Face ++在COCO竞赛中大放异彩,在多个领域获得COCO 2017的冠军。其中,由彭超研究院带领的检测团队获得了检测项目的冠军。同时,对应论文也发表在CVPR 2018上,属于spotlight论文。
论文标题:MegDet: A Large Mini-Batch Object Detector》
论文地址:https://arxiv.org/pdf/1711.07240.pdf
摘要
MegDet将batch size增加到了256,这对于主流检测网络来说(faster r-cnn/retinaNet等)是一个巨型的batch size。
MegDet的backbone用的使resnet-50,在backbone上没有什么创新。这个目前检测领域最强的模型的创新点集中在mini-batch上。
用超大的mini-batch size,有以下直接好处:
- 可以并行训练,用128块GPU训练这256的batch,这样将训练时间大大缩短(33h -> 4h).
- batch normalization的效果更好,一个超大的batch-size意味着一个超强的BN。对于全局BN的获取,文章中提出了一个CGBN,即跨越GPU获得一个全局的BN。对于BN有疑问的可以转《batch normalization》.
其实看到这里,就已经完全掌握了论文中的创新点。可以继续往下看细节
大batch和小batch的效果差异
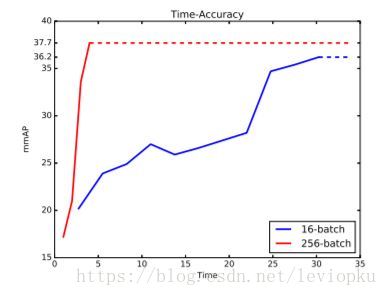
上图比较了batch size为256和16的情况,明显可以看到,超大的batch size会使网络收敛得更快,而且效果更佳。
文章中提到下列现象和原因:
- 小batch训练时间长到难以忍受;(比如resnet-152在COCO数据集上用8块泰坦XP还训练了3天)
- 小batch不足以提供准确得数据分布统计给BN层。
- 小batch的正负样本很难平衡,如果训练时正负样本不均匀也会损害训练效果。(有石锤说明的)
等价学习率原则
对于之前他人的经验,有一个“等价学习率原则”。即,如果你的batch size比较大,那你需要一个更大的学习率才能保证你的准确率。
事实上,在检测任务中,如果直接遵循这个原则,可能导致训练结果不收敛的后果。
于是,MegDet改进了这个原则,借鉴了“warmup”学习率策略。热身策略,即一开始用比较小的学习率,待“热身”起来,慢慢增大学习率。这样,既可以获得很高的准确率,又可以避免模型训练不收敛。
Cross-GPU Batch Normalization (CGBN)
前面说到,Meg对于一个batch(256)的计算分部在128块GPU上,如果想取得一个全局的BN,那必须跨越GPU来求得。
这个策略也是很简单的,看图:
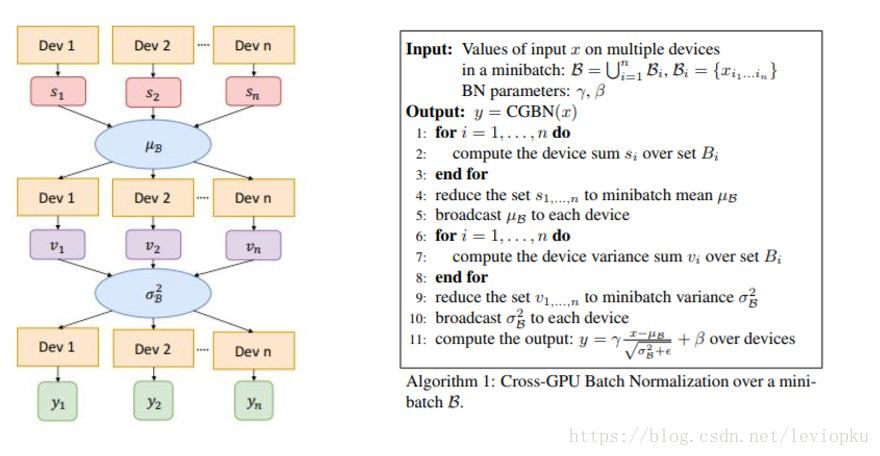
只是在BN的基础上加了一个GPU间通信,求一个全局的平均数
μ
mu
μ,一个全局的方差
σ
2
sigma^2
σ2,再根据
μ
mu
μ和
σ
2
sigma^2
σ2进行标准化。最后,通过可学习参数
γ
gamma
γ和
β
beta
β对标准化结果进行一个线性变换。为什么要这么做?因为这就是BN的做法,不解可移步《batch normalization》。
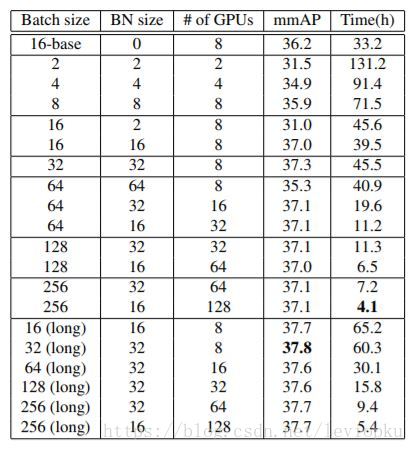
当然,CGBN操作也不一定需要求得全局BN,我们也可以定义不同的BN size。作者对不同的BN size对效果的影响也做了一些实验:
最后
以上就是辛勤画笔最近收集整理的关于MegDet论文详解(coco2017检测冠军)的全部内容,更多相关MegDet论文详解(coco2017检测冠军)内容请搜索靠谱客的其他文章。








发表评论 取消回复