MultiPoseNet: Fast Multi-Person Pose Estimation using Pose Residual Network.
原文链接
PRN网络
论文思路大致解读
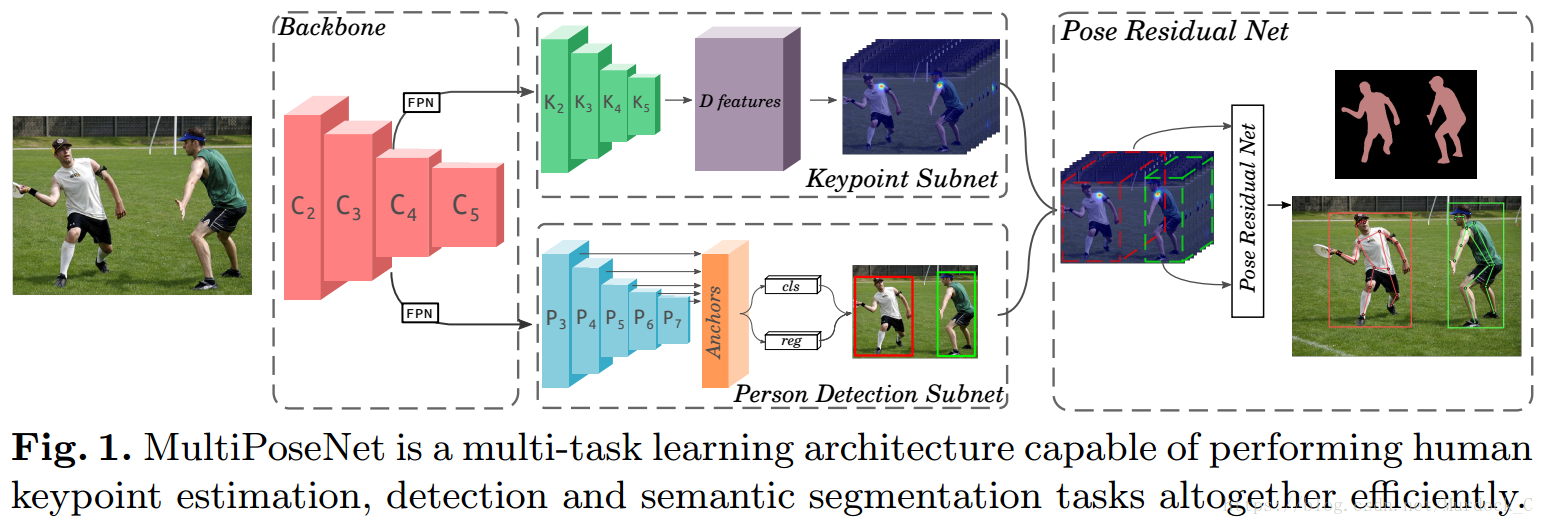
论文提出的网络结构大概分成三部分:
- 首先第一部分是Backbone网络,用于提取图片在多尺度下的特征;
- 第二部分包括两个分开、独立的网络,其中一个用来检测图片中所有的人体关键点(keypoint_subnet),另外一个用来图片中的行人检测(person_detect subnet)
- 第三部分即文章的核心部分,提出的残差网络(PRN,Pose Residual Network),概括来说就是一个聚类算法,将第二部分检测的到的所有关键点依据行人检测结果进行聚类,得到每个人的人体关键点聚集。
论文的网络结构如下图所示:
论文具体部分详解
Backbone网络: Backbone网络为后面的关键点检测和行人检测网络提供图像特征,在论文中使用了ResNet网络结构,并加入了两个FPN(Feature Pyramid Networks)网络结构,一个用于后面的关键点检测,一个用于后面的行人检测。论文作者在ResNet网络的最后一个residual block提取特征并计算相应的FPN特征,具体的ResNet网络文中采用了ResNet-50和ResNet-101两种网络,ResNet-50更快,ResNet-101会慢一些但相比ResNet-50在COCO数据集上提高了大约1.6mAP检测结果。
Keypoint Subnet: 关键点检测网络,输入为前面FPN网络的输出特征,输出为关键点热图和分割结果热图。关键点检测网络如下图所示: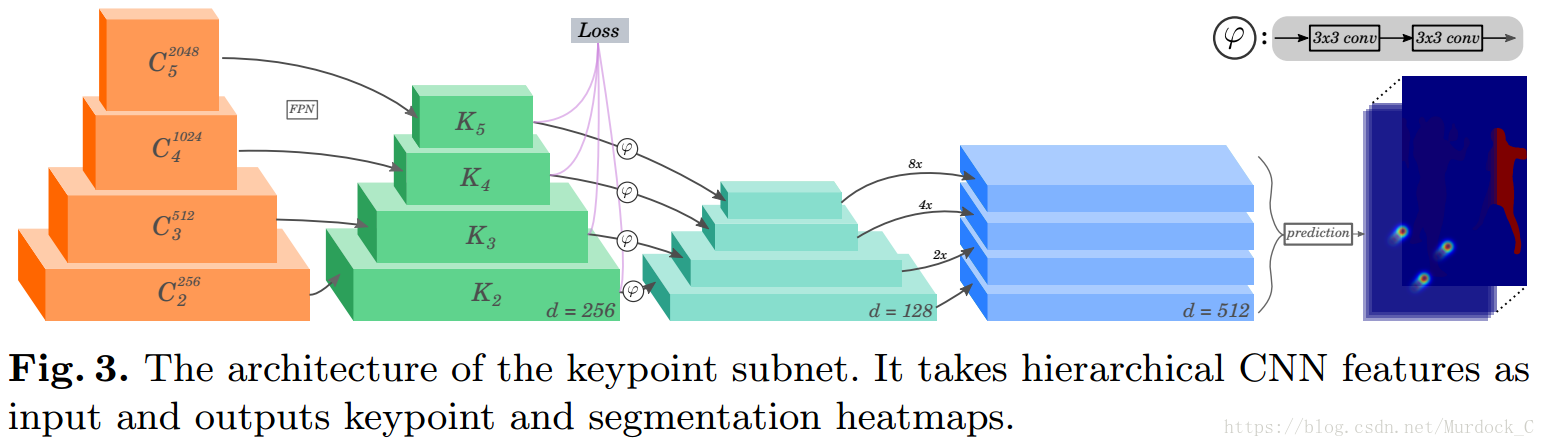 关键点检测网络还是使用了FPN用于前面步骤的特征点检测,Keypoint Subnet网络第三部分(即d=128那里)将前面传来的特征进行上采样,使得上面三个feature map大小和最下面的一致(从上到下依次为D2、D3、D4、D5),最后将D2-D5进行concatenated得到维度为512的feature map,接着通过一个33的卷积和ReLU进行smoothing,最后通过一个11的卷积得到(K+1)层的热度图输出,K是标注的人体关键点类别数量,+1是person segmentation mask。
关键点检测网络还是使用了FPN用于前面步骤的特征点检测,Keypoint Subnet网络第三部分(即d=128那里)将前面传来的特征进行上采样,使得上面三个feature map大小和最下面的一致(从上到下依次为D2、D3、D4、D5),最后将D2-D5进行concatenated得到维度为512的feature map,接着通过一个33的卷积和ReLU进行smoothing,最后通过一个11的卷积得到(K+1)层的热度图输出,K是标注的人体关键点类别数量,+1是person segmentation mask。
