基于Kettle的数据采集
本文围绕Kettle是什么,用来做什么,怎么用这三个基本问题
网上的资料是真的匮乏,好难受,都是讲到点上的,但是对于新手来说,需要一个来自面的介绍。自己边学边写,很有可能会有问题,也欢迎指点我的错误,但是为了让自己有动力学下去,持续更新中。。。(2021年12月7日补充,原来网上的资料好多,只是我没有找到,就这样了,就当学习记录)
一、Kettle是什么
Kettle 是一款国外开源的 ETL 工具,纯 Java 编写,可以在Windows、Linux和Unix上运行,数据抽取高效稳定,通过提供一个图形化的用户环境来描述你想做什么,而不是你想怎么做,它的数据抽取高效稳定(数据迁移工具)。
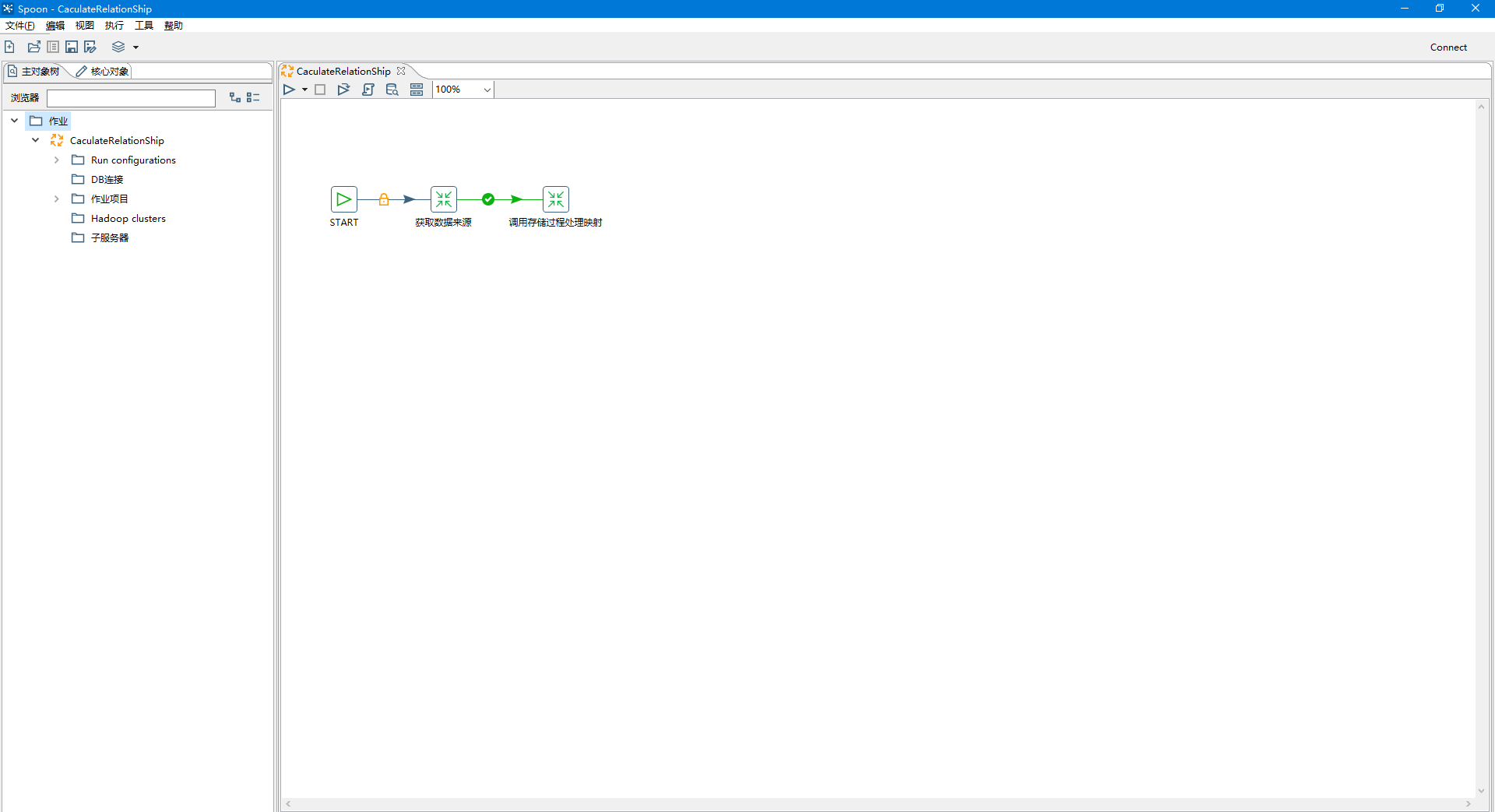
一个简单的Kettle实例,作用是获取数据的来源,并调用相应的存储过程,进行映射的处理。
二、Kettle用来做什么
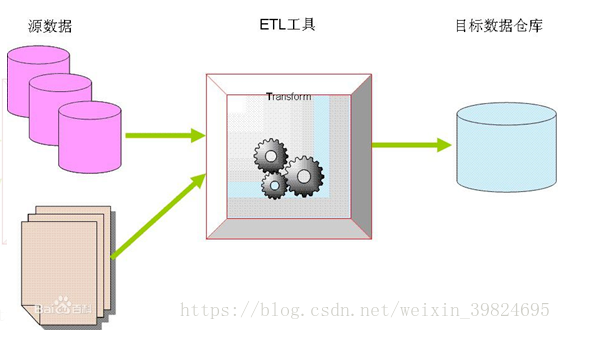
作用:
可以说凡是有数据整合、转换、迁移的场景都可以使用Kettle,他代替了完成数据转换任务的手工编码,降低了开发难度。
