机器学习笔记之决策树算法——基本介绍
- 引言
- 关于决策树的示例
- 基于上述示例对决策树的一些认识
- 决策树的训练和测试
- 决策树的特征选择
- 熵的概念回顾
- 信息增益
- 决策树的构建实例
- 信息增益率与GINI系数
- ID3决策树算法的问题与解决方式
- 关于GINI系数
引言
本节将介绍决策树算法。
关于决策树的示例
首先,存在如下5个样本组成的样本集合 D mathcal D D:
| 年龄( a g e age age) | 性别( s e x sex sex) | 是否玩电脑游戏( l a b e l label label) | |
|---|---|---|---|
| 1 | 65 | 1 | 0 |
| 2 | 68 | 0 | 0 |
| 3 | 39 | 1 | 0 |
| 4 | 11 | 1 | 0 |
| 5 | 10 | 0 | 1 |
想要根据是否玩电脑游戏这个标签对样本进行正确分类。我们尝试进行如下规则构建:
-
如果年龄大于15岁,则认定其不玩电脑游戏,反之,小于15岁则玩电脑游戏:
{ 1 a g e > 15 0 a g e ≤ 15 begin{cases} 1 quad age > 15 \ 0 quad age leq15 end{cases} {1age>150age≤15
此时,可以将 D mathcal D D通过年龄规则划分为如下两个子集合:
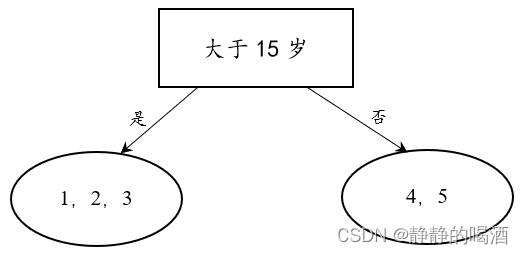
观察上述划分结果,大于15岁(左侧的子集)的样本有样本 1 , 2 , 3 1,2,3 1,2,3共三个样本,并且他们的 l a b e l label label结果均是不玩电脑游戏,这说明 左侧的子集 内部只包含1个标签,无需再次进行划分;
观察小于15岁 (右侧的子集),4号样本的标签是0,而5号样本的标签是1。因此,需要继续对右侧子集进行划分。 -
如果性别是女(1),就认为其不玩电脑游戏;相反,性别是男(0),则认定其玩电脑游戏:
{ 1 s e x = 0 0 s e x = 1 begin{cases} 1 quad sex=0 \ 0 quad sex=1 end{cases} {1sex=00sex=1
关于上述右侧字集合 D r i g h t mathcal D_{right} Dright划分结果表示如下:
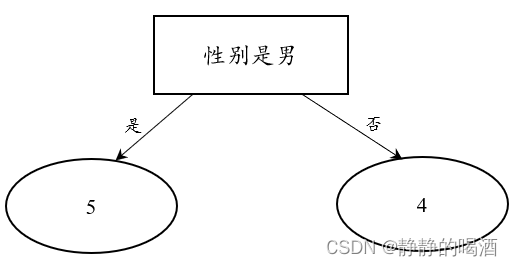
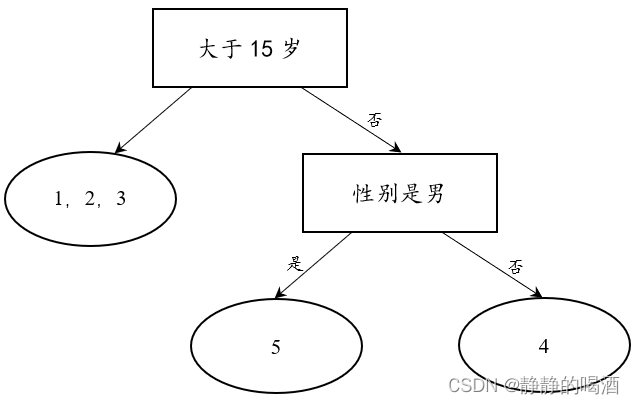
同第一次划分,继续观察 D r i g h t mathcal D_{right} Dright集合的划分结果。左侧的子集 内部只包含一种标签——玩电脑游戏;而 右侧的子集 内部同样只包含一种标签——不玩电脑游戏。因此,第二次划分产生的两个子集同样不需要继续划分。至此,决策树划分过程结束。产生的决策树结果表示如下:
基于上述示例对决策树的一些认识
观察上述树结构:
- 树中的非叶节点均是 关于特征的判定条件;树中的叶节点均是 数据集合 D mathcal D D的各个子集。
- 树中的 根节点 是第一个作为判定条件的特征;
- 观察子集合 D l e f t = { 1 , 2 , 3 } mathcal D_{left} = {1,2,3} Dleft={1,2,3},它实际上并没有划分完全,该集合从性别角度观察有男有女,但关于该集合的划分却停止了。
因此,关于上述树结构,我们有如下认识:
- 选择作为判定条件的特征 存在顺序。换句话说,特征的选择顺序需要满足具体规则;
