文章目录
- 一、 存储器
- 二、存储器层次化结构
- Ⅰ、层次化结构的性能
- 有效访问时间(EAT)
- Ⅱ、数据局部性
- Ⅲ、典型的层次化存储
- 三、SRAM和DRAM
- 四、高速缓存
- Ⅰ、缓存映射
- 为什么采用块的形式?
- 缓存寻址方式类比
- 1、直接映射
- 2、全相联映射(Fully Associative Mapping)
- 4、组相联映射(SAM)
- Ⅱ、缓存映射示例
- Ⅲ、缓存替换策略
- 完
一、 存储器
- ROM:数据读取快、存储时间长、耗电低。用于BIOS、CD-ROM、闪存
- RAM:可以随机读写、需要通电。多用于主存
二、存储器层次化结构
由于不同类型的存储器访问速度、存储成本不同,需要合理规划、分配适合的存储器。一般来说,访问速度越快的存储器价格越高、存储空间越小,性能与成本成正比。而计算机在访问数据的时候会优先使用访问速度快的存储器
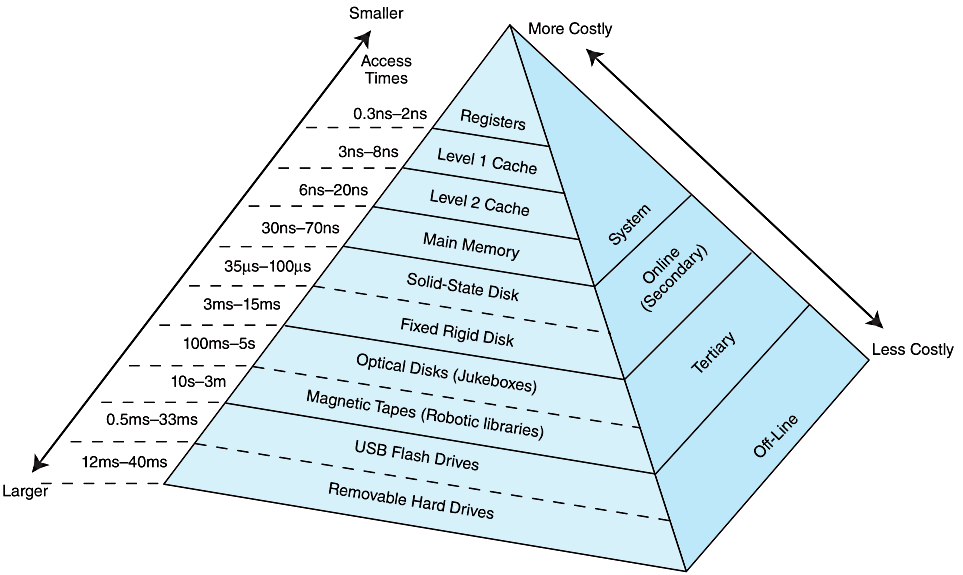
Ⅰ、层次化结构的性能
对于每一层存储结构,用以下指标衡量其查询数据的性能:
- 命中(hit):需要的信息存储在该层结构内
命中率(hit rate):命中次数/总查询次数
命中时间(hit time):查一次的时间 - 失效(miss):需要的信息没有存储在该层结构内
失效率(miss rate):失效查询/总查询
失效惩罚(miss penalty):处理一次失效的总时间花销,包括去下一层查询然后传回当前层的时间 - 平均访问时间(AAT):命中率x命中时间+失效率x惩罚
- 有效访问时间(EAT, Effective Access Time):通常采用EAT描述层次化存储系统的性能
其中:命中率+失效率=1、惩罚=下层访问时间+当前层数据更新时间
有效访问时间(EAT)
有效访问时间是指层次化存储系统中,数据查找的期望时间。它的决定因素有:
- 存储层的性能,主要由物理结构决定
- 查找方法:并行访问(多个不同层次同时访问)、顺序访问(按层先后访问)
假设有两级层次化存储系统,其中第一级访问时间10ns,第二级100ns,第一级命中率90%,以下列出两种访问类型的EAT:
并行:EAT=90%x10ns+10%x100ns=19ns
顺序:EAT=90%x10ns+10%x(10ns+100ns)=20ns
