 = max(dataMat)[0]
x2 = min(dataMat)[0]
a1, a2 = w
b = float(b)
a1 = float(a1[0])
a2 = float(a2[0])
y1, y2 = (-b- a1*x1)/a2, (-b - a1*x2)/a2
plt.plot([x1, x2], [y1, y2])
#找出支持向量点
for i, alpha in enumerate(alphas):
if abs(alpha) > 0:
x, y = dataMat[i]
plt.scatter([x], [y], s=150, c='none', alpha=0.7, linewidth=1.5, edgecolor='red')
plt.show()
def get_w(dataMat, labelMat, alphas):
alphas, dataMat, labelMat = np.array(alphas), np.array(dataMat), np.array(labelMat)
w = np.dot((np.tile(labelMat.reshape(1, -1).T, (1, 2)) * dataMat).T, alphas)
return w.tolist()
if __name__ == '__main__':
dataMat, labelMat = loadDataSet('C:/Users/Administrator/Desktop/testSet.txt')
b,alphas = smoSimple(dataMat, labelMat, 0.6, 0.001, 40)
w = get_w(dataMat, labelMat, alphas)
showClassifer(dataMat, w, b)结果展示
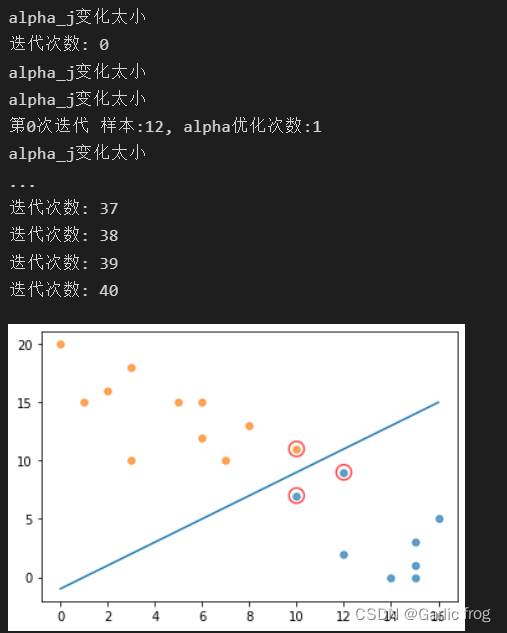
总结
SVM理解起来还是十分费力的,其中涉及诸多数学公式有些都不记得了,所以我自己也没有搞清楚那些公式的推导到底是怎样的,还是需要好好琢磨一番。
最后
以上就是感动山水最近收集整理的关于支持向量机(Support Vector Machine)什么是支持向量机?线性可分分隔超平面,支持向量与SVM寻找最大间隔SVM应用的一般框架 SMO算法实现 总结的全部内容,更多相关支持向量机(Support内容请搜索靠谱客的其他文章。








发表评论 取消回复