- 叶节点作为最终的决策结果,它满足的条件是叶节点中所有样本元素中的标签信息无法继续划分;
决策树的训练和测试
决策树的训练阶段主要是给定当前的数据集合 D mathcal D D,如何构建一棵决策树。具体包含:
- 从根节点开始,到最后一次划分结束,特征选择的顺序;
- 在特征选择确定的基础上,如何使用特征,对数据集合或相应子集合进行特征切分;最终正确的划分样本集合,构建一棵决策树。
决策树的测试阶段主要是给定一棵决策树的基础上,将未出现在训练集的样本使用决策树进行预测:
依然基于上述示例,此时有一个陌生的样本
k
k
k:
| 年龄( a g e age age) | 性别( s e x sex sex) | |
|---|---|---|
| k k k | 41 | 0 |
该样本的标签信息具体是什么情况:
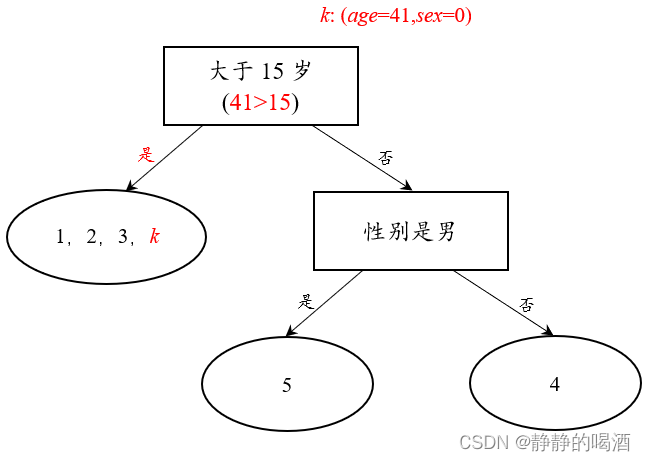
根据模型判断,这个编号为
k
k
k的样本与编号为1,2,3的样本处于相同集合,而该集合均不玩电脑游戏。因此,编号
k
k
k样本不玩电脑游戏。
我们发现:决策树的测试仅将陌生样本带入构建好的决策树中执行一次划分过程,从而得到预测结果。
因此,决策树的训练过程(决策树的构建过程)才是整个决策树算法的关键部分。
决策树的特征选择
在决策树的特征选择过程中存在顺序,即从根节点开始,到最后一个非叶节点结束,存在具体顺序。
第一次特征选择,也就是根节点的选择,它面对的是整个数据集合 D mathcal D D,因此根节点选择的特征对样本的分类效果最强,以此类推。
如何使用数学语言 描述特征对样本的分类效果?这里将回顾一个概念——熵(Entropy)。
熵的概念回顾
我们在指数族分布介绍的最大熵思想中介绍过熵的概念。它本质上是 信息量在事件发生概率分布下的期望。而该期望值表示随机变量不确定性的一种度量。
通俗解释:关于随机变量混乱程度的一种量的表示。
H
(
X
)
=
−
∑
i
p
i
log
p
i
(
i
=
1
,
2
,
⋯
,
n
)
mathcal H(X) = -sum_i p_i log p_i quad (i=1,2,cdots,n)
H(X)=−i∑pilogpi(i=1,2,⋯,n)
假设存在如下两个数据集合
D
1
,
D
2
mathcal D_1,mathcal D_2
D1,D2:
为了简化理解,这里的集合进行了排序。
D
1
=
{
1
,
1
,
1
,
1
,
1
,
2
,
2
}
D
2
=
{
1
,
2
,
4
,
5
,
7
,
8
,
9
}
mathcal D_1 = {1,1,1,1,1,2,2} \ mathcal D_2 = {1,2,4,5,7,8,9}
D1={1,1,1,1,1,2,2}D2={1,2,4,5,7,8,9}
从表面上观察,
D
1
mathcal D_1
D1集合明显比
D
2
mathcal D_2
D2集合要稳定得多。原因在于
D
1
mathcal D_1
D1集合内得各元素相比于
D
2
mathcal D_2
D2 差距并不大。
而使用熵表示上述集合的混乱程度如下:
-
对于 D 1 mathcal D_1 D1集合,该集合内仅包含2种样本: 1 , 2 1,2 1,2。各样本在 D 1 mathcal D_1 D1集合种被选择的概率表示如下:
类别 1 1 1 2 2 2 p i ( i = 1 , 2 ) p_i(i=1,2) pi(i=1,2) 5 7 frac{5}{7} 75 2 7 frac{2}{7} 72 关于集合 D 1 mathcal D_1 D1熵的结果表示如下:
− ( p 1 log p 1 + p 2 log p 2 ) ≈ 0.5983 - (p_1log p_1 + p_2 log p_2) approx0.5983 −(p1logp1+p2logp2)≈0.5983 -
同理,对于 D 2 mathcal D_2 D2集合,集合种各元素均只出现过一次。因而集合 D 2 mathcal D_2 D2中各元素被选择的概率均为 1 7 frac{1}{7} 71。
因而 D 2 mathcal D_2 D2熵的结果表示如下:
− ∑ i = 1 7 1 7 log 1 7 = − log 1 7 ≈ 1.9459 - sum_{i=1}^7 frac{1}{7} log frac{1}{7} = - log frac{1}{7} approx 1.9459 −i=1∑771log71=−log71≈1.9459
由于 1.9459 > 0.5983 1.9459 > 0.5983 1.9459>0.5983,因此通过熵的角度判定 D 2 mathcal D_2 D2的混乱程度明显高于 D 1 mathcal D_1 D1。
在回顾完熵的相关信息后,一个新的问题:熵只是关于随机变量(在这里是数据集合)混乱程度的一种度量,它和决策树存在什么样的关系?
示例:假设存在如下数据集合
D
′
mathcal D'
D′:
D
′
=
{
1
,
1
,
1
,
1
,
1
,
1
,
2
,
2
,
2
}
mathcal D' = {1,1,1,1,1,1,2,2,2}
D′={1,1,1,1,1,1,2,2,2}
如果通过不同划分方式得到如下两种划分结果:
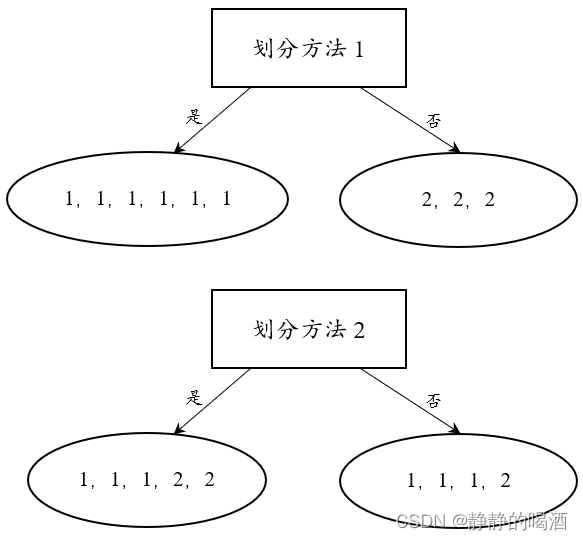
从分类结果的角度观察,划分方法1要明显优于划分方法2。用熵的角度进行表示:
- 划分方法1条件下各子集的熵的结果:
S l e f t 1 = S r i g h t 1 = 0 mathcal S_{left}^1 = mathcal S_{right}^1 = 0 Sleft1=Sright1=0 - 划分方法2条件下个子集的熵的结果:
S l e f t 2 = − 1 × ( 3 5 log 3 5 + 2 5 log 2 5 ) ≈ 0.6730 S r i g h t 2 = − 1 × ( 3 4 log 3 4 + 1 4 log 1 4 ) ≈ 0.5623 begin{aligned} mathcal S_{left}^2 & = -1 times (frac{3}{5}log frac{3}{5} + frac{2}{5} log frac{2}{5}) approx 0.6730 \ mathcal S_{right}^2 & = -1 times (frac{3}{4}log frac{3}{4} + frac{1}{4} log frac{1}{4}) approx 0.5623 end{aligned} Sleft2Sright2=−1×(53log53+52log52)≈0.6730=−1×(43log43+41log41)≈0.5623
可以得出如下看法:特征选择后划分子集的熵越小,意味着划分后各子集的结果越稳定,特征选择越好。
信息增益
上面介绍了熵与特征选择的好坏构建了关联关系,此时决策树每次进行特征选择时,必然选择基于特征条件下,划分出的子集效果最好(最稳定)的特征。
这里需要借助条件熵(Conditional Entropy)的概念。条件熵在Softmax激活函数与最大熵原理之间关系中介绍过,它表示已知随机变量
