小总结
- 总结了JDE在anchor、feature-fusion和Re-ID特征维度的unfair之处,提出了anchor-free的FairMOT
- FairMOT使用了基于encoder-decoder的DLA网络(anchor free的,基于关键点检测的方法)进行特征提取和多层融合,输出四个分支(三个用于检测,一个用于embedding)。
- 获得物体的检测位置和Re-ID信息后,配合卡尔曼滤波求解其代价矩阵(cost matrix),以及用匈牙利算法进行匹配。
摘要与结论
目标检测与再识别(Re-ID)是多目标跟踪的关键技术,近年来取得了显着的进展。然而,很少有人关注在一个网络中同时完成这两个任务。前的尝试最终导致了准确率的下降,主要是因为没有公平地学习re-ID任务,从而导致了许多ID切换。这种不公平表现在两个方面:(1)他们将Re-ID作为次要任务,其准确性严重依赖于主检测任务。因此,训练在很大程度上偏向于检测任务,而忽略了re-ID任务;(2)采用ROI-ALIGN方法提取目标检测中直接借用的Re-ID特征。然而,由于许多采样点可能属于干扰实例或背景,这在表征对象时引入了大量的模糊性。为了解决这些问题,我们提出了一种简单的方法FairMOT,它由两个同质分支组成,用于预测像素级的客观性分数和DRE-ID特征。任务之间实现的公平性使FairMOT能够获得高水平的检测和跟踪精度,并在几个公共数据集上远远超过以前的最先进水平。
从研究以前的one-shot方法(例如,[14])无法获得与两步方法相当的结果开始,我们发现锚点在目标检测和身份嵌入中的使用是导致结果降级的主要原因。具体地说,对应于对象的不同部分的多个附近锚可能造成估计成相同身份,从而导致网络训练的歧义。此外,我们还发现了以往MOT框架中检测任务和重识别任务之间存在的特征不公平和特征冲突问题。为了解决无锚点single-shot中的这些问题,我们提出了FairMOT。它在几个基准数据集上的跟踪精度和推理速度上都远远超过了以往的最新方法。此外,FairMOT本质上是训练数据高效的,我们提出了只使用带包围盒的图像进行多目标跟踪器的自监督训练,这两种方法都使我们的方法在实际应用中更具吸引力。
简介
多目标跟踪(MOT)是计算机视觉[1],[2],[3],[4]中的一个长期目标,其目的是估计视频中感兴趣的目标的目标。这一问题的成功解决可以使视频分析、动作识别、智能老年人护理和人机交互等许多应用受益。
现有的检测方法,如[1]、[2]、[3]、[4]、[5]、[6]、[7]等通常通过两个独立的模型来解决这一问题:检测模型首先通过每帧中的边界框定位感兴趣的对象,然后关联模型提取每个边界框的重新识别(re-ID)特征,并根据特征上定义的一定度量将其链接到现有的跟踪之一。近年来,目标检测[8]、[9]、[10]、[11]和Re-ID[3]、[12]都取得了显著进展,大大提高了整体跟踪性能。然而,这些方法不能进行实时推理,特别是当存在大量对象时,因为这两个模型不共享特征,并且它们需要对视频中的每个边界框应用Re-ID模型。随着多任务学习的成熟[13],使用单一网络估计对象和学习Re-ID特征的一次性跟踪器引起了更多的关注[14]、[15]。Voigtlaender等人[15]建议在Mask R-CNN之上增加一个Re-ID分支,以使用ROI-Align获取提案的Re-ID特征。通过重新使用Re-ID网络的主干功能来缩短推理时间。不幸的是,与两步法相比,跟踪精度明显下降,特别是ID开关的数量增加了很多。结果表明,将这两项任务结合起来不是一个微不足道的问题,应该谨慎对待。在本文中,我们旨在深入了解失败背后的原因,并提出一种简单而有效的方法(这种精神!多好!)。具体地说,确定了三个因素。
1.1 锚造成的不公平