假设一个三级层次化存储系统,其中第一级访问速度为1ns,命中率为80%,第二级访问速度为10ns,命中率为90%,第三级访问速度为100ns,命中率为99%,采用并行访问方式进行访问的有效访问时间是___________ns,采用顺序访问方式进行访问的有效访问时间是_________ns。
并行:EAT=80%x1ns+20%x(90%x10ns+10%x100ns)=4.6ns
顺序:EAT=80%x1ns+20%x{1ns+[90%x10ns+10%x(10ns+110ns)]}=5.0ns
可以先计算后几层的再计算第一层的时间
Ⅱ、数据局部性
当发生一次数据失效时,层次化存储器会把失效数据附近的数据快一起拷贝并存储,这就是利用数据局部性提高命中率
数据局部性体现为以下形式:
- 时间局部性(temporal locality):最近访问的数据在不远的将来会再次访问
- 空间局部性(spatial locality):即将要访问的数据在最近访问过的数据附近
- 顺序局部性(sequential locality):数据会按照顺序访问
Ⅲ、典型的层次化存储
现代计算机中,最典型的层次化存储系统是由高速缓存、主存储器、虚拟内存构成的,高速缓存提高了内存访问速度、虚拟内存扩大了内存访问的空间,各结构依据自身物理结构不同,合理分配工作
三、SRAM和DRAM
RAM分为以下两类:
- 静态随机访问存储器(Static Random Access Memory, SRAM):类似于D触发器的结构。多用于高速缓存
- 动态随机访问存储器(Dynamic Random Access Memory, DRAM):采用电容实现,需要充电。多用于主存储器
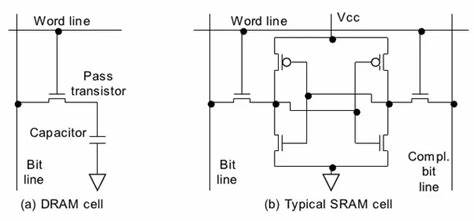
由于结构不同,它们的性能也不同,以下是性能比较:
- 访问速度:静态>动态
- 能耗:静态<动态
- 电路复杂度:静态>动态
- 密度:静态<动态
- 成本造价:静态>动态
四、高速缓存
利用数据局部性,用较小的高速访问存储器来提高内存性能。现代计算机使用三级缓存,位置在CPU内。
高速缓存中的寻址根据存储的内容,也被称为按内容寻址寄存器(Content Addressable Memory, CAM)。 寻址将主存储器地址映射为缓存地址,因此也被称为缓存映射,缓存采用和主存储器同样的存储单元,因此映射只取决于地址空间大小,与内存寻址方法无关
Ⅰ、缓存映射
高速缓存和主存储器采用大小相同的块;缓存采用有效位标识一个块是否保存了有效数据;当缓存失效时,将整个块从主存储器重载入缓存;由于同一份数据在块内的偏移是相同的,不同映射策略体现在对块的管理映射策略上