同时,我们可以在自己实际业务里,使用它来实现数据的剖析、清洗、校验、抽取、转换和加载等各类常见的ETL类工作。
比如,除了ODS/DW类比较大型的应用外,Kettle实际还可以为中小企业提供灵活的数据抽取和数据处理的功能。Kettle除了支持各种关系型数据库,HBase MongoDB这样的NoSQL数据源外,它还支持Excel、Access这类小型的数据源。并且通过这些插件扩展,kettle可以支持各类数据源。
另外,Kettle的数据处理功能也很强大,除了选择、过滤、分组、连接和排序这些常用的功能外,Kettle里的Java表达式、正则表达式、java脚本、Java类等功能都非常灵活而强大,都非常适合于各种数据处理功能。
应用场景:
- 表视图模式:这种情况我们经常遇到,就是在同一网络环境下,我们对各种数据源的表数据进行抽取、过滤、清洗等,例如历史数据同步、异构系统数据交互、数据对称发布或备份等都归属于这个模式;传统的实现方式一般都要进行研发(一小部分例如两个相同表结构的表之间的数据同步,如果sqlserver数据库可以通过发布/订阅实现),涉及到一些复杂的一些业务逻辑如果我们研发出来还容易出各种bug;
- 前置机模式:这是一种典型的数据交换应用场景,数据交换的双方A和B网络不通,但是A和B都可以和前置机C连接,一般的情况是双方约定好前置机的数据结构,这个结构跟A和B的数据结构基本上是不一致的,这样我们就需要把应用上的数据按照数据标准推送到前置机上,这个研发工作量还是比较大的;
- 文件模式:数据交互的双方A和B是完全的物理隔离,这样就只能通过以文件的方式来进行数据交互了,例如XML格式,在应用A中我们开发一个接口用来生成标准格式的XML,然后用优盘或者别的介质在某一时间把XML数据拷贝之后,然后接入到应用B上,应用B上在按照标准接口解析相应的文件把数据接收过来;
PS:按照个人见解,kettle所做的事情,就是对数据进行各种处理,包括对数据进行清洗校验等,本人使用最多的场景,应该是对数据库的数据进行抽取并清洗,通过一个库抽取到另一个库的表,抽取过来后,通过存储过程进行数据清洗,将接口表数据通过业务逻辑的清洗,最终到落地表中。至于为什么要这么做,因为在实际业务中,很有可能会依赖到另一个系统的数据,一般而言,是不允许直接读取另一个系统的源表数据的,更别提直接对数据进行编写代码来用作调整。
三、Kettle怎么用
Kettle 简介
