论文:http://proceedings.mlr.press/v37/xuc15.pdf
摘要:
论文提出了 attention (注意力)机制,可以自动的学习描述图片内容,论文描述了如何使用标准的反向传播算法技巧和随机最大化变量下届来定向训练模型。论文通过可视化展示了模型如何自动注视突出的目标(就是注意力集中到图片里的突出区域),论文在三个数据集上来证实算法的表现:![]()
介绍:
自动生成图像标题(重点)是理解场景的核心所在,标题生成模型不仅需要可以解决计算机视觉中的图片信息的挑战,还要能够处理自然语言的关系。这相当于模仿人类的能力,压缩大量突出信息处理成可描述的语言。随着神经网络的训练和大量数据分类任务能力的提升,通过结合神经网络获得图像的表示与循环神经网络处理自然语言,标题生成模型的质量显著提升。attention 使得突出信息能够动态的在前面显示出来,而不是整个将图片压缩成一个统计表示。使用表示学习直接将底层的最突出的信息提取出来是一个高效的解决办法,但是缺点是可能会将部分有用的信息丢失。使用低级的表示可以保存上述丢失的重要信息,但是需要一个强大的机制来将模型转换为当前重要信息。论文提出了两个转化,一个“硬”转化,一个“软”转化。论文的主要贡献:① 提出了两个 attention-based 标题生成器,并使用了同样的框架: soft 定向注意力机制通过标准反向传播算法训练,hard 随机注意力机制通过最大化近似变量下届。② 展示了论文可以通过可视化 what 和 where 解释上述框架 ③ 论文通过在数据集上的表现证实了 attention 在标题生成中的实用性。
模型:
如图,模型输入一个图片,经过 CNN 输出 14 x 14 的 feature map,然后通过 RNN 使用 LSTM 框架,最后生成解释。
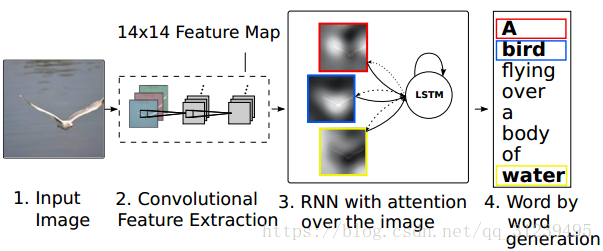
编码器:卷积特征
![]()
模型处理一个单张图片,生成一个标题 y,y被编码成连续的字符,k 是词汇字符的长度,C 是标题的长度,论文使用 CNN 提取特征向量,可以称之为解释向量,提取器提取 L 个向量,每一个向量都是 D 维, D 维与图片相关,如下公式:
![]()
论文使用一个低级的卷积层提取特征而不是使用全连接网络,这将使得解码器通过调整特征向量的权重,可以聚焦于图片中的部分区域。
解码器:LSTM 网络结构
论文使用 LSTM 网络结构,通过在每一个时间点上生成一个单词(在内容向量,之前的隐藏状态和之前生成的单词基础上)来生成标题,公式如下: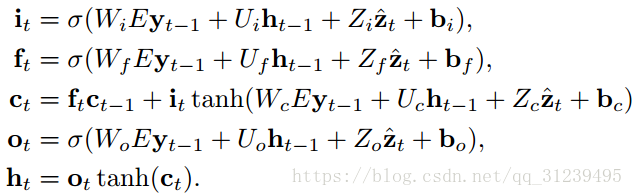
![]() 分别是输入,忘记,记忆,输出和LSTM的隐藏状态,
分别是输入,忘记,记忆,输出和LSTM的隐藏状态,![]()
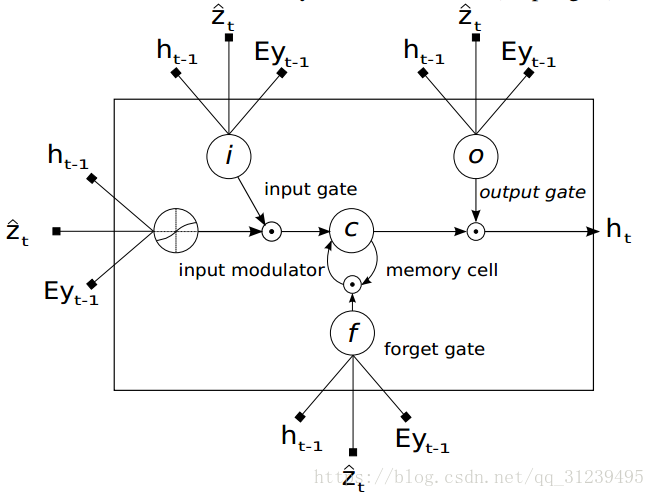
![]() 是权重矩阵和偏置。LSTM的结构图如下:矩形框里是LSTM学习过后的向量,每一个向量学习怎么调整 input 的权重,学习如何调整 memory 的贡献,学习调整 forget gate 的权重和学习 output 的权重。
是权重矩阵和偏置。LSTM的结构图如下:矩形框里是LSTM学习过后的向量,每一个向量学习怎么调整 input 的权重,学习如何调整 memory 的贡献,学习调整 forget gate 的权重和学习 output 的权重。![]() 是在时间 t 图像相关区域的动态表示,
是在时间 t 图像相关区域的动态表示,![]() 是一个机制,通过计算解释向量的
是一个机制,通过计算解释向量的![]() 定义。对于每一个区域,
定义。对于每一个区域,![]() 生成一个积极权重
生成一个积极权重![]() 描述区域 i 聚焦在正确的可以产生下一个单词的位置的概率(随机的注意力机制)或者是将 i 混合在 ai 中的相关重要性(定向的注意力机制),
描述区域 i 聚焦在正确的可以产生下一个单词的位置的概率(随机的注意力机制)或者是将 i 混合在 ai 中的相关重要性(定向的注意力机制),![]() 的计算是通过注意力模型
的计算是通过注意力模型![]() ,论文基于前一个状态 h(t-1) 使用多层感知机进行计算。
,论文基于前一个状态 h(t-1) 使用多层感知机进行计算。
公式如下:
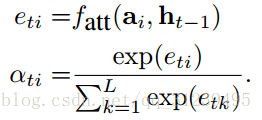
当权重计算好以后,内容向量![]() 通过以下公式计算,其中
