我是靠谱客的博主 迷路期待,这篇文章主要介绍Paper Reading: SalGAN: visual saliency prediction with adversarial networks,现在分享给大家,希望可以做个参考。
Paper Reading Note
URL:
https://arxiv.org/pdf/1701.01081.pdf
TL;DR
本文是18年cviu的一篇文章,主要是用GAN作显著点检测的任务,模型很简单,可以参考其利用GAN增强的思想。

如上图所示,对一副图像的关键点检测,本文的检测方法效果明显优于传统的交叉熵方法。
Algorithm
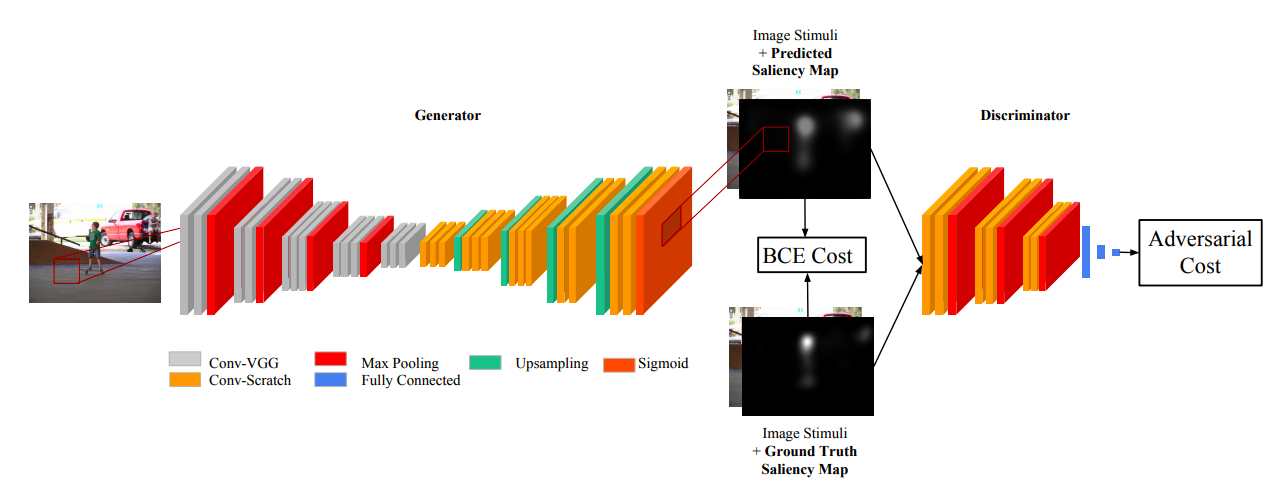
模型框架如上图所示,主要由一个generator和discriminator组成。
- generator部分采用了去除最后两层的vgg-16,一部分作为encoder(Conv-VGG)一部分作为decoder(Conv-Scratch)。
- 将生成的feature map和ground truth做pixel-wise的BCE Loss:
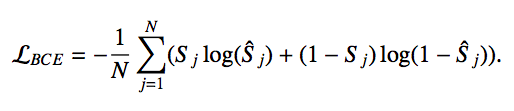
- 一般模型到这一步就结束了,本文提出了在此基础上添加一个discriminator对生成的模型和ground truth进行判别,相当于添加了discriminator传来的loss:
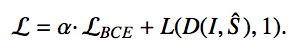
- 对于discriminator的训练还是跟基本的GAN没有区别:
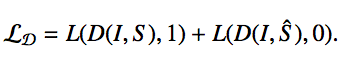
Results
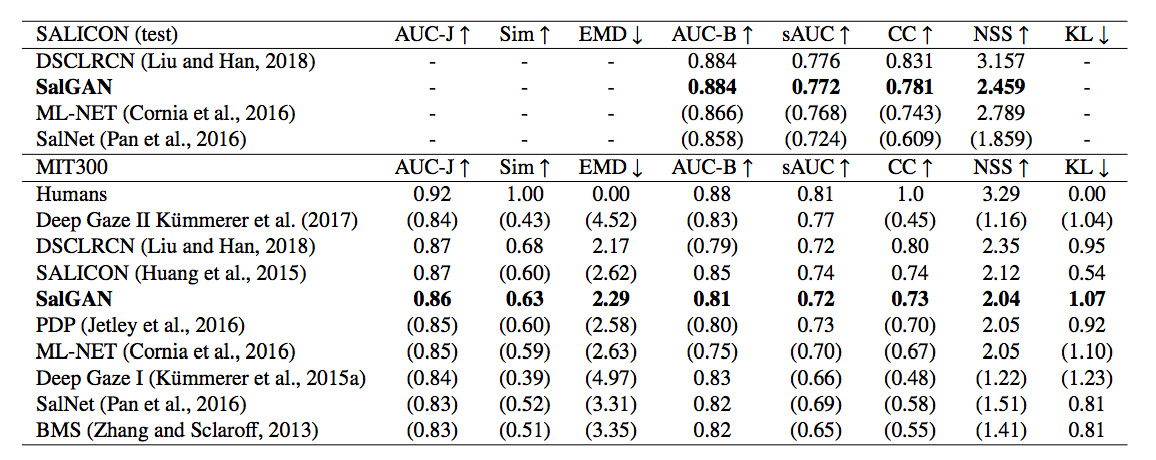
这个模型跟许多SOTA方法比起来效果都可以,不过被近期的几个方法给压制了。

最后模型还给出了传统方法和GAN网络生成的图进行比较,可以看到GAN网络的图像更加平滑了。
Thoughts
对关键点检测不是很熟悉,但是从本文的模型看来十分简单。不过这也启发了几乎大部分的encoder-decoder模型都可以用GAN来辅助。
最后
以上就是迷路期待最近收集整理的关于Paper Reading: SalGAN: visual saliency prediction with adversarial networks的全部内容,更多相关Paper内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复