线程池实质上就是通过将单个线程通过容器进行管理,从而避免在高并发场景下,因为频繁的创建和销毁线程,造成不必要的性能开销。
Java线程池中各个接口和类的继承关系如下图:
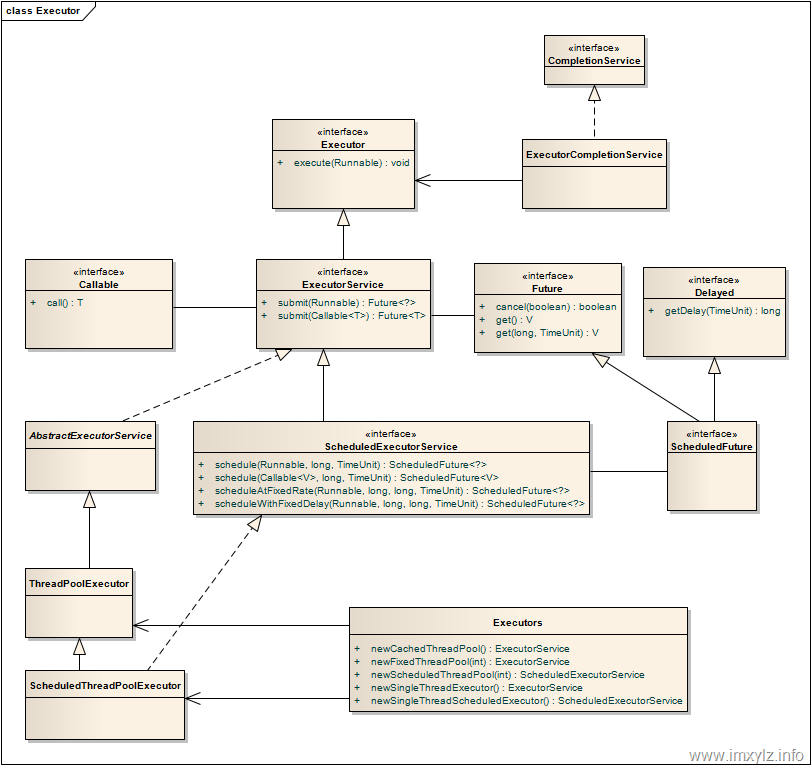
一、常用类
1、Executor接口
线程池中最顶层的接口是Executor,接口中只有一个void execute(Runnable command); 可以提交Runnable接口创建的线程,没有返回值
2、ExecutorService接口
ExecutorService接口实现了Executor接口,在接口中主要有Future<T> submit(Callable<T> call)方法,submit方法和execute方法的主要区别如下:
- execute和submit都属于线程池的方法,execute只能提交Runnable类型的任务,而submit既能提交Runnable类型任务也能提交Callable类型任务。
- execute会直接抛出任务执行时的异常,submit会吃掉异常,可通过Future的get方法将任务执行时的异常重新抛出。
- execute所属顶层接口是Executor,submit所属顶层接口是ExecutorService,实现类ThreadPoolExecutor重写了execute方法,抽象类AbstractExecutorService重写了submit方法。
- AbstractExecutorService在重写submit时,也是调用的executor方法,只不过对submit方法的参数进行了处理
3、AbstractExecutorService抽象类
在抽象类中对submit以及其它一系列方法进行了重写
4、ThreadPoolExecutor类
ThreadPoolExecutor类继承了AbstractExecutorService抽象类,也是Java线程池中最重要的一个类,类中提供的四个不同参数的构造方法,是创建线程池的核心,包括Executors类中提供四种线程池创建方法,也是由ThreadPoolExecutor中的构造方法封装而成。
public class ThreadPoolExecutor extends AbstractExecutorService {
.....
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,
BlockingQueue<Runnable> workQueue);
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,
BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory);
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,
BlockingQueue<Runnable> workQueue,RejectedExecutionHandler handler);
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,
BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory,RejectedExecutionHandler handler);
...