ETL(Extract-Transform-Load的缩写,即数据抽取、转换、装载的过程),对于企业或行业应用来说,我们经常会遇到各种数据的处理,转换,迁移,了解并掌握一种etl工具的使用,必不可少,支持图形化的GUI设计界面,然后可以以工作流的形式流转,在做一些简单或复杂的数据抽取、质量检测、数据清洗、数据转换、数据过滤等方面有着比较稳定的表现,使用它减少了非常多的研发工作量,提高了我们的工作效率
Kettle官网 :http://kettle.pentaho.org/
下载的最新版本的kettle是:pdi-ce-7.1.0.0-12
官方入门文档 :https://wiki.pentaho.com/display/EAI/Getting+Started
ETL工具-Kettle Spoon教程,关于工具,这篇文章介绍比较完全,不做很详细的介绍。
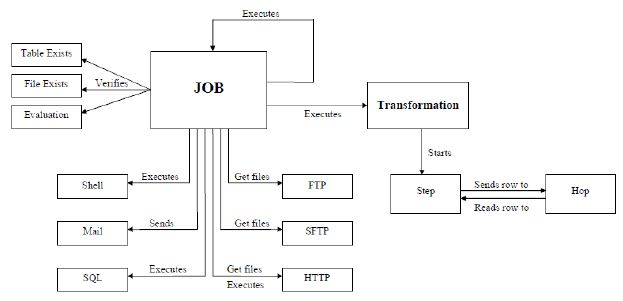
Kettle 专业术语:
-
Transformation 转换步骤,可以理解为将一个或者多个不同的数据源组装成一条数据流水线。然后最终输出到某一个地方,文件或者数据库等。
-
Job 作业,可以调度设计好的转换,也可以执行一些文件处理(比较,删除等),还可以 ftp 上 传,下载文件,发送邮件,执行 shell 命令等
-