通过以下公式计算,其中![]() 是一个函数,用来返回一个向量,该向量包括解释向量和他们的权重
是一个函数,用来返回一个向量,该向量包括解释向量和他们的权重
![]()
论文中,最初的内存记忆和隐藏的 LSTM 状态是通过一个解释向量的平均值来预测,同时该解释向量通过两个独立的多层感知机计算,公式如下:
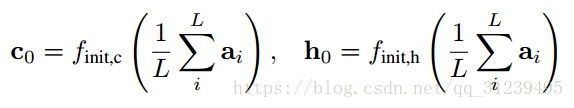
论文使用深度输出层来计算输出词语的概率,输入来自内容向量 context vetor,之前生成的词语,和当时解码器的状态 ht,计算公式如下:
![]()
随机 hard attention:
定义公式如下:其中![]() 是独热编码,当第 i 个区域是被可视化特征抽取时置 1,将 attention 的区域看作隐变量,我们可以提出一个 multinoulli 分布(我理解是多伯努利分布),公式如下:
是独热编码,当第 i 个区域是被可视化特征抽取时置 1,将 attention 的区域看作隐变量,我们可以提出一个 multinoulli 分布(我理解是多伯努利分布),公式如下:
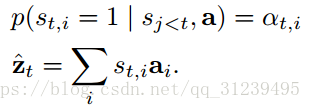
论文定义目标方程,该目标方程是一个边缘 log 似然函数,该似然函数是经过图像生成的顺序词语的探索过后的函数,该目标方程有如下性质:
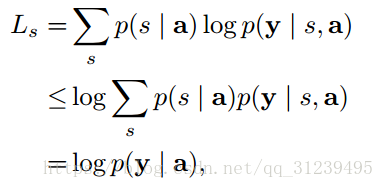
求梯度:
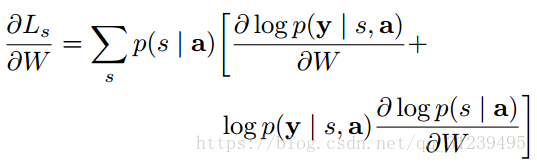
使用 monte carlo 近似:
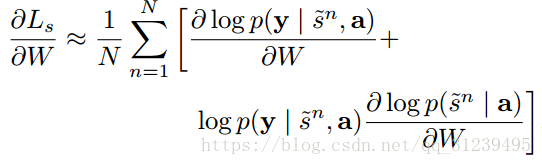
![]()
![]()
通过如下公式优化,来减少估计量的方差:
![]()
为了进一步减少估计量的方差,可将上述公式修改如下:
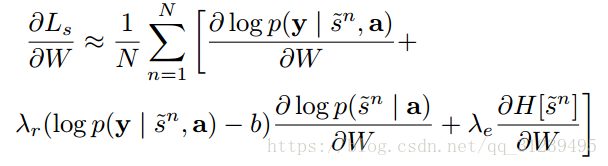
soft attention:
上述 hard attention 机制需要每次对 attention 区域进行采样,与之不同的是,在 soft attention 里,论文直接是使用内容向量的期望,如下公式所示:
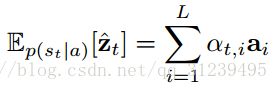
通过![]() 计算解释向量的权重来构造一个定向attention 模型。由于整个模型在定向 attention 机制下很平滑,所以通过标准反向传播算法来进行端对端学习就不那么重要了。deterministic attention 的学习可以理解为在attention location 近似优化边缘分布
计算解释向量的权重来构造一个定向attention 模型。由于整个模型在定向 attention 机制下很平滑,所以通过标准反向传播算法来进行端对端学习就不那么重要了。deterministic attention 的学习可以理解为在attention location 近似优化边缘分布![]() ,LSTM的隐藏激活函数是tanh non-linearity。
,LSTM的隐藏激活函数是tanh non-linearity。
NWGM(normalized weighted goemetric mean)公式定义如下:公式表明,NWGM可以通过直接计算期望![]() ,而不是对ai进行采样。
,而不是对ai进行采样。
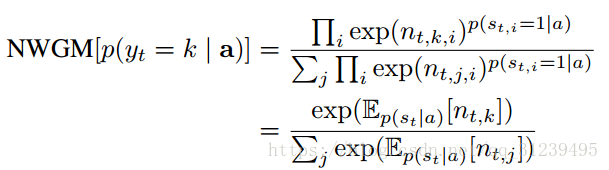
两者attention都使用:
最终公式如下:
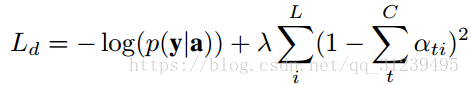
最后
以上就是聪慧汽车最近收集整理的关于attention(show, attention and tell: neural image caption generation with visual attention)摘要:介绍:模型:编码器:卷积特征解码器:LSTM 网络结构随机 hard attention:soft attention:两者attention都使用:的全部内容,更多相关attention(show,内容请搜索靠谱客的其他文章。



![[深度学习论文笔记][Attention]Show, Attend, and Tell: Neural Image Caption Generation with Visual Attention](https://www.shuijiaxian.com/files_image/reation/bcimg24.png)




发表评论 取消回复