train:test = 0.2
数据集属性:
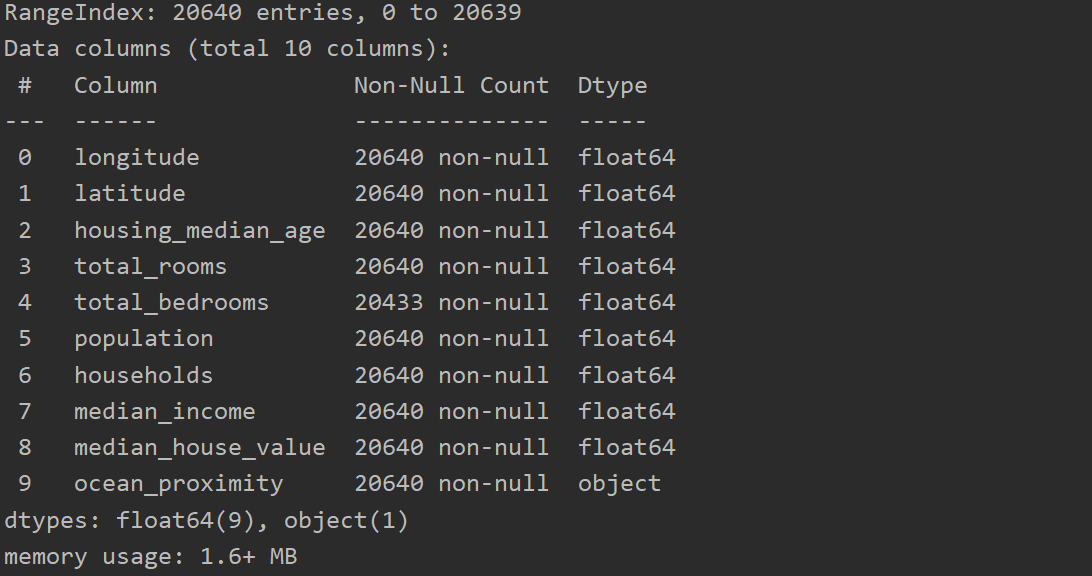
1.load_data.py
import pandas as pd
import os
import matplotlib.pyplot as plt
from create_test import split_train_test
from create_test import split_train_by_id
HOUSING_PATH = "D:\data" # 数据集路径
# 加载housing.csv数据集
def load_housing_data(housing_path):
csv_path = os.path.join(housing_path,"housing.csv")
return pd.read_csv(csv_path)
# <class 'pandas.core.frame.DataFrame'>
housing = load_housing_data(HOUSING_PATH) # 加载数据
##### 数据信息 ###########
# print(housing.head())
# print(housing.info())
# print(housing['ocean_proximity'].value_counts())
# print(housing.describe())
# housing.hist(bins=50,figsize=(20,15)) # 数据项全部绘图展示
# plt.show()
# 随机切分法
# train_set , test_set = split_train_test(housing,0.2)
# print(len(train_set),"train + " , len(test_set) , "test")
# 以行索引作为唯一标识符(需要确保只在数据集末尾添加新数据,且不会删除任何行)
# reset_index() : Generate a new DataFrame or Series with the index reset.
# housing_with_id = housing.reset_index() # add an `index` column
# train_set , test_set = split_train_by_id(housing_with_id,0.2,"index")
# print(len(train_set),len(test_set))
# 以经纬度作为行标识符
housing_with_id = housing.reset_index()
housing_with_id["id"] = housing["longitude"] * 1000 + housing["latitude"]
# print(type(housing_with_id["id"])) # <class 'pandas.core.series.Series'>
train_set , test_set = split_train_by_id(housing_with_id,0.2,"id")
# print(len(train_set),len(test_set))
# 按平均收入(`median_income`)分层分类别并抽样
import numpy as np
from create_test import split_test_by_category
housing["income_cat"] = np.ceil(housing['median_income'] / 1.5)
# inplace为真标识在原数据上操作,为False标识在原数据的copy上操作
# 如果 cond 为真,保持原来的值,否则替换为other
# 大于5的归为类别5
housing["income_cat"].where(housing['income_cat'] < 5 , 5.0 , inplace=True)
train_set , test_set = split_test_by_category(housing,0.2)
# print(housing['income_cat'].value_counts() / len(housing))
# 3.0 0.350581
# 2.0 0.318847
# 4.0 0.176308
# 5.0 0.114438
# 1.0 0.039826
# Name: income_cat, dtype: float64
# 删除income_cat属性,将数据恢复原样
# for set in ( train_set , test_set ):
# set.drop(['income_cat'],axis=1,inplace=True)
2.create_test.py
import numpy as np
# 随机选择实例作为test会导致 ->
# 每次运行都有生成不同test,多次运行将会看到完整的数据集
# 此方法可直接调用Scikit-Learn中的train_test_split(),random_state参数设置随机种子
def split_train_test(data,test_ratio):
np.random.seed(42) # 1.设置随机数种子,每次始终生成相同的随机索引
# 2.第一次运行就保存测试集
shuffled_indices = np.random.permutation(len(data))
test_set_size = int(len(data)*test_ratio)
test_indices = shuffled_indices[:test_set_size]
train_indices = shuffled_indices[test_set_size:]
return data.iloc[train_indices] , data.iloc[test_indices]
########### 上述2方案下次获取更新数据时都会中断 ##########
# 可以利用每个实例的不变唯一的标识符产生测试集
# 如hash,取最后一字节(2**8=256),小于51则放入测试集(51/256≈0.2)
import hashlib
def test_set_check(identifer,test_ratio,hash):
return hash(np.int64(identifer)).digest()[-1] < 256 * test_ratio
def split_train_by_id(data,test_ratio,id_col,hash=hashlib.md5):
ids = data[id_col]
# print(type(ids)) # <class 'pandas.core.series.Series'>
in_test_set = ids.apply(lambda id_: test_set_check(id_,test_ratio,hash))
return data.loc[~in_test_set] , data.loc[in_test_set]
# 根据收入类别分层抽样
from sklearn.model_selection import StratifiedShuffleSplit
def split_test_by_category(data,test_ratio):
# StratifiedShuffleSplit()提供分层抽样功能,确保每个标签对应的样本的比例
# n_splits:是将训练数据分成train/test对的组数
split = StratifiedShuffleSplit(n_splits=1, test_size=test_ratio, random_state=42)
# print(type(split)) # <class 'sklearn.model_selection._split.StratifiedShuffleSplit'>
for train_index, test_index in split.split(data, data["income_cat"]):
strat_train_set = data.loc[train_index]
strat_test_set = data.loc[test_index]
# print(len(strat_train_set),len(strat_test_set))
return strat_train_set , strat_test_set
最后
以上就是务实鸡最近收集整理的关于机器学习测试集选取方法demo-随机、Hash、分层的全部内容,更多相关机器学习测试集选取方法demo-随机、Hash、分层内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复