}前面三个构造器都是调用的第四个构造器进行的初始化工作,而第四个构造器中包含七个参数,七个参数含义如下:
- corePoolSize:线程池的核心线程数
- maximumPoolSize: 线程池的最大线程数
- keepAliveTime: 最大空闲时间
- TimeUnit unit:keepAliveTime的时间单位
TimeUnit.DAYS; //天
TimeUnit.HOURS; //小时
TimeUnit.MINUTES; //分钟
TimeUnit.SECONDS; //秒
TimeUnit.MILLISECONDS; //毫秒
TimeUnit.MICROSECONDS; //微妙
TimeUnit.NANOSECONDS; //纳秒
- BlockingQueue<Runnable> workQueue:在线程池达到最大线程数时,用来保存新进任务的任务队列,有三种队列:ArrayBlockingQueue,LinkedBlockingQueue(常用),SynchronousQueue。三种队列的最大区别在于底层存储逻辑不同,因为任务队列增删比较频繁,查改比较少,所以链式存储队列是最常用的。
- ThreadFactory threadFactory:创建线程的线程工厂
- RejectedExecutionHandler handler:在已经达到最大线程数且任务队列已经满了的时候,用来执行拒绝策略,主要有四种取值:
ThreadPoolExecutor.AbortPolicy:丢弃任务并抛出RejectedExecutionException异常。 ThreadPoolExecutor.DiscardPolicy:也是丢弃任务,但是不抛出异常。 ThreadPoolExecutor.DiscardOldestPolicy:丢弃队列最前面的任务,然后重新尝试执行任务(重复此过程) ThreadPoolExecutor.CallerRunsPolicy:由调用线程处理该任务
除此之外,ThreadPoolExecutor类也提供了execute()、submit()、shutdown()、shutdownNow()等线程池相关的方法。
5、Executors类 Executors可以看作是一个线程池工厂,提供了四种不同功能创建线程池的静态方法,返回的是一个ExecutorService对象。四种方法名和功能如下:
- newFixedThreadPool 创建一个固定线程数量的线程池,corePoolSize和maximumPoolSize值相等,具体线程数量初始化时在构造方法中声明,它使用的LinkedBlockingQueue;
- newSingleThreadExecutor 创建一个单线程的线程池,将corePoolSize和maximumPoolSize都设置为1,也使用的LinkedBlockingQueue;
- newCachedThreadPool 创建一个线程数量没有上限(理论上)的线程池,将corePoolSize设置为0,将maximumPoolSize设置为Integer.MAX_VALUE,使用的SynchronousQueue,也就是说来了任务就创建线程运行,当线程空闲超过60秒,就销毁线程。
- newScheduledThreadPool 创建一个可定期或者延时执行任务的定长线程池,支持定时及周期性任务执行。
这几种方法都是由ThreadPoolExecutor类的构造方法根据不同参数封装而成,如果Executors提供的静态方法能满足要求,就尽量使用它提供的三个方法,因为自己去手动配置ThreadPoolExecutor的参数有点麻烦,要根据实际任务的类型和数量来进行配置。
另外,如果ThreadPoolExecutor达不到要求,可以自己继承ThreadPoolExecutor类进行重写。
二、 线程池的运行流程
对于一个标准的ThreadPoolExecutor线程池,在接受到一个新的任务时,整个运行流程大概如下:
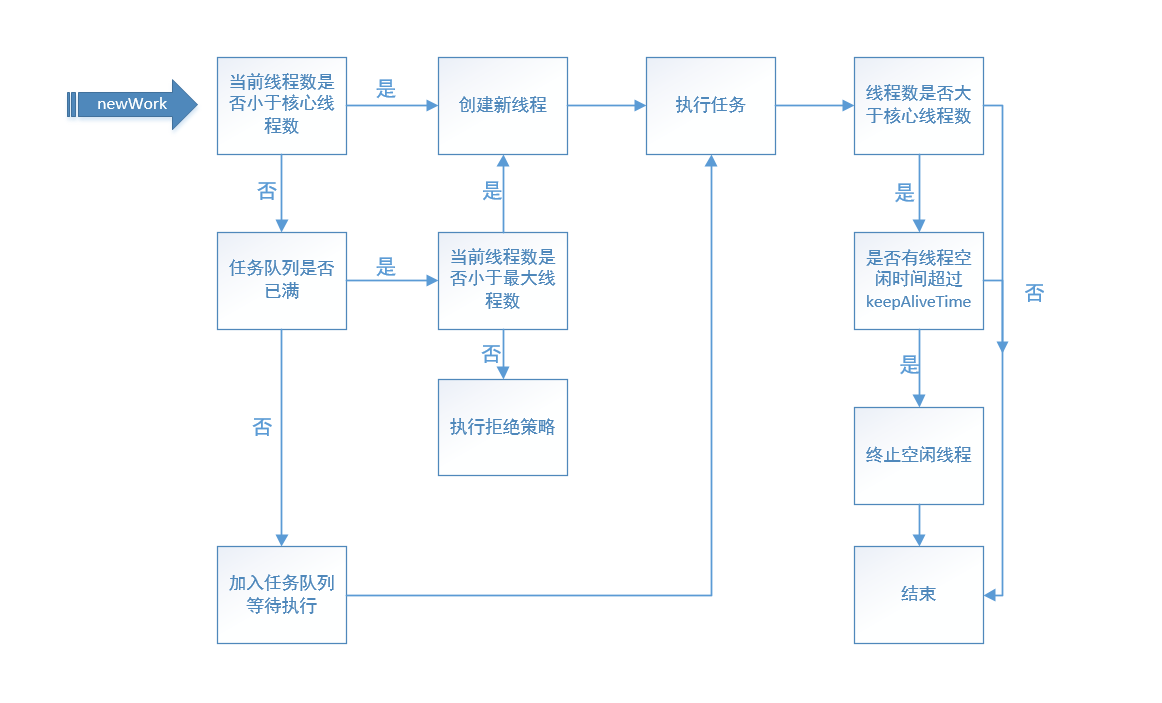
结合运行流程图和底层源码,我们在代码层面来分析下线程池是如何运作的。
1、首先是线程池的初始化,核心构造方法是ThreadPoolExecutor。在构造方法中主要对参数进行了核对,非法参数会抛出异常。
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.acc = System.getSecurityManager() == null ?