Hop 连接转换步骤或者连接 Job(实际上就是执行顺序) 的连线 Transformation hop:主要表示数据的流向。从输入,过滤等转换操作,到输出。
Job hop:可设置执行条件: 1, 无条件执行 2, 当上一个 Job 执行结果为 true 时执行 3, 当上一个 Job 执行结果为 false 时执行
Kettle中有两种脚本文件,transformation(转换ktr结尾)和job(任务kjb结尾),transformation完成针对数据的基础转换,job则完成整个工作流的控制(工作流程首先由个开始节点【可以设置定时执行】 可以选择transformation)。
—2021.11.22—
四、Kettle简单使用
Kettle的具体使用:
最简单的使用例子,将源库中的源表采集到目标库中的目标表,就是把a库中某一张表,直接抽到b库的表中
前置
安装与使用,
kettle是开源的免费工具,可以直接去官网进行下载,同时由于kettle是Java编写,需要配置jdk,建议1.8以上。(工具需要可留邮箱)
下载到本地后,运行Spoon.bat的脚本文件
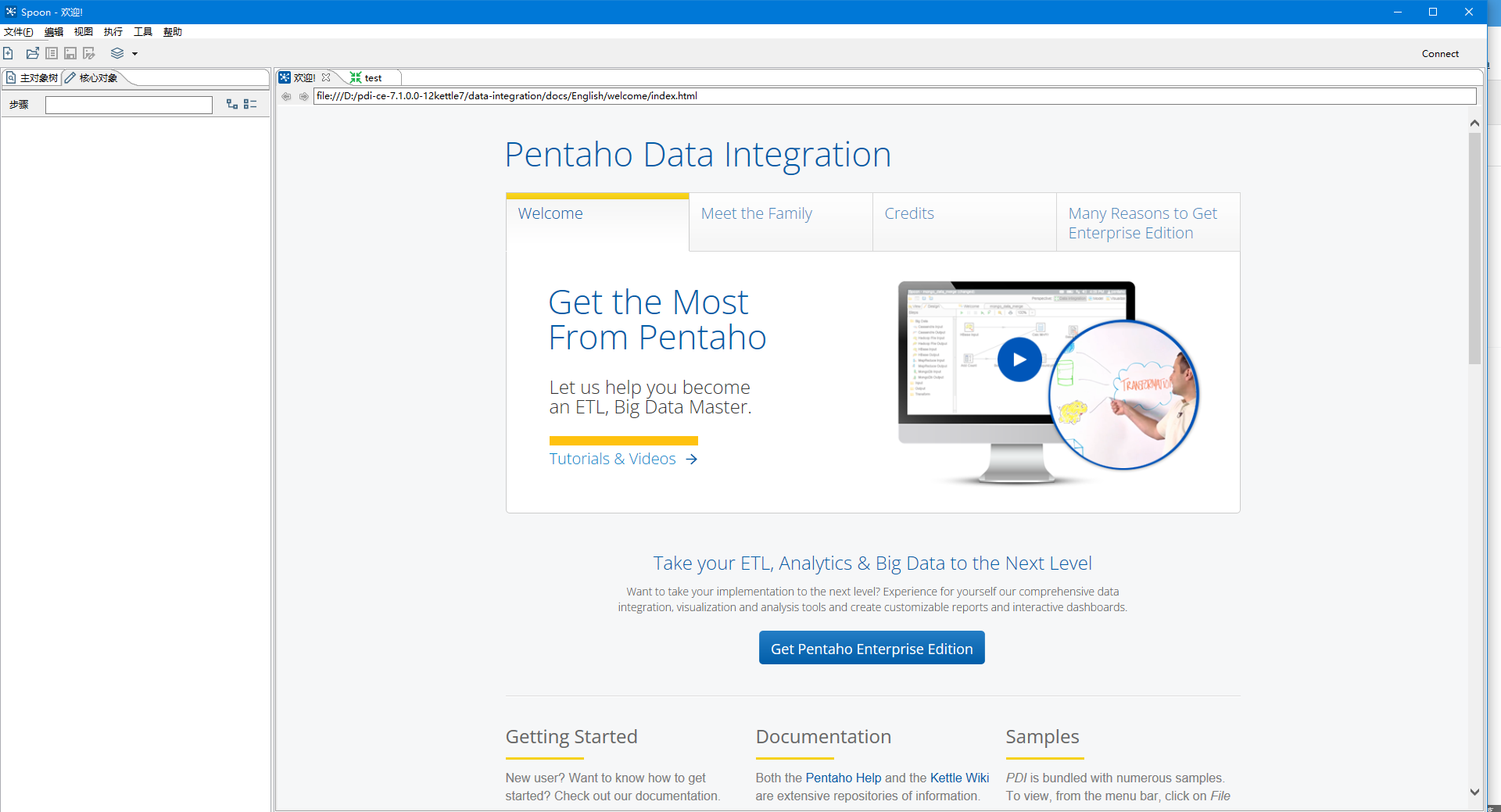
安装成功,并执行脚本文件后,会出现一个基于windows的可视化的程序,如下
