文件是怎么存储到文件系统中的?
假如要存储a.txt到/tmp目录下。下面就实际模拟一下存储的过程。
一个完成的文件系统
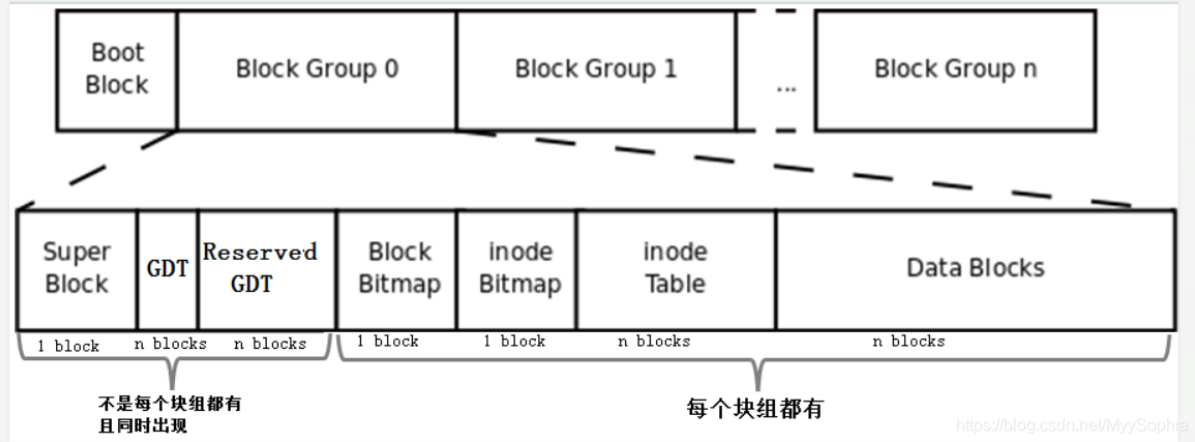
针对某一个block group来说对文件的删除和存储过程如下
一个大文件是完全有可能跨block group的。
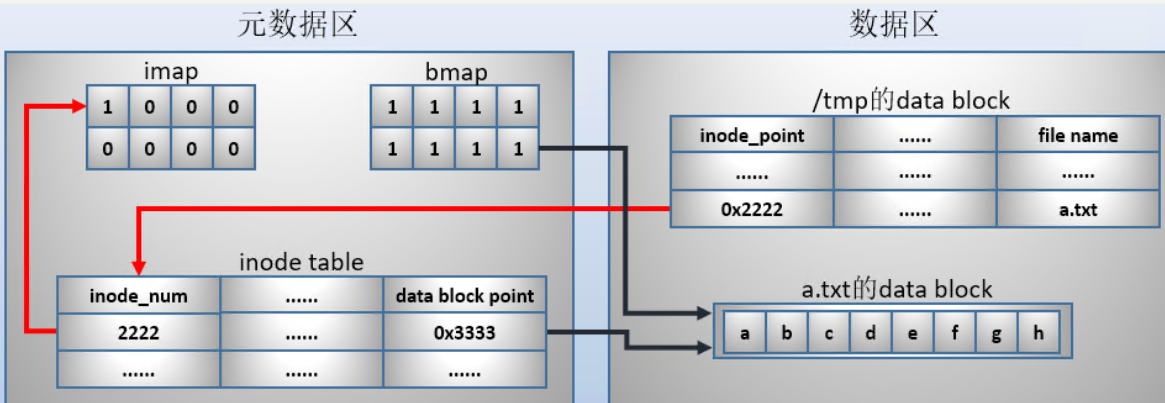
当a.txt文件要存储到/tmp下时:
- (1).首先从inode table中找一个空闲的inode号分配给a.txt,例如2222。再将inode map(imap)中2222这个inode号标记为已使用。
- (2).在/tmp的data block中添加一条a.txt文件的记录。该记录中包括一个指向inode号的指针,例如"0x2222"。
- (3).然后从block map(bmap)中找出空闲的data block,并开始将a.txt中的数据写入到data block中。每写一段空间(ext4每次分配一段空间)就从bmap中找一次空闲的data block,直到存完所有数据。
- (4).设置inode table中关于2222这条记录的data block指针,通过该指针可以找到a.txt使用了哪些data block。
当要删除a.txt文件时:
- (1).在inode table中删除指向a.txt的data block指针。这里只要一删除,外界就找不到a.txt的数据了。但是这个文件还存在,只是它是被"损坏"的文件,因为没有任何指针指向数据块。
- (2).在imap中将2222的inode号标记为未使用。于是这个inode号就被释放,可以被后续的文件重用。
- (3).删除父目录/tmp的data block中关于a.txt的记录。这里只要一删除,外界就看不到也找不到这个文件了。
- (4).在bmap中将a.txt占用的block标记为未使用。这里被标记为未使用后,这些data block就可以被后续文件覆盖重用。
考虑一种情况,当一个文件被删除时,但此时还有进程在使用这个文件,这时是怎样的情况呢?外界是看不到也找不到这个文件的,所以删除的过程已经进行到了第(3)步。但进程还在使用这个文件的数据,也能找到这个文件的数据,是因为进程在加载这个文件的时候就已经获取到了该文件占用哪些data block,虽然删除了文件,但bmap中这些data block还没有标记为未使用。
update 2022年1月14日15:29:12

什么是block group?
