CVPR 2019 《SalGAN: visual saliency prediction with adversarial networks》

传统的解决视觉显著性预测的工作往往只是基于单方面的设计针对于显著性预测的损失函数,这样的方式得到的结果往往在选定的度量方式上表现良好,但可能换种度量方式来看,表现就不一定也是好的了。因此,作者将GAN的思想引入到了视觉显著性问题中,提出了一种基于数据驱动度量的显著性预测方法——SalGAN(Saliency GAN)。SalGAN由两个网络组成:
- 生成器(Generator):从输入图像的原始像素预测显著性映射;
- 判别器(Discriminator):使用第网络的输出来区分显著性映射是预测的还是真实的
视觉注意机制
视觉显著性(Visual Saliency Detection )是指对于真实世界中的场景,人们会自动的识别出感兴趣区域(region of interesting),并对感兴趣的区域进行处理忽略掉不感兴趣的区域。比较典型的视觉显著性的标注为下图所示

人类的视觉注意机制有两个策略:自底向上、自顶向下
-
自底向上(Bottom-up method):自底向上的方法是由图像本质特征引起的视觉注意,它是由底层感知数据驱动的。譬如,颜色,亮度,方向等一系列图像特征。由图像底层数据可知,不同区域内具有很强的特征差异性,通过判断目标区域和它周围像素的差异,进而计算图像区域的显著性。
-
自顶向下(Top-down method):自顶向下的方法是基于任务驱动性的注意力显著性机制,它是由任务经验来驱动视觉注意的,通过知识来预期当前图像的目标显著性的区域。例如,在景区,你同学戴了一顶黑色帽子,你在寻找你同学时候,会首先注意黑色帽子这个显著特征。
https://blog.csdn.net/SoyCoder/article/details/82055717