现有的一次性跟踪器如Track R-CNN[15]和JDE[14]大多是基于锚的,因为它们是从基于锚的对象检测器直接修改而来的,例如YOLO[11]和Mask R-CNN[9]。然而,我们在研究中发现,基于锚点的框架并不适合学习Re-ID特征,这导致了大量的ID切换,尽管检测结果很好。
被忽略的Re-ID任务:Track R-CNN[15]以分级方式运行,它首先估计对象proposals(框),然后汇集proposals中的Re-ID特征以估计相应的Re-ID特征。值得注意的是,Re-ID功能的质量在很大程度上取决于proposals的质量。因此,在训练阶段,该模型严重偏向于估计准确的目标建议,而不是高质量的Re-ID特征。综上所述,这种“先检测后重ID”的标准框架使得Re-ID网络不能很好地学习。
一个锚点可能存在多个类(前景和背景):基于锚点的方法通常使用ROI-Pool或ROI-Align从每个方案中提取特征。但是大多数下采样的位置可能属于背景。因此,提取的特征在准确和有区别地表示目标对象方面并不是最优的。相反,我们在这项工作中发现,只在估计的对象中心提取特征要好得多。
多个锚对应于一个标识:在[15]和[14]中,只要它们的IOU足够大,对应于不同图像补丁的多个相邻锚点就可以被迫估计相同的身份。这给训练带来了严重的模糊性。有关插图,请参见图1。另一方面,当图像经历小扰动时,例如,由于数据增强,有可能迫使同一锚估计不同的身份。另外,目标检测中的特征图通常下采样8/16/32倍以平衡精度和速度,这对于目标检测来说是可以接受的,但对于学习Re-ID特征来说太粗糙了,因为在粗锚点提取的特征可能不会与对象中心对齐。
1.2 特征造成的不公平
(不仅需要高层的语义信息,还需要底层的颜色信息,所以需要多层特征融合)
对于一次性跟踪器,大多数特征在对象检测和重新ID任务之间共享。但众所周知,它们实际上需要来自不同层的功能才能达到最佳效果。特别是,目标检测需要深层和抽象的特征来估计对象的类别和位置,但它更注重低层外观特征,以发现同一类的不同实例。作者发现多层要素聚合允许两个任务(网络分支)从多层聚合要素中提取它们需要的任何要素,从而有效地解决了这一矛盾。如果没有多层融合,模型将会偏向于初级检测分支,并生成低质量的Re-ID特征。此外,多层融合将具有不同感受场的各层特征融合在一起,提高了处理实际中常见的目标尺度变化的能力。
1.3 特征维度造成的不公平
(Re-ID信息更适合使用低维度的特征来表示,维度过大容易出现过拟合)
以前的Re-ID工作通常学习非常高维的特征,并在其领域的标杆上取得了令人振奋的结果。然而,我们发现,学习低维特征实际上比one-shot MOT更好,原因有三:(1)虽然学习高维Re-ID特征可以略微提高他们区分对象的能力,但由于两个任务的竞争,显著损害了目标检测的精度,进而对最终的跟踪精度也产生了负面影响。(3)学习高维Re-ID特征可能会略微提高他们区分对象的能力,但由于这两个任务的竞争,这也会对最终的跟踪精度产生负面影响。考虑到目标检测中的特征维数通常很低(类数+盒子位置),我们提出通过学习低维Re-ID特征来平衡这两个任务;(2)当训练数据较小时,学习低维Re-ID特征可以降低过拟合的风险。MOT中的数据集通常比Re-ID区域中的数据集小得多。实验表明,学习低维Re-ID特征提高了推理速度。
在这项工作中,我们提出了一种称为FairMOT的简单方法来共同解决这三个公平问题。它与以前的“检测优先,重ID次要”的框架有本质的不同,因为在Fair-MOT中,检测任务和重ID任务是平等对待的。我们的贡献有三个方面。首先,我们实证地论证和讨论了以前的一次跟踪框架所面临的挑战,这些框架被忽视了,但严重限制了它们的性能。其次,在文献[10]等无锚点目标检测方法的基础上,我们引入了一种框架来平衡检测和Re-ID任务,该框架的性能明显优于以往的方法。最后,我们还提出了一种自监督学习方法来训练大规模检测数据集上的FairMOT,提高了它的泛化能力。这具有重要的经验价值。