前面一直提到的优化方法是将文件系统占用的block划分成块组(block group),解决bmap、inode table和imap太大的问题。
在物理层面上的划分是将磁盘按柱面划分为多个分区,即多个文件系统;在逻辑层面上的划分是将文件系统划分成块组。每个文件系统包含多个块组,每个块组包含多个元数据区和数据区:元数据区就是存储bmap、inode table、imap等的数据;数据区就是存储文件数据的区域。注意块组是逻辑层面的概念,所以并不会真的在磁盘上按柱面、按扇区、按磁道等概念进行划分。
本文转载自: 详细分析du和df的统计结果为什么不一样 - 骏马金龙 - 博客园。仅限于学习交流,侵权必删。
-- update 2022年1月17日22:59:36
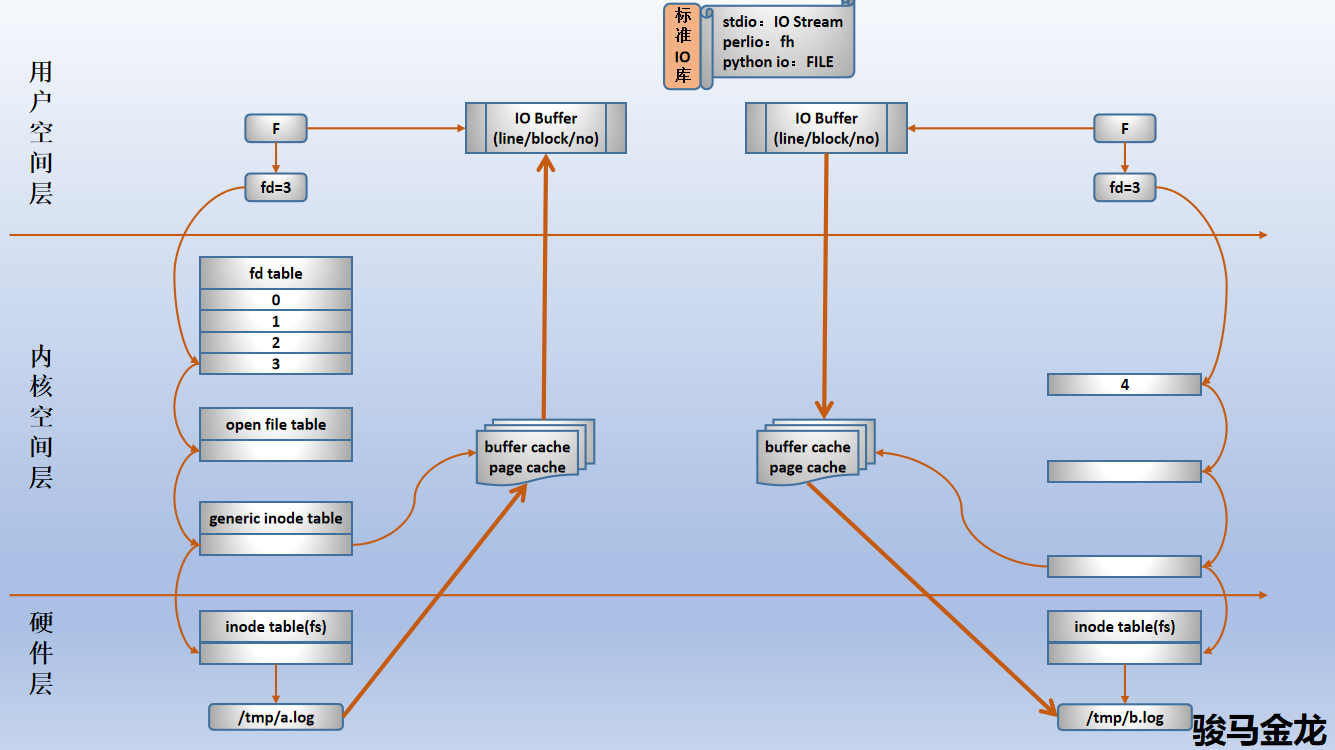
这张图表示了文件操作在各个层的数据结构的关联,能对着这张图将它们之间的关系讲清楚,对于文件系统的部分,你就会了然于心了。
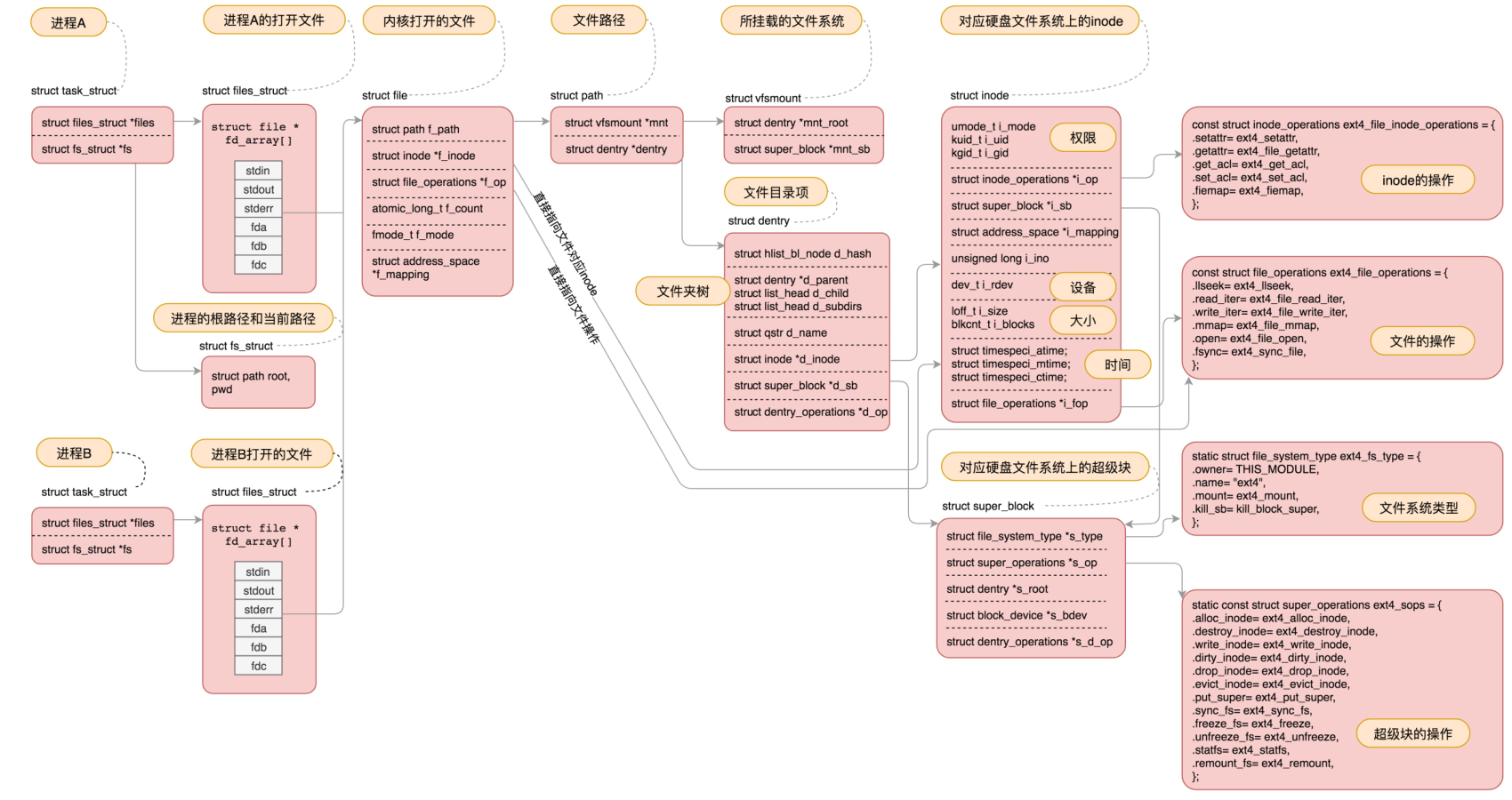
最后
以上就是幽默红酒最近收集整理的关于文件存储和删除的底层过程的全部内容,更多相关文件存储和删除内容请搜索靠谱客的其他文章。








发表评论 取消回复