论文链接:
[2203.00867] Incremental Transformer Structure Enhanced Image Inpainting with Masking Positional Encoding (arxiv.org)
代码链接:
DQiaole/ZITS_inpainting: Incremental Transformer Structure Enhanced Image Inpainting with Masking Positional Encoding (CVPR2022) (github.com)
本文创新点:使用transformer对图像结构进行修复,作为修复图像的辅助信息;
网络结构
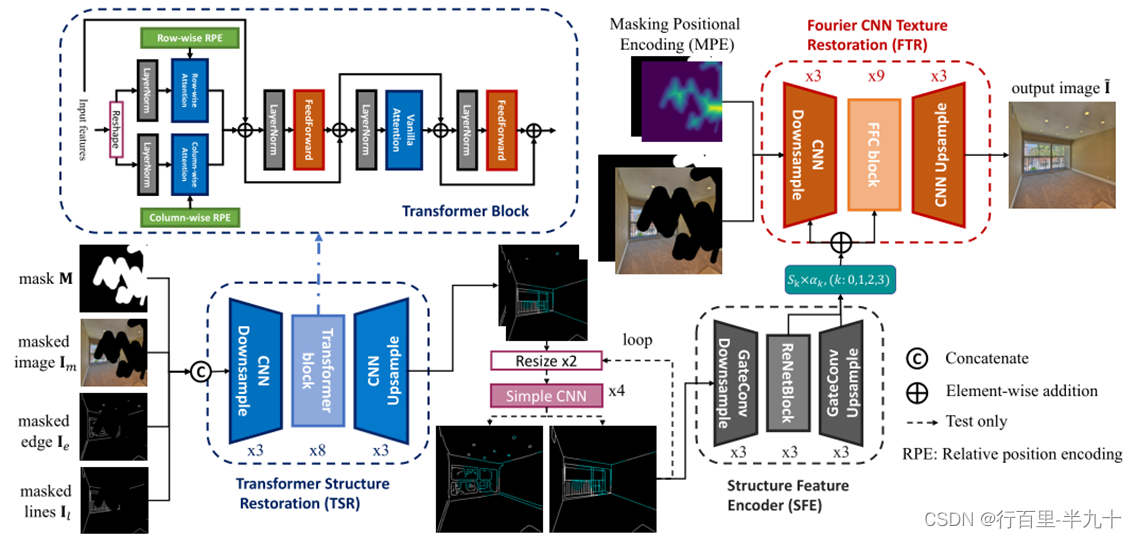
Transformer Structure Restoration
为了减少计算复杂度,交替使用轴向注意力和标准注意力。标准的注意力的计算复杂度为![]() ,而轴向注意力的计算复杂度为
,而轴向注意力的计算复杂度为![]() 。
。
轴向注意力
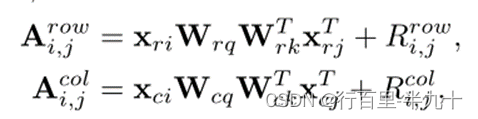
其中,![]() 、
、![]() 为X 的第 i、j 行特征向量,
为X 的第 i、j 行特征向量,![]() 、
、![]() 为X 的第 i、j 列特征向量,
为X 的第 i、j 列特征向量,![]() 为第 i 行和第 j 行之间的相对位置编码。
为第 i 行和第 j 行之间的相对位置编码。
使用二元交叉熵进行优化,
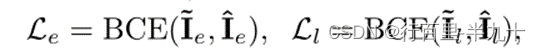
其中,![]() 和Il
和Il![]() 为ground truth。
为ground truth。
Simple Structure Upsampler
首先对线条进行上采样,然后通过网络的泛化得到高分辨率的边缘图。
ZeroRA Structure Enhanced Inpainting
Fourier CNN Texture Restoration (FTR)
FTR主要由下采样、自编码器和上采样三个部分构成。关键模块是Fast Fourier Convolution (FFC) layer,主要有两个分支:一个是局部分支使用常规卷积,另一个是全局分支在快速傅里叶变换后对特征进行卷积。
Structure Feature Encoder (SFE)
SFE是一个自编码器模型,主要由 3 层下采样门控卷积(编码器)、3层带扩张卷积的残差块和3层上采样门控卷积(解码器)。门控卷积选择性地传输有用的特征,输入到 FTR。
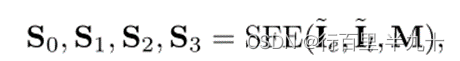
其中,S为最后一个残差块和3个解码器层从粗到精的特征映射。
Masking Positional Encoding (MPE).
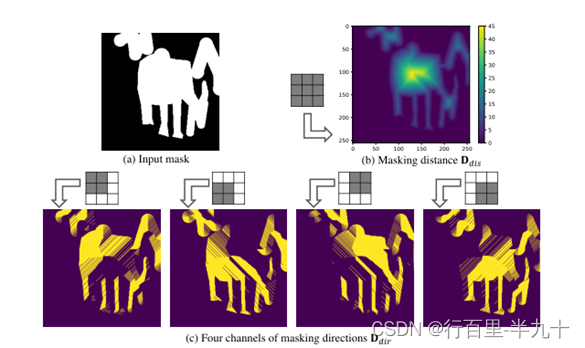
用全为1的3*3卷积核计算每个位置的掩码距离Ddis,通过正弦位置编码(SPE)对距离进行裁剪和映射得到 ![]()
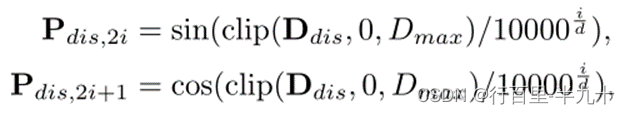
其中,i为通道索引,Dmax=128,d=64,为Pdis总通道数。
对于掩码方向,用4个不同的二进制卷积核来获得4通道one-hot向量![]() 。
。
Ddir 的值取决于哪个卷积核首先覆盖掩码区域。Ddir表示从掩码位置到未掩码位置的最近方向。然后将Ddir投影到具有d维特征的参数空间![]() 。
。
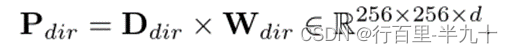
Zero-initialized Residual Addition (ZeroRA)
对于给定的输入特征x,经过跳跃连接,得到输出特征x' 。

其中,α从零初始化。
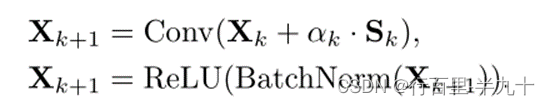
在本文中用ZeroRA 将结构信息从SFE添加到FTR
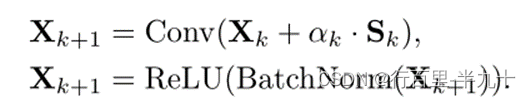
最后
以上就是隐形月饼最近收集整理的关于论文阅读——Incremental Transformer Structure Enhanced Image Inpainting with Masking Positional Encoding网络结构 的全部内容,更多相关论文阅读——Incremental内容请搜索靠谱客的其他文章。








发表评论 取消回复