关于视觉显著性预测方面的很多工作都是希望通过设计好的损失函数来训练模型,从而达到不错的效果。但是由于不同的人的想法不同,关于显著性效果的好坏就难以用一个统一的方式进行度量。所以作者摒弃了复杂的损失函数的设计工作,使用对抗的思想,希望生成器可以通过对抗生成接近真实的saliency map。
模型整体上使用的也是Encoder-Decoder的架构,示意图如下所示:
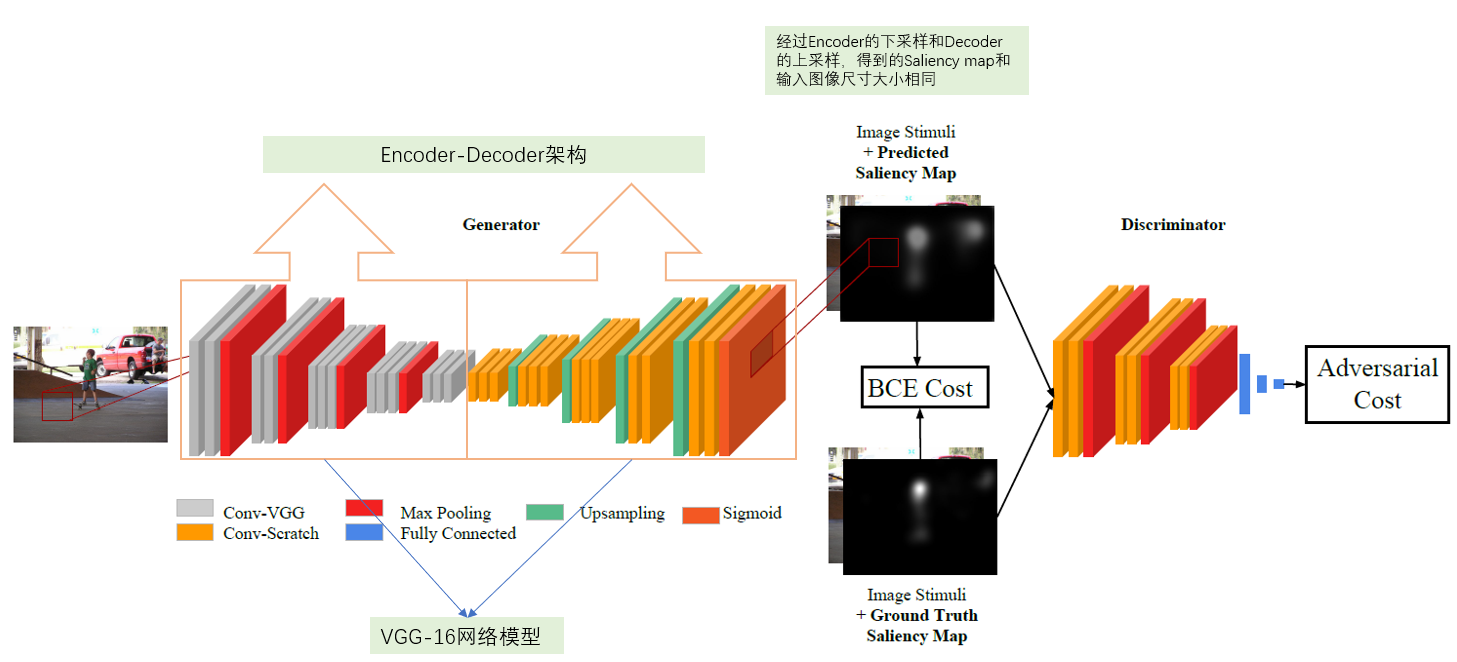
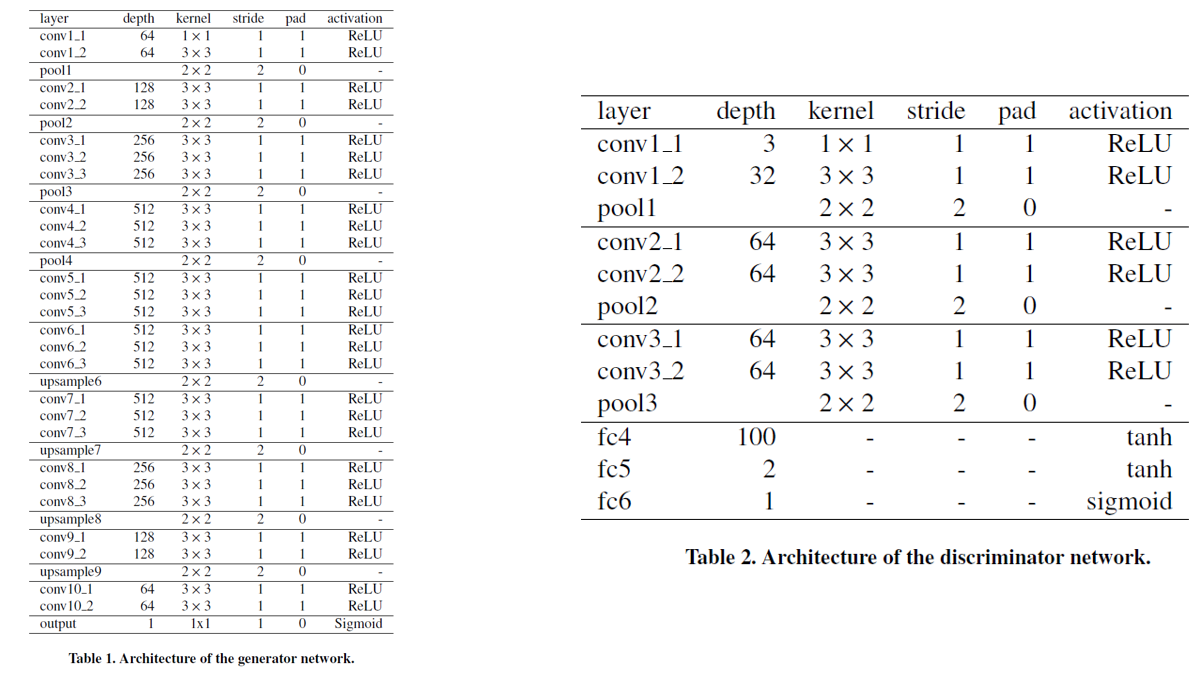
模型整体的架构并不复杂,主要使用了VGG-16的预训练模型,详细架构如下所示
模型所使用的损失函数主要有两个:
-
Content loss:由于在生成显著图的过程中可能会有多个像素参与,因此将每个预测值视为独立于其他预测值更合适。故作者建议对最后一层的每个输出应用一个元素级(element-wise)的sigmoid,这样就可以将像素级的预测看作是独立二进制随机变量的概率。在这种情况下,一个适当的损失是二进制交叉熵,它是所有像素上单个二进制交叉熵(BCE)的平均值 L B C E = − 1 N ∑ j = 1 N ( S j log ( S ^ j ) + ( 1 − S j ) log ( 1 − S ^ j ) ) mathcal{L}_{B C E}=-frac{1}{N} sum_{j=1}^{N}left(S_{j} log left(hat{S}_{j}right)+left(1-S_{j}right) log left(1-hat{S}_{j}right)right) LBCE=−N1j=1∑N(Sjlog(S^j)+(1−Sj)log(1−S^j))
-