X
mathcal X
X确定的条件下,随机变量
Y
mathcal Y
Y的不确定性的度量:
H
(
Y
∣
X
)
=
∑
i
=
1
n
p
i
⋅
H
(
Y
∣
X
=
x
i
)
mathcal H(mathcal Y mid mathcal X) = sum_{i=1}^{n} p_i cdot mathcal H(mathcal Y mid mathcal X = x_i)
H(Y∣X)=i=1∑npi⋅H(Y∣X=xi)
信息增益(Information Gain)则表示 给定特征 A mathcal A A的条件下,使得类 Y mathcal Y Y不确定性减少的程度。
从公式的角度观察,信息增益可看作是两种熵的差值结果。具体是哪两种熵?
假设当前存在某子集合
D
mathcal D
D,选择某一特征
A
mathcal A
A,并基于特征进行划分,从而得到若干个新的子集合。
- 第一种熵是子集合 D mathcal D D自身的熵 H ( D ) mathcal H(mathcal D) H(D)的结果;
- 第二种熵是子集合 D mathcal D D在特征 A mathcal A A干预(以特征 A mathcal A A作为条件)的情况下,子集合 D mathcal D D的熵的结果 H ( D ∣ A ) mathcal H(mathcal D mid mathcal A) H(D∣A);
那么信息增益
G
(
D
,
A
)
mathcal G(mathcal D,mathcal A)
G(D,A)可表示为:
G
(
D
,
A
)
=
H
(
D
)
−
H
(
D
∣
A
)
mathcal G(mathcal D,mathcal A) = mathcal H(mathcal D) - mathcal H(mathcal D mid mathcal A)
G(D,A)=H(D)−H(D∣A)
实际上,我们可以单纯地将信息增益看作是 在特征 A mathcal A A干预前与干预后,子集合 D mathcal D D熵值的变化情况。
信息增益
G
(
D
,
A
)
mathcal G(mathcal D,mathcal A)
G(D,A)的大小是基于数据集的训练过程而言。当特征选择的过程中,训练数据集的熵
H
(
D
)
mathcal H(mathcal D)
H(D)较大的时候,在特征
A
mathcal A
A选择时,对应的信息增益值
G
(
G
,
A
)
mathcal G(mathcal G,mathcal A)
G(G,A)会偏大;反之,
G
(
G
,
A
)
mathcal G(mathcal G,mathcal A)
G(G,A)会偏小。
基于‘信息增益’的算法被称为ID3算法;
可以使用信息增益率可以对信息增益结果进行矫正。信息增益率
G
R
(
D
,
A
)
mathcal G_{mathcal R}(mathcal D,mathcal A)
GR(D,A)定义为:信息增益
G
(
D
,
A
)
mathcal G(mathcal D,mathcal A)
G(D,A)与数据集的熵
H
(
D
)
mathcal H(mathcal D)
H(D)之间的比值:
基于‘信息增益率’的算法被称为C4.5算法;
G
R
(
D
,
A
)
=
G
(
D
,
A
)
H
(
D
)
mathcal G_{mathcal R}(mathcal D,mathcal A) = frac{mathcal G(mathcal D,mathcal A)}{mathcal H(mathcal D)}
