最近在准备立项的事情,所以看一些应用相关的文章。
摘要
作者首创性的将GAN模型应用于模拟人的视觉的注意力机制,预测图像中容易受到人关注的部分。
视觉注意力机制
参考https://blog.csdn.net/SoyCoder/article/details/82055717
模型结构
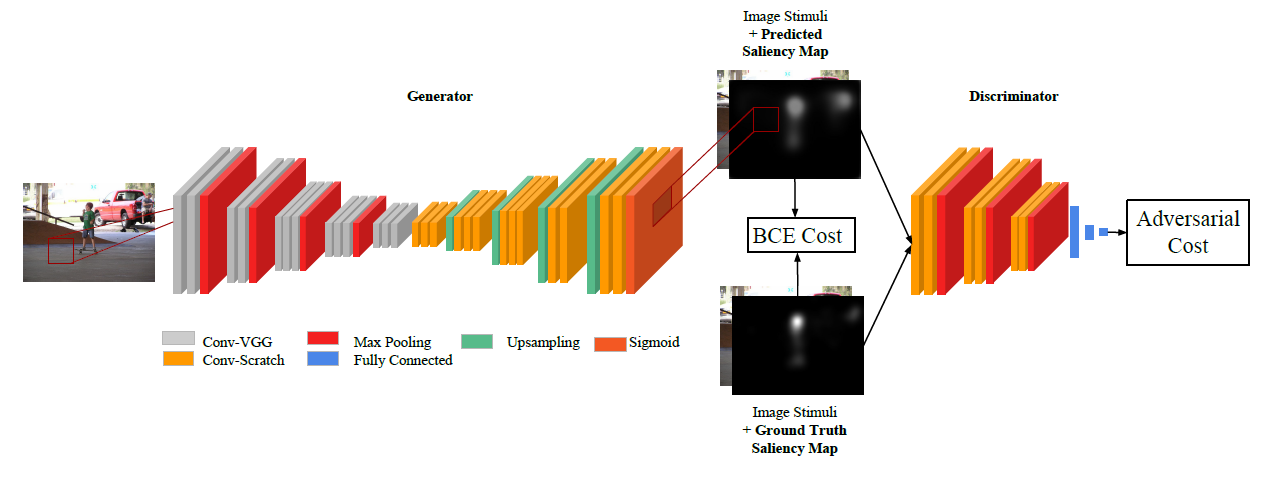
生成器:卷积编解码架构,和VGG-16模型几乎完全一致,只删除了最后的池化层和全连接层。
判别器:CNN结构
训练
主要有两个损失函数
1.内容损失
内容损失是将生成器生成的显著性预测图与在真实图片上人工标注的显著性图比较得来。
内容损失是按像素来计算的,两张图对应像素点之间计算它们之间的均方差(MSE),也就是欧氏距离:

我们将真实的显著性图归一化使得
S
j
S_j
Sj的每个值都在[0,1]之间,因此显著性值
S
j
S_j
Sj可以解释为特定像素被观察者注意到的概率估计。但是,观察者注意到的可能不只有仅仅一个像素,因此更合理的做法是将每个预测值
s
^
j
hat{s}_j
s^j视为独立于其他预测值。因此作者对最后一层的每个输出应用一个元素级(element-wise)的sigmoid,这样就可以将像素级的预测看作是独立二进制随机变量的概率。在这种情况下,采用二进制交叉熵更为合适,它是所有像素上单个二进制交叉熵(BCE)的平均值:
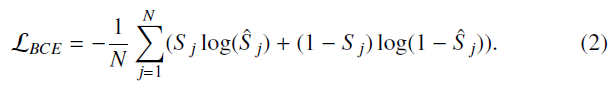
2.对抗损失
显著性预测和以往的GAN模型的对抗损失有几点不同:
①目标是拟合一个决策函数来产生实际的显著性值,而不是从随机的noise 中得到真实的图像;这样的话,输入给生成器的东西就不再是随机的noise,而是一张图像。
②生成器的目标不仅是使生成的显着性图变得和真实的显著性图难以区分,而且要使它们都对应于同一输入图像;因此将图片和显著图都作为判别器的输入。
③当生成器生成逼真的图像时,没有ground truth进行对比,属于无监督学习,但是,生成的视觉显著性预测图是有人工标注的显著性图可对比的。
在对生成函数的参数进行更新时,作者发现使用判别器的误差与交叉熵相对于Ground Truth的组合方式的损失函数,可以提高了对抗性训练的稳定性和收敛速度,因此对抗性训练中SalGAN的最终损失函数可表示为

这里的L是二进制交叉熵损失函数,
D
(
I
,
S
^
)
D(I,hat{S})
D(I,S^)是判别器被欺骗的概率,1是样本为真,0是样本为假,使用
L
(
D
(
I
,
S
^
)
,
1
)
L(D(I,hat{S}),1)
L(D(I,S^),1)而不是
L
(
D
(
I
,
S
^
)
,
0
)
L(D(I,hat{S}),0)
L(D(I,S^),0)可以提供更强的梯度。这样做使得一开始判别器不太会被欺骗的时候与预测显著性相关的损失会变得更大。
判别器的损失:
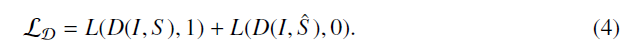
实验


最后
以上就是潇洒石头最近收集整理的关于《SalGAN: visual saliency prediction with adversarial networks》学习笔记的全部内容,更多相关《SalGAN:内容请搜索靠谱客的其他文章。
![Adversarial Nets Papers
AdversarialNetsPapers
The classical Papers about adversarial nets
The First paper
[Generative Adversarial Nets] [Paper] [Code](the first paper abou](https://www.shuijiaxian.com/files_image/reation/bcimg11.png)







发表评论 取消回复