Adversarial loss:在对生成函数的参数进行更新时,作者发现使用判别器的误差与交叉熵相对于Ground Truth的组合方式的损失函数,可以提高了对抗性训练的稳定性和收敛速度,因此对抗性训练中SalGAN的最终损失函数可表示为 L = α ⋅ L B C E + L ( D ( I , S ^ ) , 1 ) mathcal{L}=alpha cdot mathcal{L}_{B C E}+L(D(I, hat{S}), 1) L=α⋅LBCE+L(D(I,S^),1) 判别器的损失函数如下所示 L D = L ( D ( I , S ) , 1 ) + L ( D ( I , S ^ ) , 0 ) mathcal{L}_{mathcal{D}}=L(D(I, S), 1)+L(D(I, hat{S}), 0) LD=L(D(I,S),1)+L(D(I,S^),0)
实验
经过实验证明,上述损失函数中的超参数 α = 0.005 alpha = 0.005 α=0.005时,模型的效果最好
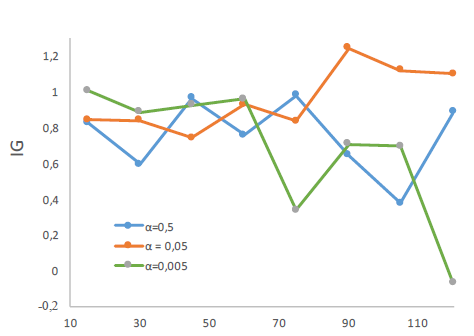
而且优于已有的模型
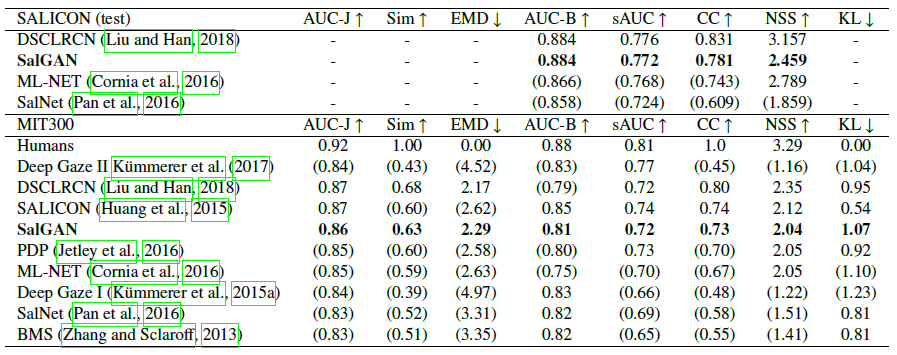
可视化的效果图如下所示,从中我们可以看出SalGAN得到的显著图更加接近真实(Ground Truth)

总结
整体来看,作者主要是首创性的使用了GAN来解决视觉显著性问题,其他没有什么特别吸引人的地方(可能是鄙人才疏学浅,未能看出)。
最后
以上就是朴素向日葵最近收集整理的关于SalGAN的全部内容,更多相关SalGAN内容请搜索靠谱客的其他文章。

![Adversarial Nets Papers
AdversarialNetsPapers
The classical Papers about adversarial nets
The First paper
[Generative Adversarial Nets] [Paper] [Code](the first paper abou](https://www.shuijiaxian.com/files_image/reation/bcimg11.png)






发表评论 取消回复