实操
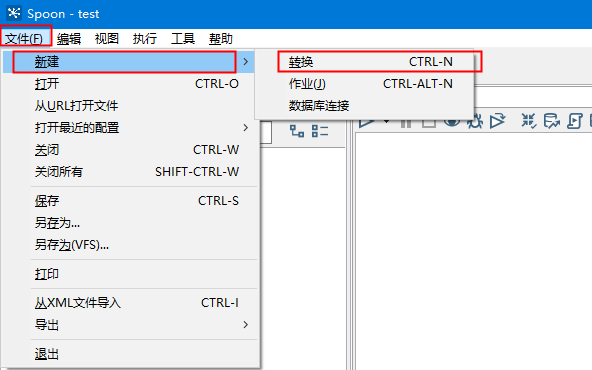
1.新建转换(俩库之间的采集的建立)
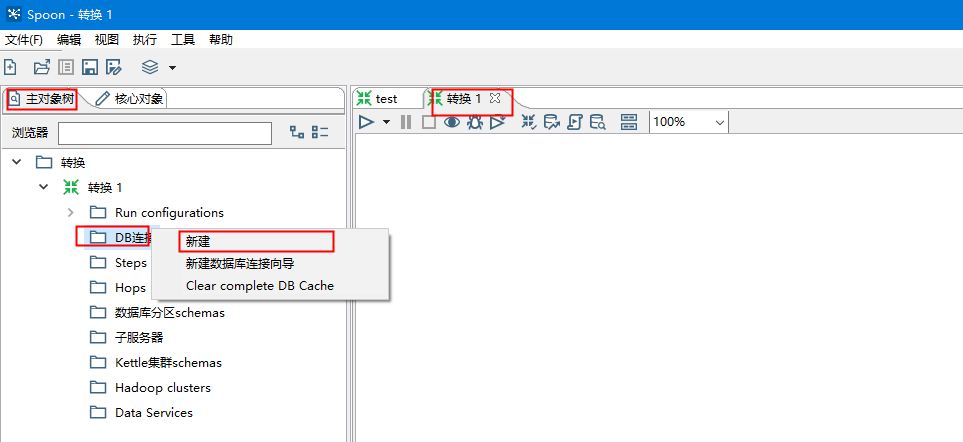
在新增的转换中,新建数据连接,包括目标库与源库俩个连接
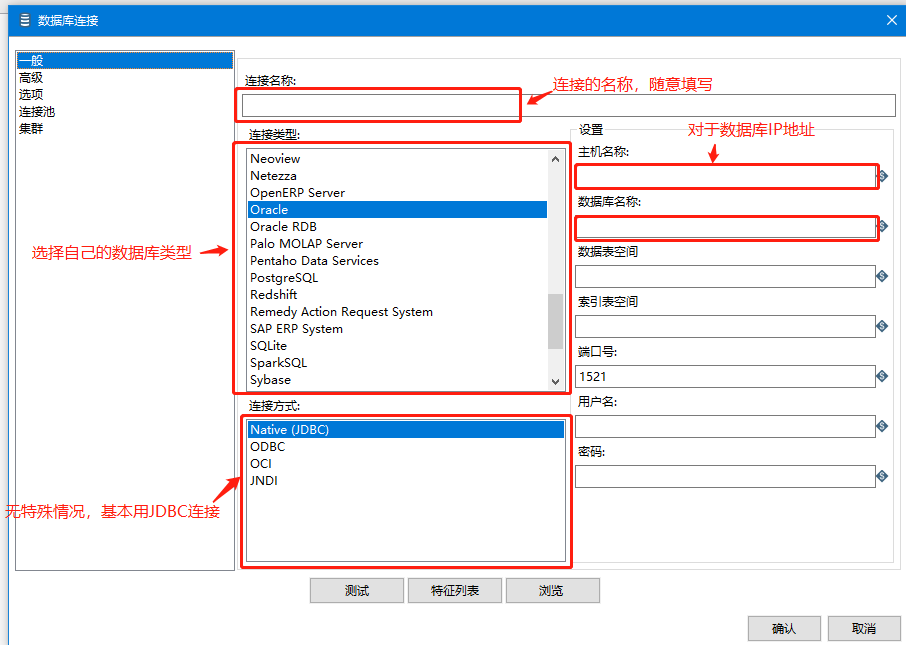
连接信息可如下图填写
填写完成后,可以点击测试,如果测试结果如下,为成功建立
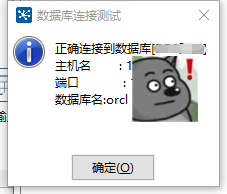
数据库建立后,新增输入-表输入(配置源表数据来源)
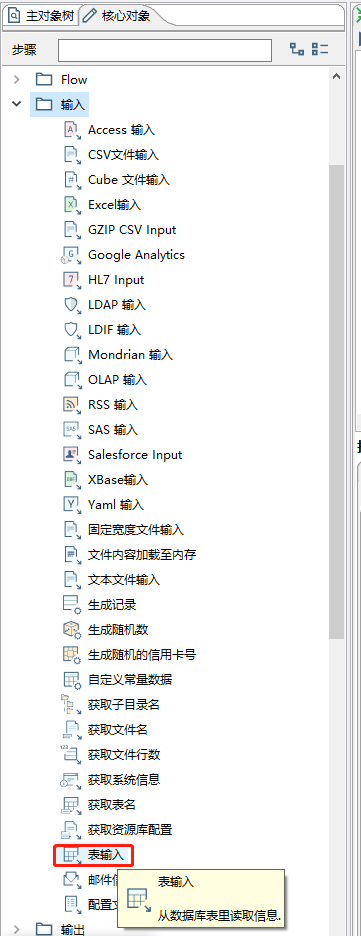
配置内容如下
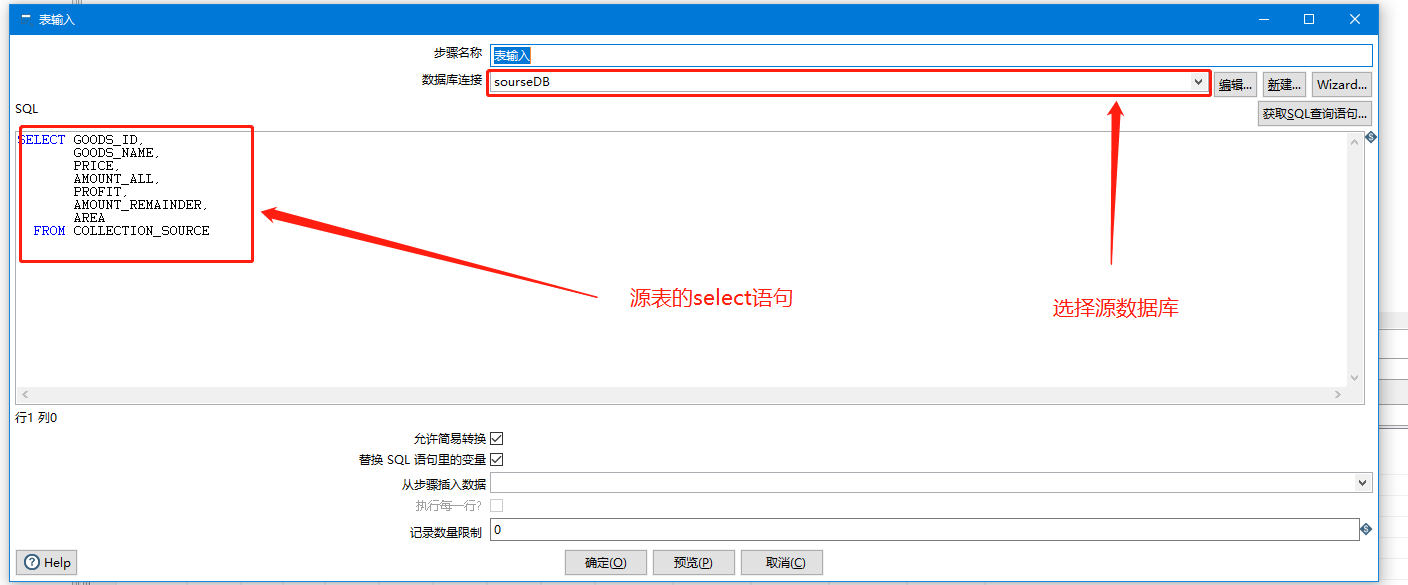
输入配置完后,配置输出-插入更新(配置目标表信息,以及字段名配置)
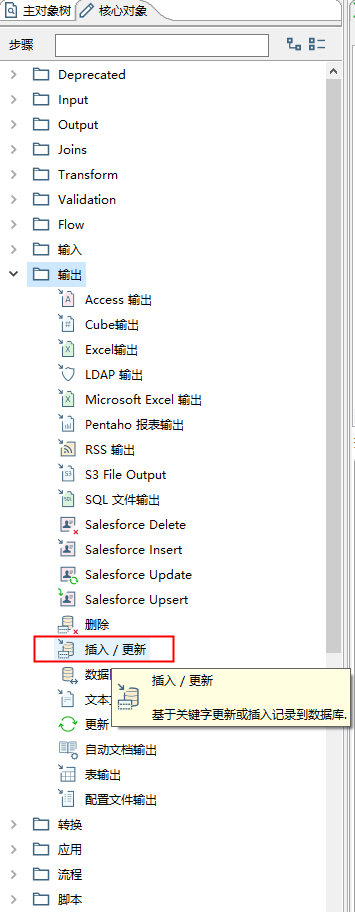
配置内容如下
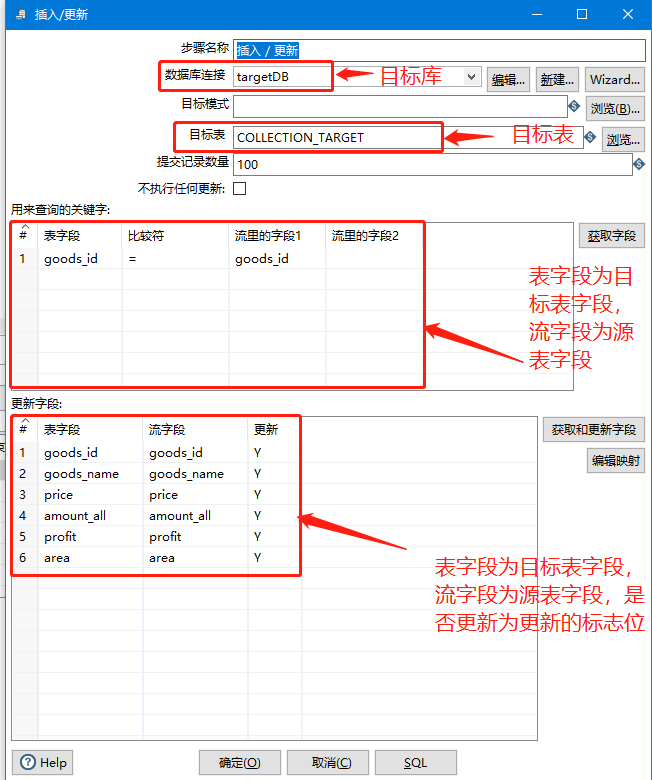
输入与输出都配置完成后,通过Hop(连接线),将输入与输出进行连接。【选中输入后,按住shift,拖拽至输出即可】