为什么采用块的形式?
采用块是为了利用数据的局部性提高命中率,同时可以对地址、状态进行压缩,提高缓存存储能力。
例如,假设用64位按字寻址的存储器和高速缓存,每个缓存单元要3个状态位
缓存按存储单元处理,8个单元需要8*(64+64+3)=1048位
按8个单元组成的块,需要8*64+(74-log2(8)+3)=576位
缓存寻址方式类比
缓存寻址方式分为两种:直接映射寻址、全相联映射寻址
- 主存储器寻址类比为数组
以a表示,给定地址x,数据保存在a[x] - 直接映射寻址类比为哈希表
用表a存储,共N个单元,每个单元存储一对数据(x,y),给定x,高速缓存计算一个哈希值z=h(x)modN,如果a[z].x==x,则返回a[z].y,否则失败 - 全相联映射寻址类比为数组
用数组a存储,共N个单元,每个单元存储一对数据(x,y),给定x,高速缓存对于第i个单元判断(遍历),如果a[i].x==x,则返回a[z].y,否则失败
1、直接映射
假设缓存有N个块,内存中编号X的块映射到缓存中Y的块,即Y=XmodN
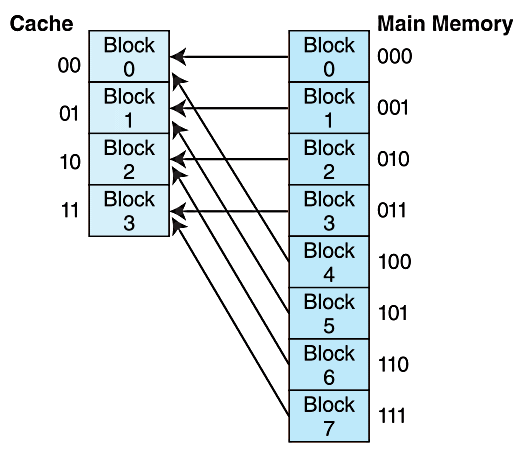
直接映射的地址分为三个字段
- offset:块内偏移
- block:块编号
- tag:tag和block决定了在主存储器中的存储块编号
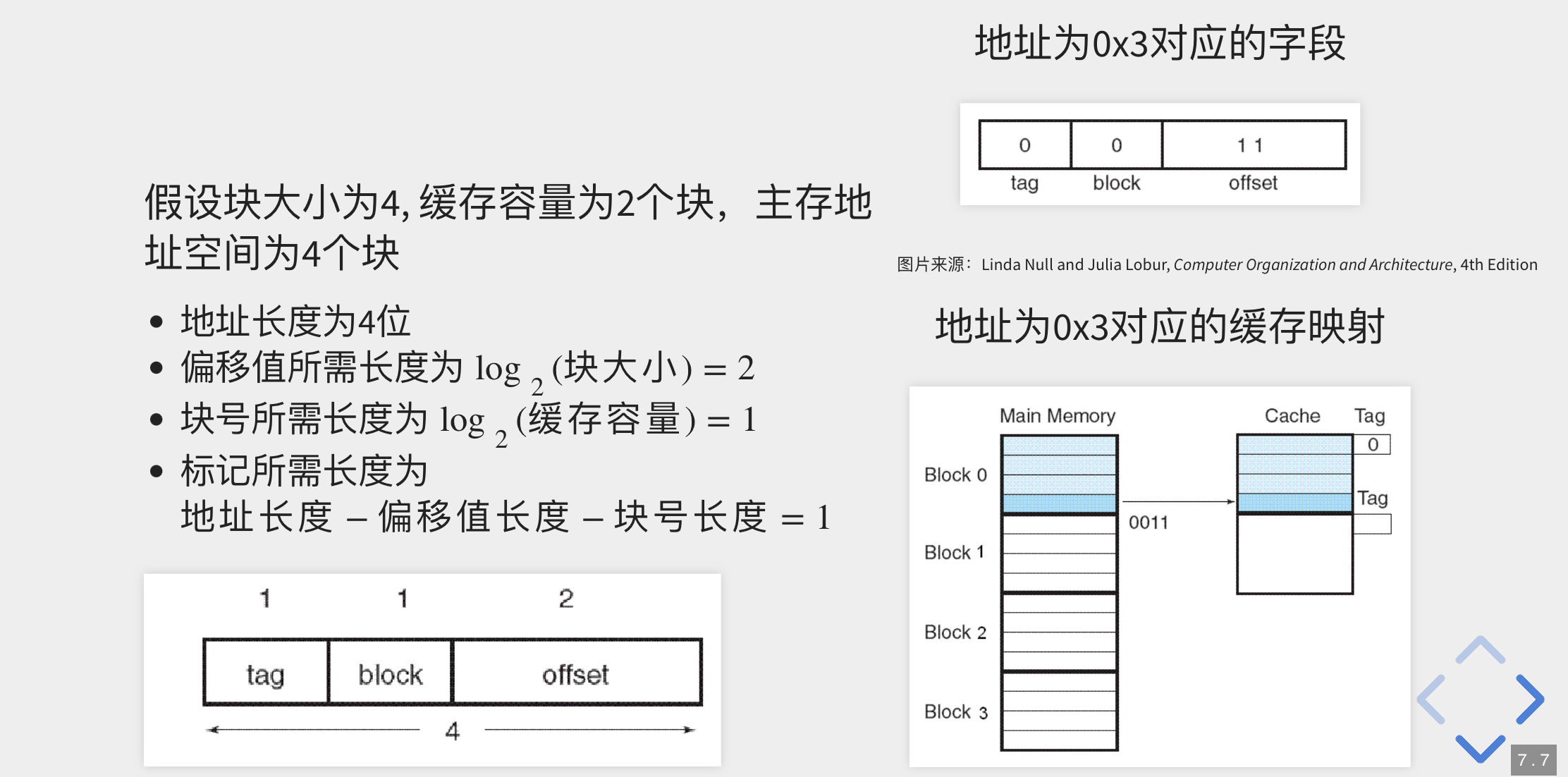
假设一个按字节寻址的存储器使用16位地址缓存64个块,每块8字节,求映射地址0x0404的各字段
地址长度=16
块内偏移值字段长度=log2(8)=3
块号字段长度=log2(64)=6
tag字段长度=16-3-6=7
0x0404=0000 0100 0000 0100,按照字段长度分组:0000010 000000 100
表示标记为2、0号块、偏移为4的映射地址
2、全相联映射(Fully Associative Mapping)
主存储器中任意一个块都能映射到任意的所有缓存块,因此查找只能遍历
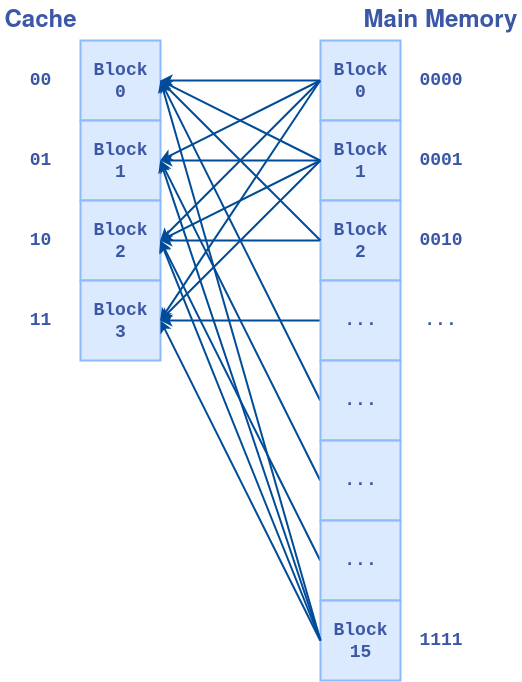
全相联映射的地址分为两个字段
- offset:块内偏移
- tag:主存储器中的块号
全相联映射与直接映射相比:
- 缓存利用率更高
- 命中更高
- tag较长,占空间
- 查找需要遍历
- 成本高