Person Detection Subnet:文中使用了 FPN+Focal Loss 模型用来行人检测,其实就是完全套用了RetinaNet结构,输出是N*5,N是图片内行人数量,5是bounding box的四个坐标加对应的confidence。具体网络结构可以参考原文:RetinaNet
PRN: 首先是固定尺寸的输入,所以需要先将关键点检测的输出和行人检测的输出裁剪到一个固定大小的值,然后再对其进行关键点到行人的映射。PRN使用叫“residual correction”的方法来对关键点进行映射(应该就是聚类的意思),使得同一个人的关键点映射到同一类。PRN的具体结构应该是一个多层感知机(MLP),文中给出最终采用的结构是:包含1024神经元的多层感知机,0.5概率的dropout,以及输入和输出中间一个residual connection。PRN采用的函数计算公式没有详细介绍,只给出了一个公式: ,具体代码可以看文章开头PRN网络链接。
,具体代码可以看文章开头PRN网络链接。
结果
文中代码运行环境是在GTX1080Ti上,Backbone应该是采用了ResNet-50,才达到了在COCO数据集上平均23FPS的效果。ResNet-101准确度会比ResNet-50高些,但速度会慢些。准确度来说应该是目前所有Bottom-Top方法里最高的,只有两个Top-Down的方法准确度比它高,但在多人姿态估计上,速度比它慢多了。
论文最后有比较是关键点检测结果对最终结果影响大还是行人检测对最终结果影响大,发现关键点检测结果影响非常大。在提供bounding box真值的情况下,网络检测出来的关键点 + GT(bounding box),其最终结果相比 GT(keypoints)+ GT(bounding box),AP值相差将近24.(两个GT的AP值为89.4,而 网络检测出的关键点+ GT box仅有65.1)。所以论文最后也提出了一个建议,就是使用更强的特征提取网络 (例如ResNext)来提高最终结果。(有可能会增加计算复杂度,降低运行速度)
论文里所提到的一些网络结构参考源:
- FPN:在FPN算法出来之前,现有的物体检测算法效果已经很好,比如Fast-RCNN, VGG, SSD等。但由于网络深度的增加,网络结构的stride相对于原始图像来讲相对较大,这会使得这些检测算法在小物体检测方面效果不是那么理想。FPN直接在原来的网络上做修改,每个分辨率的 feature map (先做了11的conv)引入后一分辨率缩放两倍的 feature map 做 element-wise 相加的操作(后一分辨率的feature map需要做2的upsampling,使用的方法是nearest neighbor upsampling)。通过这样的连接,每一层预测所用的 feature map 都融合了不同分辨率、不同语义强度的特征,融合的不同分辨率的 feature map 分别做对应分辨率大小的物体检测。这样保证了每一层都有合适的分辨率以及强语义特征。同时,由于此方法只是在原网络基础上加上了额外的跨层连接,在实际应用中几乎不增加额外的时间和计算量。文中将FPN应用到Faster-RCNN上,不同的尺度下最终准确度均有较大的提升,尤其是在小尺度的评判标准下,效果提升最为明显,也间接证明了FPN在检测小物体方面的优良性。
- RetinaNet:以anchor或RPN为基准的目标检测网络,都会遇到一个问题,就是训练时anchor或者RPN的正负样本比例不均衡,大概在1:1000左右。如果全部拿来训练,那么负样本对网络的贡献度就太大了,这就造成网络很难去往正确的方向去学习。以前的目标检测网络,都会限制正负样本的比例,比如faster的1:1, SSD的1:3等,但这都需要额外的工作量。RetinaNet则是使用了FocalLoss这一loss计算方法,对所有的anchor进行学习,只不过对正负样本有个权重,使得正样本权重变大,负样本权重变小,这样网络就可以向正确的方向去学习。
- ResNext
我自己也对这篇论文做了一个简单的复现,代码很杂,但结构比较清晰。目前成功复现了最后的PRN网络,根据官方提供的测试方法,也达到了它说的那个结果。但keypoint_subnet 和 person_detect subnet这两个网络,由于刚开始接触深度学习这方面,所以进展比较缓慢。
我的github地址。
注意::
我在复现这篇paper的时候,发现官方给的PRN网络代码有些问题。具体来讲就是上文的PRN网络代码里,src文件夹下的eval.py文件,在对PRN网络的输出结果做点的预测的时候,官方代码里却给出了用gt-points的值来给bbox_keypoints赋值。具体代码见eval.py第200行和205行。其实我认为代码里第209~220行才是正确的预测点的方法。另外issue里也有人说‘ This repo is a scam’,目前而言我也不确定这篇论文究竟有没有作假,但就其官方提供的关于PRN网络的测试脚本来看,其结果是很有问题的 。
有个大牛网友成功复现了这篇论文, github地址. 粗略看了下,最后一部分的PRN网络还是使用的官方的PRN网络复现,目前复现的精度也是很低,其实这个精度在完全不适用PRN网络的时候基本都可以得到.