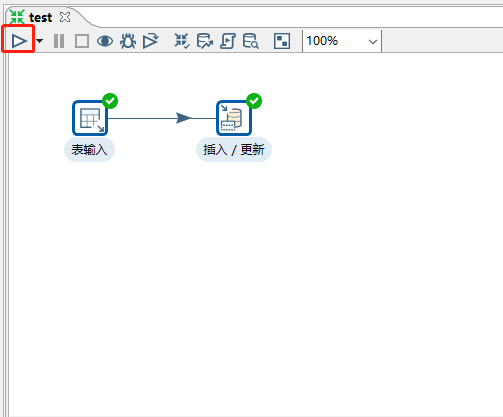
配置完成后进行测试,点击左上角的运行按钮
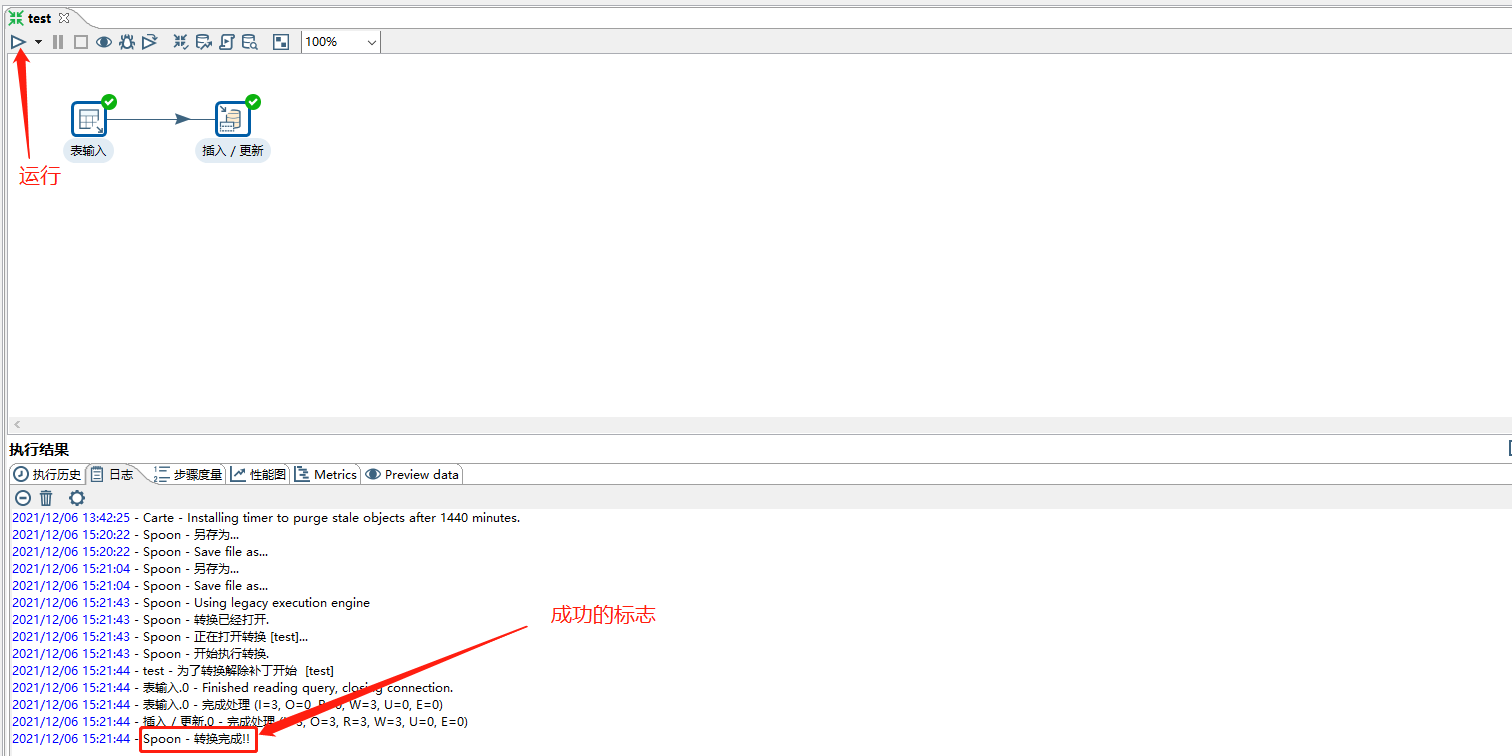
在目标库中,可以观察到,源表的数据已经被抽取到目标表中。

2.新建作业(Job)【用于调用刚刚那个转换,包括定时调用与立即调用】
新增一个作业,如下
在新增的作业中,新增一个START(配置调用时间)
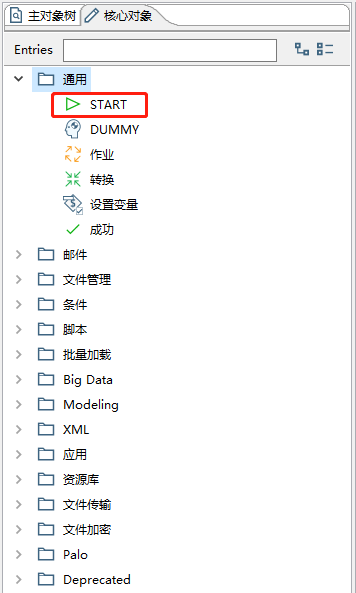
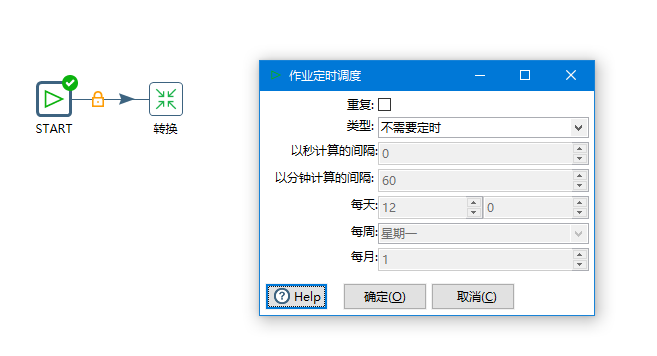
配置如下,可以自己进行时间的配置
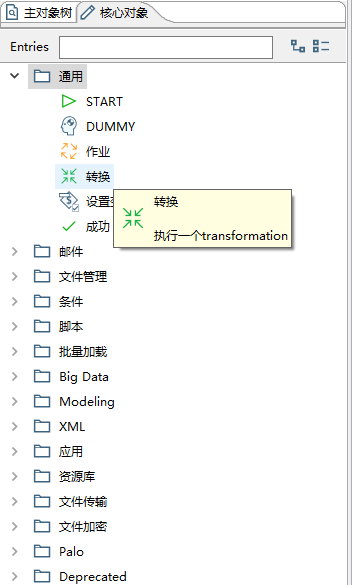
在新增的作业中,新增一个转换(配置刚刚保存的那个转换)
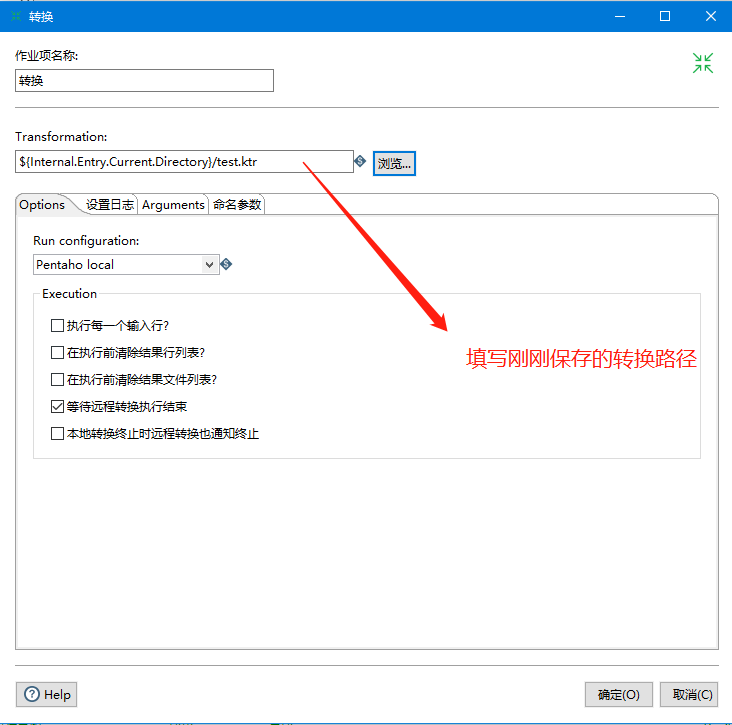
配置信息如下
同理,用Hop把俩者连接
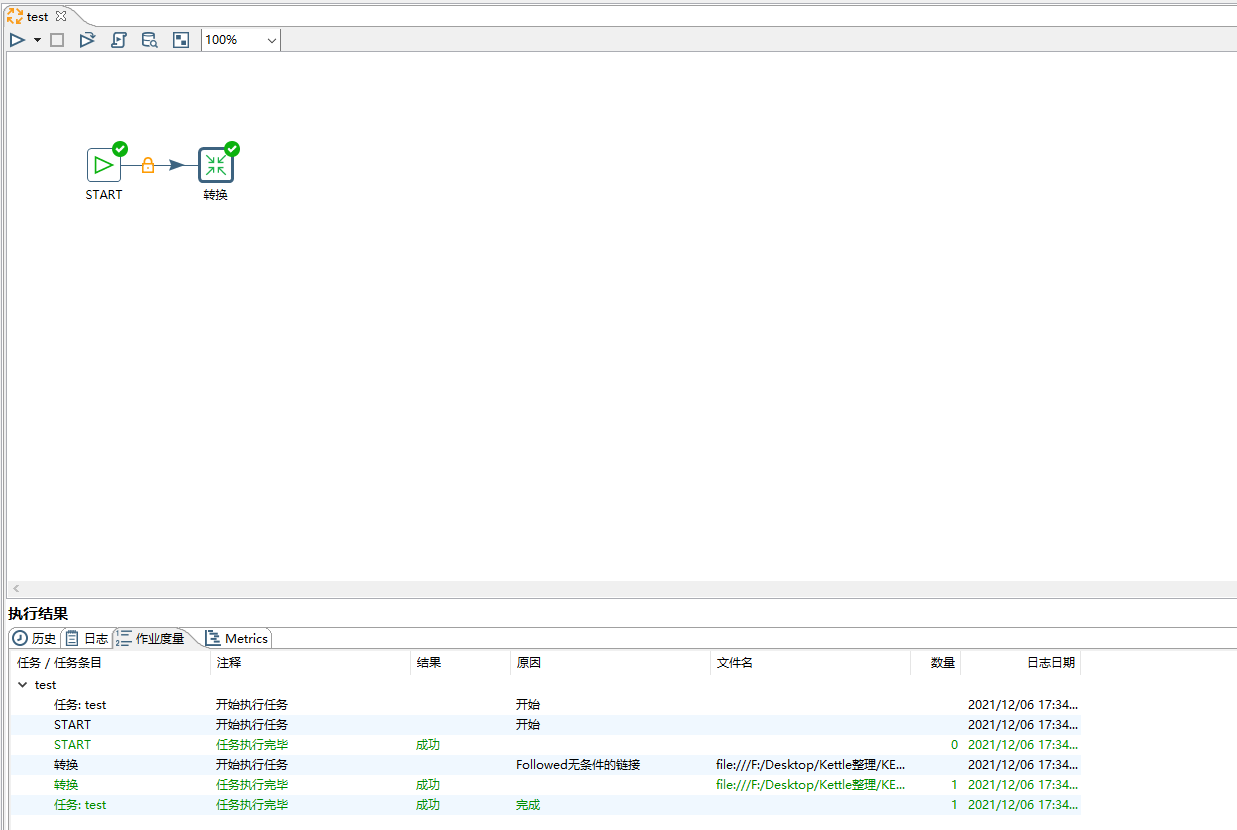
连接后进行测试作业是否正常执行,如下后作业也新建成功。
小结