GR(D,A)=H(D)G(D,A)
决策树的构建实例
观察如下数据集:
| 编号 | 天气( W e a t h e r Weather Weather) | 气温( T e m p e r a t u r e Temperature Temperature) | 湿度( h u m i d t y humidty humidty) | 风量( W i n d y Windy Windy) | 是否出去游玩( l a b e l label label) |
|---|---|---|---|---|---|
| 1 | 晴 | 热 | 高 | 无 | 否 |
| 2 | 晴 | 热 | 高 | 有 | 否 |
| 3 | 阴 | 热 | 高 | 无 | 是 |
| 4 | 雨 | 温和 | 高 | 无 | 是 |
| 5 | 雨 | 冷 | 正常 | 无 | 是 |
| 6 | 雨 | 冷 | 正常 | 有 | 否 |
| 7 | 阴 | 冷 | 正常 | 有 | 是 |
| 8 | 晴 | 温和 | 高 | 无 | 否 |
| 9 | 晴 | 冷 | 正常 | 无 | 是 |
| 10 | 雨 | 温和 | 正常 | 无 | 是 |
| 11 | 晴 | 温和 | 正常 | 有 | 是 |
| 12 | 阴 | 温和 | 高 | 有 | 是 |
| 13 | 阴 | 热 | 正常 | 无 | 是 |
| 14 | 雨 | 温和 | 高 | 有 | 否 |
首先观察:数据集合 D mathcal D D中一共包含 14 14 14个数据,其中 不出去游玩(标签是否,后同)共包含 5 5 5个数据;相反,标签为是共包含 9 9 9个数据。
因此,在 没有选择任何特征选择的条件下,该数据集合的熵
H
(
D
)
mathcal H(mathcal D)
H(D)表示如下:
H
(
D
)
=
−
1
×
(
9
14
log
9
14
+
5
14
log
5
14
)
≈
0.6517
mathcal H(mathcal D) = -1 times left(frac{9}{14} log frac{9}{14} + frac{5}{14} log frac{5}{14}right) approx 0.6517
H(D)=−1×(149log149+145log145)≈0.6517
首先以天气(
W
e
a
t
h
e
r
Weather
Weather)作为选择的特征进行划分。观察,天气特征服从
C
a
t
e
g
o
r
i
c
a
l
Categorical
Categorical分布,共存在3种选择:晴、阴、雨。特征选择结束后,其得到的基于样本编号的树状结构如下:
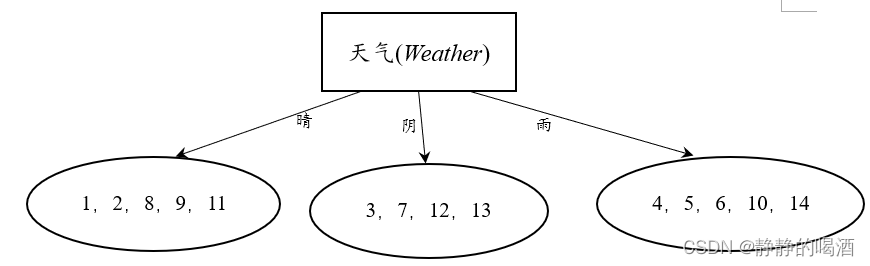
上图中各样本对应的标签结果如下:
其中1表示‘是’,0表示‘否’。
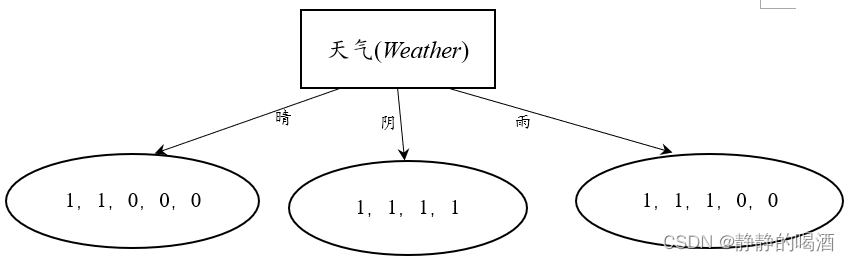
- 分别计算选择晴、阴、雨三种特征对应子集的熵值结果:
其中A mathcal A A表示特征选择‘天气’