Summary
这篇论文的复现今天就到头了,虽然最后也没有成功复现出来。论文作者放出的最后一部分PRN网络的代码严重有问题,不管它里面用到了什么trick,根据真值来给预测值赋值就是不对的,所以考虑这篇论文有造假嫌疑,github issue也没有response,邮件也没 。
(不再质疑论文真假问题,有可能我确实理解错了,但这篇文章确实成功的让我入了深度学习的坑,所以还是很感谢它.) 所以下面就总结下这三个月(从开始准备论文复现到结束)的工作结果吧。
论文部分
论文这块写的还是很清楚的。总共分为三个部分:第一个部分用来检测图片上所有人的关节点,第二个部分用来检测图片上所有人的bbox,第三个部分则是将前两个部分结合起来,将每个bbox里不属于这个人的关节点过滤掉。作者说代码开源,但给出的代码只有最后一部分,而且发现里面代码还是有问题的。
遇到的一些问题
在复现这篇论文的过程中遇到的问题就比较多了,包括不限于tensorflow的坑、数据处理的坑、模型保存测试的坑等等,踩得坑挺多,也学到了很多,我把一些我认为比较重要的坑记下来:
-
tensorflow里数据读取是在一个队列里面,读取出来的数据一旦进行了使用,哪怕仅是赋值操作,也会让程序认为这块数据已经被使用了,程序会自动读取队列里的下一个内容,而tensorflow静态图坑就在这,你在sess run之前使用了数据,那么在sess run时再使用时程序就会读取队列的下一内容,这会造成你的训练次数是你设定好的值一半。所以解决方法就是:sess run之前全部使用placeholder,在sess run的时候再feed。 tensorflow数据读取建议操作: 对于从tf队列里(例如tf.data.Dataset.iterator)里读取出来的数据,要么全部使用本来的变量名称,要么全部给建立个placeholder,然后sess run的时候再赋值, 保证一次sess run里只会出现一次和从 iterator 里读取数据的操作. -
数据预处理这块,有一次训练过程中做了flip操作,虽然对应的关键点也跟着flip,但忘记把label也对应flip。就好比本来是左手,flip之后应该label变成右手。
-
tensorflow模型保存部分,其中一次训练结果没有正确的把bn层的moving_mean 和 moving_var保存下来,但同样的代码在前面的训练过程中是可以正确保存的,经过一天的debug之后,同样的代码居然又可以了,这是最奇怪的一部分,因为根本不知道错在哪。有一个加上保险的解决方法就是在save的时候指定var_list,把网络的权重、偏差、bn层的gamma、beta、moving_mean和moving_var都存在一个var_list里面,指定保存。但这样一些变量如step、learning rate等等没法保存下来。
-
还有一个挺重要的坑就是opencv关于图像坐标和numpy 数组关于同样位置坐标问题。在opencv中,图片以左上角为起点,向右是x坐标,向下是y坐标,而在numpy中,向右是列,向下是行,在图片中的坐标(x,y),在numpy中则是(y,x),因此在对坐标操作的时候需要考虑到这一点。
收获
收获还是蛮大的,深度学习从零开始到现在,勉强算入了门。目标检测和关键点检测都了解了一部分,整体的流程都还比较清晰,code能力也是提高了一些,最大的收获就是’纸上得来终觉浅,绝知此事要躬行‘啊。
最后
以上就是妩媚发带最近收集整理的关于MultiPoseNet论文解读及复现的全部内容,更多相关MultiPoseNet论文解读及复现内容请搜索靠谱客的其他文章。








发表评论 取消回复