图2显示了FairMOT的概述。它采用非常简单的网络结构,由两个同质分支组成,分别用于检测目标和提取Re-ID特征。受[10],[16],[17],[18]的启发,检测分支以无锚点的方式实现,它估计对象的中心和大小,表示为位置感知的测量地图。类似地,Re-ID分支估计每个像素的Re-ID特征,以表征以该像素为中心的对象。请注意,这两个分支是完全同质的,这与以前以级联方式执行检测和重新ID的方法有本质的不同。因此,FairMOT消除了表3中反映的检测分支的不公平优势,有效地学习了高质量的RE-ID特征,并在检测和RE-ID之间获得了良好的权衡,以获得更好的MOT结果。
值得注意的是,FairMOT算法处理的是步长为4的高分辨率特征图,而基于锚点的方法处理的是步长为32的高分辨率特征图。去掉锚点和使用高分辨率特征图可以更好地将Re-ID特征与目标中心对齐,显著提高了跟踪精度;Re-ID特征的维数设置为64,不仅减少了计算时间,而且很好地平衡了检测和Re-ID任务,提高了跟踪的鲁棒性。我们为骨干网络[19]配备了深层聚合运算器[20],以融合来自多层的特征,以便容纳两个分支并处理不同尺度的对象。
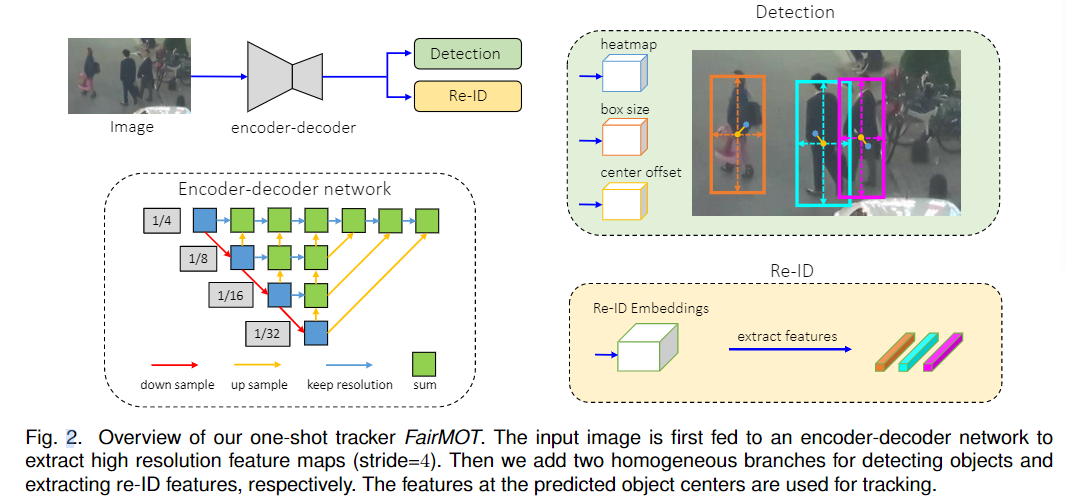
3 FairMOT
作者使用了Anchor-Free目标检测范式来代替,最常见的Anchor-Free目标检测范式由CornerNet、CenterNet等。
3.1 BackBone
(融合多层特征)
我们采用ResNet-34作为主干,以便在精度和速度之间取得良好的平衡。如图2所示,增强版本的深层聚合(DLA)[10]被应用于主干来融合多层特征。与原始DLA[20]不同的是,它在低层和高层特征之间有更多的跳跃连接,这类似于特征金字塔网络(FPN)[45]。此外,所有上采样模块中的卷积层都被可变形的卷积所取代,从而可以根据对象的尺度和位置动态调整接收野,这些修改也有助于缓解对准问题。最终的模型被命名为DLA-34。除了DLA,其他提供多尺度卷积特征的深层网络,如HigherHRNet[46],也可以用在我们的框架中,为检测和重ID提供公平的特征。
3.2 检测分支
我们的检测分支建立在Centernet[10]之上,但也可以使用其他无锚点方法,如[16]、[18]、[47]、[48]。我们简要描述了使这项工作自给自足的方法。特别地,在DLA-34上增加了三个平行头,分别估计热图、对象中心偏移量和包围盒大小。每个头的实现方法是对DLA-34的输出特征进行3×3的卷积(256个通道),然后用1×1的卷积层产生最终的目标。
3.2 检测分支
包括三个小分支:headmap、box size和 centeroffset,分别得到三个Loss
3.3 Re-ID分支
包括一个分支:Re-ID Embeddings,得到一个Loss
最后
以上就是欢呼航空最近收集整理的关于【目标跟踪 MOT】FairMOT : On the Fairness of Detection andRe-Identification in Multiple Object Tracking小总结摘要与结论简介3 FairMOT的全部内容,更多相关【目标跟踪内容请搜索靠谱客的其他文章。






![[深度学习论文笔记][Attention]Show, Attend, and Tell: Neural Image Caption Generation with Visual Attention](https://www.shuijiaxian.com/files_image/reation/bcimg24.png)

发表评论 取消回复