H ( D 1 ∣ A ) = − 1 × ( 2 5 log 2 5 + 3 5 log 3 5 ) ≈ 0.6730 H ( D 2 ∣ A ) = 0 H ( D 3 ∣ A ) = − 1 × ( 2 5 log 2 5 + 3 5 log 3 5 ) ≈ 0.6730 begin{aligned} mathcal H(mathcal D_1mid mathcal A) & = -1 times left(frac{2}{5} log frac{2}{5} + frac{3}{5} log frac{3}{5} right) approx 0.6730 \ mathcal H(mathcal D_2 mid mathcal A) & = 0 \ mathcal H(mathcal D_3 mid mathcal A) & = -1 times left(frac{2}{5} log frac{2}{5} + frac{3}{5} log frac{3}{5} right) approx 0.6730 end{aligned} H(D1∣A)H(D2∣A)H(D3∣A)=−1×(52log52+53log53)≈0.6730=0=−1×(52log52+53log53)≈0.6730
至此,我们可以计算被特征选择天气干预后,数据集合
D
mathcal D
D的熵值结果
H
(
D
∣
A
)
mathcal H(mathcal D mid mathcal A)
H(D∣A):
其中‘晴天’被选择的概率是
5
14
frac{5}{14}
145,阴天被选择的概率是
4
14
frac{4}{14}
144,雨天被选择的概率是
5
14
frac{5}{14}
145
H
(
D
∣
A
)
=
∑
i
=
1
3
p
i
⋅
H
(
D
∣
A
=
a
i
)
=
p
1
⋅
H
(
D
1
∣
A
)
+
p
2
⋅
H
(
D
2
∣
A
)
+
p
3
⋅
H
(
D
3
∣
A
)
=
5
14
×
0.6730
+
4
14
×
0
+
5
14
×
0.6730
≈
0.4807
begin{aligned} mathcal H(mathcal D mid mathcal A) & = sum_{i=1}^3 p_i cdot mathcal H(mathcal D mid mathcal A = a_i) \ & = p_1 cdot mathcal H(mathcal D_1 mid mathcal A) + p_2 cdot mathcal H(mathcal D_2 mid mathcal A) + p_3 cdot mathcal H(mathcal D_3 mid mathcal A)\ & = frac{5}{14} times 0.6730 + frac{4}{14} times 0 + frac{5}{14} times 0.6730 approx 0.4807 end{aligned}
H(D∣A)=i=1∑3pi⋅H(D∣A=ai)=p1⋅H(D1∣A)+p2⋅H(D2∣A)+p3⋅H(D3∣A)=145×0.6730+144×0+145×0.6730≈0.4807
计算
H
(
D
)
mathcal H(mathcal D)
H(D)与
H
(
D
∣
A
)
mathcal H(mathcal D mid mathcal A)
H(D∣A)之间的差异,即信息增益:
G
(
D
,
A
)
=
H
(
D
)
−
H
(
D
∣
A
)
≈
0.1710
mathcal G(mathcal D,mathcal A) = mathcal H(mathcal D) - mathcal H(mathcal D mid mathcal A) approx 0.1710
G(D,A)=H(D)−H(D∣A)≈0.1710
综上,我们已经计算了关于执行将天气作为特征选择 的信息增益。同理,我们依次计算气温,湿度,风量对应作为特征选择后的信息增益(遍历所有特征),最终选择信息增益最大的结果作为特征选择的结果,对样本集合进行划分。