全相联映射类比成停车,在一个停车场内,所有车位都能停,因此仅仅凭全相联映射的地址无法得到具体在哪个车位,只能遍历查找
实际中,采用的是二者折中方案——组相联映射(Set Associative Mapping)
4、组相联映射(SAM)
主存储器中任意一个块都能映射到任意一组的任意一个缓存块
N路组相联映射(N-way Set Associative Mapping)假设缓存有M组,每个组N块,内存中编号为X的块映射到缓存中编号Y的组,Y=XmodM
二路组相联映射:
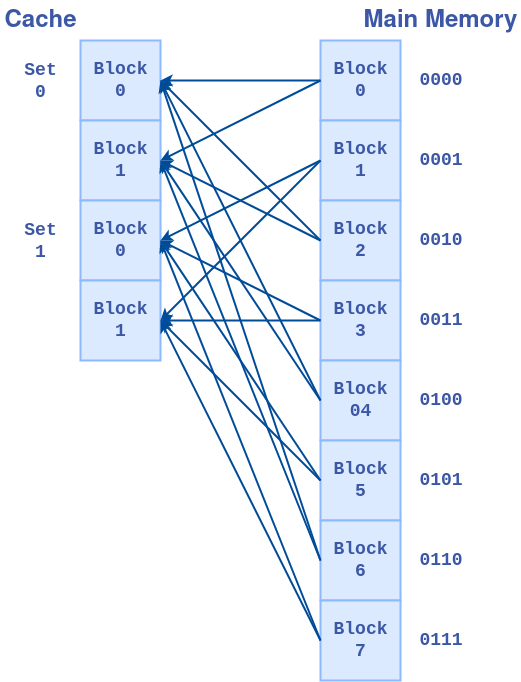
组相联映射的地址分为三个字段
- offset
- set:代表在缓存内的组编号
- tag:与组好共同给决定在主存储器中的块编号
Ⅱ、缓存映射示例
假设一个按字节寻址的存储器总容量为1MB,缓存有32个块,每块有16个字节,分析采用直接映射、全相联映射和4路组相联映射时,地址为0x326A0在高速缓存中的位置
0x326A0=0011 0010 0110 1010 0000
直接映射:
地址总长=log2(1M)=20
偏移段=log2(16)=4
块编号=log2(32)=5
标记字段长=20-9=11
分组:00100010011 01010 0000,位于编号为0x0A的缓存块
全相联映射:
地址总长=20
偏移段=4
标记字段=20-4=16
分组:0011001001101010 0000,由于是随机映射,无法确定具体是哪一块
四路组相联映射:
地址总长=20
偏移段=4
组编号=log2(32/4)=3
标记字段=20-7=13
分组:0011001001101 010 0000,位于0x02的组,但组内是随机映射,无法确定具体位置
Ⅲ、缓存替换策略
对于全相联和组相联映射,当空间不足时,新块会替换旧块,选择被替换块的依据就叫替换策略
理论最优的是将未来一段时间访问频率最低的换出(evict)
常见:
- 最近最少使用(Least Recently Used,LRU)
- 先入先出(FIFO):存在时间最长
- 随机:可能导致常用被换出,但是可以避免同一个块被频繁换入换出
完
最后
以上就是笨笨宝马最近收集整理的关于计组——存储_层次化结构_高速缓存_缓存映射一、 存储器二、存储器层次化结构三、SRAM和DRAM四、高速缓存完的全部内容,更多相关计组——存储_层次化结构_高速缓存_缓存映射一、内容请搜索靠谱客的其他文章。








发表评论 取消回复