抽样方法分为非概率抽样和概率抽样两种,非概率抽样主要按照操作者的主观经验进行判断,本文主要探讨概率抽样。
1、简单随机抽样
按照等概率原则从总体随机抽取n个样本。
适用场景:所有样本个体都是等概率分布(均匀)的。
按照适用的场景,随机抽样又分为有放回抽样和无放回的抽样,有放回抽样可参考《python中Numpy的choice用法——有放回、无放回抽样》。以下为无放回的抽样案例,得到的是不重复的样本集。
#简单随机抽样,整体10000个样本
import random
import numpy as np
import pandas as pd
data=np.loadtxt('data3.txt')
len(data)
data_sample=random.sample(data.tolist(),2000) #随机抽取2000个样本,sample函数,array必须转化为list
len(data_sample)输出:
10000
2000从10000个样本中随机抽取2000个样本。
2、等距抽样
将总体的每个样本按照顺序编号,然后计算出抽样间隔,在按照固定抽样间隔抽取样本。
缺陷:总体样本的分布呈现明显的分布规律时容易产生误差,例如增减趋势、周期性规律。
适用场景:个体分布均匀或呈现明显的均匀分布规律,无明显趋势或周期性规律的数据。
#等距抽样,整体10000个样本
data=np.loadtxt('data3.txt')
len(data)
sample_count=2000 #指定样本数量
record_count=data.shape[0]#原数据样本量
width=int(record_count/sample_count)#计算抽样间距
data_sample=[]
for i in range(record_count-1):
if i%width==0:
data_sample.append(data[i])
len(data_sample)输出:
10000
20003、分层抽样
将所有个体样本按照某种特征划分为几个类别,然后从每个类别中适用随机抽样或等距抽样的方法选择个体组成样本。
优势:能明显降低抽样误差,并且便于针对不同类别的数据样本进行单独研究,
适用场景:带有分类逻辑的属性、标签等特征的数据。
#分层抽样,整体1000个样本
data=np.loadtxt('data2.txt')
len(data)
sample_count_per=200 #定义每层的抽样数量
label_data_unique=np.unique(data[:,-1]) #定义分层值域(标签类别)
sample_list_per=[] #存放临时分层数据
sample_data=[] #存放最终抽样数据
sample_dict={} #显示各层样本数量
for label_data in label_data_unique: #遍历分层标签
for data_one in data: #遍历每个样本
if data_one[-1]==label_data: #如果数据最后一列等于标签
sample_list_per.append(data_one)
each_sample_data=random.sample(sample_list_per,sample_count_per) #对每层数据抽取200个样本
sample_data.extend(each_sample_data) #将抽样数据追加到总体样本集中
sample_dict[label_data]=len(each_sample_data) #各类别样本数量
sample_dict输出:
1000
{0.0: 200, 1.0: 200}4、整群抽样
将所有样本分为几个小群体集,然后随机抽样几个小群体集来代表总体。该操作方法在于该方法抽取的是小群体集,而不是每个数据个体本身。
缺陷:小群体集的划分,抽样误差大。
适用场景:适用于小群体集的特征差异比较小,并且对划分小群体集有更高要求。
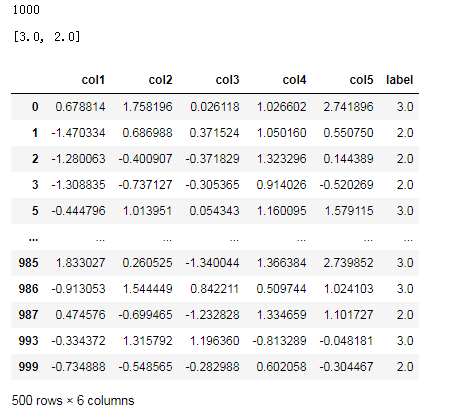
# 整群抽样——随机抽取几个小样本集代表总体,总体1000个样本,小样本集
data=np.loadtxt('data4.txt')
len(data)
label_data_unique=np.unique(data[:,-1]) #定义分层值域(标签类别)
sample_label=random.sample(label_data_unique.tolist(),2) #随机抽取两个组群
sample_label
df=pd.DataFrame(data,columns=['col1','col2','col3','col4','col5','label'])
df.query('label==%s | label==%s' %(sample_label[0],sample_label[1])) #label=2和label=3的样本输出:
最后
以上就是深情蜗牛最近收集整理的关于python基础——抽样——概率抽样(简单随机、等距、分层、整群)的全部内容,更多相关python基础——抽样——概率抽样(简单随机、等距、分层、整群)内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。



![python dataframe 随机找出某一行中 列值最大的位置[列值最大可能会有多个,随机挑选]](https://www.shuijiaxian.com/files_image/reation/bcimg9.png)




发表评论 取消回复