在特征选择结束之后,将该特征从列表中剔除。一旦作为特征选择,不会再次使用。因此,决策树中只包含一次相应特征。
信息增益率与GINI系数
ID3决策树算法的问题与解决方式
上面基于信息增益的计算方式就是典型的ID3决策树算法。
基于上述例子,假设我们将数据集合中的样本编号 也作为一个特征,由于编号不存在重复的问题,因而如果将编号作为特征进行选择,必然会出现
14
14
14个分支,并且每个分支仅存在唯一一个样本。
那么计算每一个样本的熵值时,我们发现:由于只有一个样本,因而它不存在任何混乱情况,因此其熵值
=
0
=0
=0恒成立。
因而,在决策树做选择的过程中,它会认为编号特征是一个极其优秀的特征,因为他的熵值永远为零,从而信息增益总是最大的。因此,最终的决策树会以编号特征作为根节点,得到一棵 N N N叉树( N N N表示样本数量)。
这棵树明显不是我们想要的结果。当然,我们更多考虑的是和编号特征非常类似的稀疏特征:该特征的种类非常繁多,属于某一种类的样本非常稀少,此时的信息增益 G ( D , A ) mathcal G(mathcal D,mathcal A) G(D,A)就没有办法很好地选择正确的特征,从而构建一棵优秀的决策树。
关于ID3决策树算法的问题,提出了信息增益率的思想。继续观察,依然假设使用编号特征进行了特征选择,对应的熵值结果由0.6517降至为0,得到0.6517的增益结果。但与之增长的还有执行特征选择后的熵值结果:
∑
i
=
1
14
(
−
1
14
log
1
14
)
=
−
log
1
14
≈
2.6391
sum_{i=1}^{14} left(-frac{1}{14} log frac{1}{14}right) = -log frac{1}{14} approx 2.6391
i=1∑14(−141log141)=−log141≈2.6391
信息增益率就是对稀疏特征的一个矫正:上述稀疏特征对应的信息增益率是极低的:
0.6517
2.6391
=
0.2469
frac{0.6517}{2.6391} = 0.2469
2.63910.6517=0.2469
因此,C4.5算法就是将信息增益率替代信息增益来执行特征选择过程。它是一种信息增益出现上述问题的一种解决方案。
关于GINI系数
GINI系数的表达式如下所示:
G
i
n
i
(
p
)
=
∑
k
=
1
K
p
k
(
1
−
p
k
)
=
1
−
∑
k
=
1
K
p
k
2
Gini(p) = sum_{k=1}^{mathcal K} p_k(1 - p_k) = 1 - sum_{k=1}^{mathcal K} p_k^2
Gini(p)=k=1∑Kpk(1−pk)=1−k=1∑Kpk2
观察,假设某一特征结果 k k k对应的样本量极高,对应的概率结果 p k → 1 p_kto 1 pk→1,则 G i n i ( p k ) → 0 Gini(p_k) to 0 Gini(pk)→0。从单调性的角度,意味着 G i n i Gini Gini系数存在着和熵相似的性质。
G i n i Gini Gini系数表示集合的不确定性,即 G i n i Gini Gini系数越大,集合的不确定性越高,不纯度也越大。
相关参考:
【机器学习实战】3、决策树
唐宇迪大佬视频-决策树
最后
以上就是风中铃铛最近收集整理的关于机器学习笔记之决策树算法(一)基本介绍引言的全部内容,更多相关机器学习笔记之决策树算法(一)基本介绍引言内容请搜索靠谱客的其他文章。








发表评论 取消回复