Blending
Blending是一种模型融合方法,对于一般的Blending,主要思路是把原始的训练集先分成两部分,比如70%的数据作为新的训练集,剩下30%的数据作为测试集。第一层我们在这70%的数据上训练多个模型,然后去预测那30%数据的label。在第二层里,我们就直接用这30%数据在第一层预测的结果做为新特征继续训练即可。
如果你没懂,那么看下面这张超级可爱又超级直观的图:
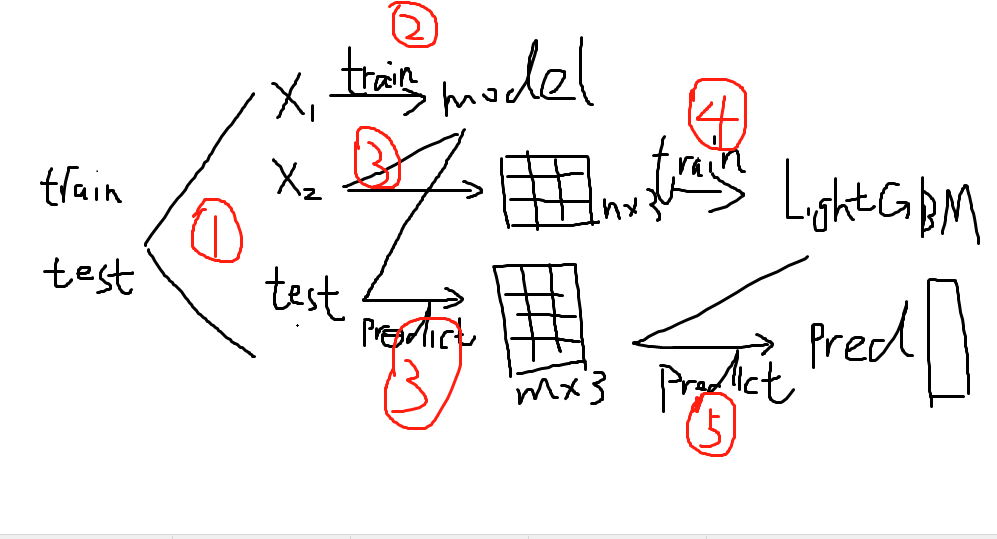
Blending的优点在于:
- 比stacking简单(因为不用进行k次的交叉验证来获得stacker feature)
- 避开了一个信息泄露问题:generlizers和stacker使用了不一样的数据集
而缺点在于:
- 使用了很少的数据(第二阶段的blender只使用training set10%的量)
- blender可能会过拟合
- stacking使用多次的交叉验证会比较稳健
对于实践中的结果而言,stacking和blending的效果是差不多的,所以使用哪种方法都没什么所谓,完全取决于个人爱好。
Blending与Stacking大致相同,只是Blending的主要区别在于训练集不是通过K-Fold的CV策略来获得预测值从而生成第二阶段模型的特征,而是建立一个Holdout集,例如说10%的训练数据,第二阶段的stacker模型就基于第一阶段模型对这10%训练数据的预测值进行拟合。说白了,就是把Stacking流程中的K-Fold CV 改成 HoldOut CV。
那么:
----------------------------------------------------------分割线-------------------------------------------------------------
第一阶段第一层:
#创建训练的数据集
#data, target = make_blobs(n_samples=50000, centers=2, random_state=0, cluster_std=0.60)
#模型融合中使用到的各个单模型
clfs = [LogisticRegression(),
RandomForestClassifier(n_estimators=5, n_jobs=-1, criterion='gini'),
RandomForestClassifier(n_estimators=5, n_jobs=-1, criterion='entropy'),
ExtraTreesClassifier(n_estimators=5, n_jobs=-1, criterion='gini'),
#ExtraTreesClassifier(n_estimators=5, n_jobs=-1, criterion='entropy'),
GradientBoostingClassifier(learning_rate=0.05, subsample=0.5, max_depth=6, n_estimators=5)]
#切分一部分数据作为测试集
X, X_predict, y, y_predict = train_test_split(data, target, test_size=0.33, random_state=2017)
#5折stacking
n_folds = 5
skf = list(StratifiedKFold(y, n_folds))
#StratifiedKFold用法类似Kfold,但是他是分层采样,确保训练集,测试集中各类别样本的比例与原始数据集中相同。
#切分训练数据集为d1,d2两部分
X_d1, X_d2, y_d1, y_d2 = train_test_split(X, y, test_size=0.5, random_state=2017)
dataset_d2 = np.zeros((X_d2.shape[0], len(clfs)))
dataset_predict = np.zeros((X_predict.shape[0], len(clfs)))
for j, clf in enumerate(clfs):
#依次训练各个单模型
clf.fit(X_d1, y_d1)
y_submission = clf.predict_proba(X_d2)[:, 1]
dataset_d2[:, j] = y_submission
#对于测试集,直接用这k个模型的预测值作为新的特征。
dataset_predict[:, j] = clf.predict_proba(X_predict)[:, 1]
#predict_proba返回的是一个 n 行 k 列的数组, 第 i 行 第 j 列上的数值是模型预测 第 i个预测样本为某个标签的概率,并且每一行的概率和为1。
print("val auc Score: %f" % roc_auc_score(y_predict, dataset_predict[:, j]))
第二阶段第二层:
#融合使用的模型
clf = GradientBoostingClassifier(learning_rate=0.02, subsample=0.5, max_depth=6, n_estimators=30)
clf.fit(dataset_d2, y_d2)
y_submission = clf.predict_proba(dataset_predict)[:, 1]
print("Linear stretch of predictions to [0,1]")
y_submission = (y_submission - y_submission.min()) / (y_submission.max() - y_submission.min())
print("val auc Score: %f" % (roc_auc_score(y_predict, y_submission)))
最后
以上就是简单小懒猪最近收集整理的关于模型融合之Blending终于学透了!的全部内容,更多相关模型融合之Blending终于学透了内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复