至此,kettle三元素中的转换(Trancer),作业(Job),连接线(Hop),都全部使用过了。起码是完成了最基本的数的抽取,完成了,最简单的kettle的使用,至于一些复杂的参数传递,业务上的清洗放到下一节。
—2021.12.07—
五、Kettle使用实例
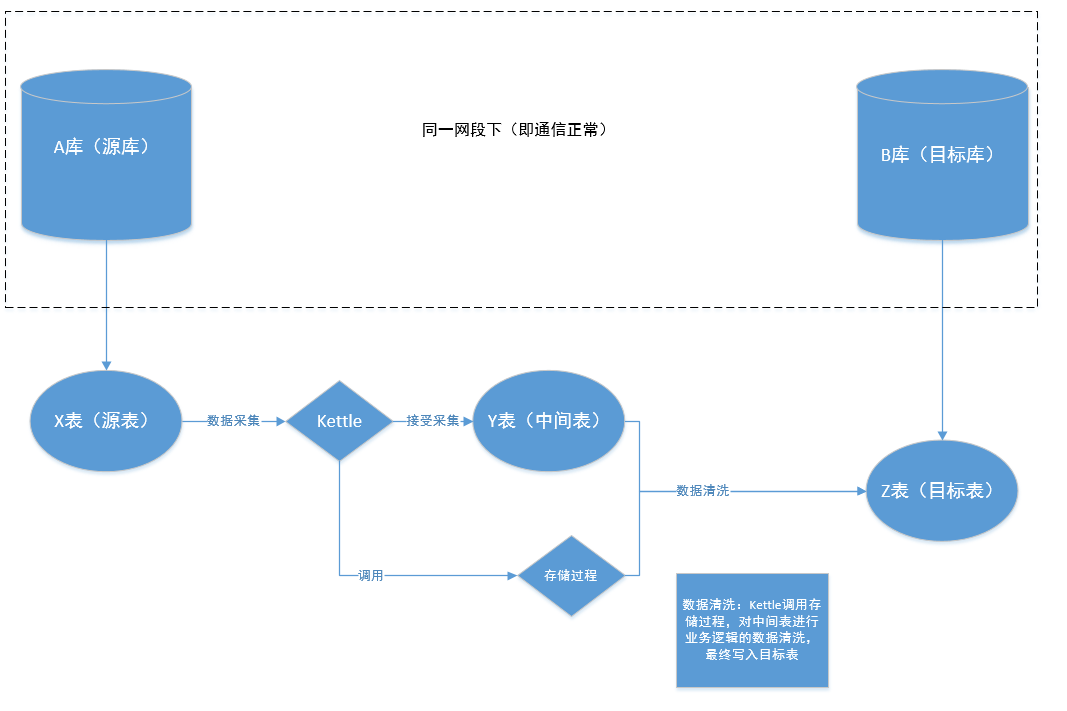
使用情景:B库为当前系统,当前系统需要操作A库所对应系统中,X表内数据。不允许直接建立DBLink为直连手段,只允许,通过Kettle进行数据的抽取并清洗,完成,从一个库到另一个库的数据抽取,并进行逻辑清洗。
解决条件与思路:
俩套数据库均为oracle,且部署在不同的服务器上,但是在同一网段下,网络通信正常。
俩个数据库,简称a库与b库,a库为源库,b库为目标库。a,b库,俩个数据库中均有一张表结构一致的表,X表与Y表,Y表作为俩库中的中间表,且b库中,有一张最终结果的目标结果表Z(Z表作为当前系统,希望看到的数据)。
最后
以上就是无情白猫最近收集整理的关于基于Kettle的数据采集原理以及应用过程基于Kettle的数据采集的全部内容,更多相关基于Kettle内容请搜索靠谱客的其他文章。








发表评论 取消回复