null :
AccessController.getContext();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}2、其次是执行,查看ThreadPoolExecutor类中的execute()方法源码如下:
public void execute(Runnable command) {
if (command == null) //如果任务为空,抛出异常
throw new NullPointerException();
int c = ctl.get(); //获取线程池标记
if (workerCountOf(c) < corePoolSize) { //如果工作线程数小于核心线程数
if (addWorker(command, true)) //创建一个核心线程,并将这个任务交给这个线程执行
return;
c = ctl.get();
}
/*
执行到这里的时候会出现两种情况
1、当前工作线程数大于等于工作线程数
2、新线程创建失败
这个时候会将任务添加到阻塞队列
*/
//如果线程池在运行,将任务添加进阻塞队列
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get(); //再次获取线程池标记
//如果线程池不处于running状态,将任务取出,然后执行拒绝策略
if (! isRunning(recheck) && remove(command))
reject(command);
//如果线程池正在运行,但是工作线程数量为0,新建非线程,不执行任何东西
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
//创建非核心线程去执行任务,如果失败,执行拒绝策略
else if (!addWorker(command, false))
reject(command);
}关于其中的 addWork(Runnable firstTask, boolean core) 方法,
翻译其注释大概如下:
检查一个新的worker是否可以添加到当前池,如果可以,则相应地调整worker。如果可能,将创建并启动新的worker,将firstTask作为其第一个任务运行。如果池已停止或关闭,则此方法返回false。如果线程工厂在被询问时无法创建线程,它也返回false。如果线程创建失败,要么由于线程工厂返回null,要么由于异常(通常是thread .start()中的OutOfMemoryError)),我们回滚。
其中一些核心代码如下:
Worker w = new Worker(firstTask); //将firstTask封装为一个Worker任务
final Thread t = w.thread;
// 如果成功添加了 Worker,就可以启动 Worker 了
if (workerAdded) {
t.start(); //启动执行任务的线程
workerStarted = true;
}t.start()方法实际上调用了Worker的run方法,而run方法中调用了runWorker方法,runWorker方法核心代码如下:
final void runWorker(Worker w) {
Runnable task = w.firstTask;
while (task != null || (task = getTask()) != null) {
try {
task.run();
} finally {
task = null;
}
}
}while 循环有个 getTask 方法,getTask 的主要作用是从阻塞队列中拿任务出来,如果队列中有任务,那么就可以拿出来执行,如果队列中没有任务,这个线程会一直阻塞到有任务为止(或者超时阻塞)
线程的复用就是这样实现的,当线程本身有任务或者任务队列不为空的时候,就一直执行run方法,超时则销毁超过corePoolSize的线程.
3、线程池对线程的创建和保存
查看Worker的构造方法,如下:
Worker(Runnable firstTask) {
setState(-1); // inhibit interrupts until runWorker
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this);
}可以看到,是在这里调用了ThreadFactory创建新的线程去执行任务。
在线程池中是使用HashSet去保存所有的工作线程:
/**
* Set containing all worker threads in pool. Accessed only when
* holding mainLock.
*/
private final HashSet<Worker> workers = new HashSet<Worker>();
在线程池中,所有的操作都是先提交到主main线程,然后main线程再操作别的工作线程进行一系列操作,在这些操作中都使用了Lock锁,来确保操作的原子性,例如在获取线程池大小的方法中:
private final ReentrantLock mainLock = new ReentrantLock();
public int getPoolSize() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// Remove rare and surprising possibility of
// isTerminated() && getPoolSize() > 0
return runStateAtLeast(ctl.get(), TIDYING) ? 0
: workers.size();
} finally {
mainLock.unlock();
}
}三、 线程池的简单使用
1、使用ThreadPoolExecutor自己设置参数创建一个线程池
(1)线程类
public class MyTask implements Callable<Integer> {
private int taskNum;
public MyTask(int num) {
this.taskNum = num;
}
@Override
public Integer call() {
try {
Thread.sleep(4000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("task " + taskNum + "执行完毕");
return null;
}
}
(2)执行类
public class ThreadPoolTest {
public static void main(String[] args) throws ExecutionException, InterruptedException {
ThreadPoolExecutor executor = new ThreadPoolExecutor(
5, 10, 10, TimeUnit.MILLISECONDS,
new ArrayBlockingQueue<Runnable>(5));
for (int i = 0; i < 15; i++) {
MyTask myTask = new MyTask(i);
Future<Integer> ft = executor.submit(myTask);
System.out.println(
"当前线程池大小为:" + executor.getPoolSize() +
" 队列中等待任务数为:" + executor.getQueue().size()
);
//get
}
executor.shutdown();
}
}值得一提的是,我曾在执行类注释//get处尝试用Future接口get方法获取call()方法的返回值,但是执行起来发现所有线程都变成了串行执行。分析后发现,是因为get方法是由main线程调用的,当main线程提交A线程后,要获取A的执行结果,就必须等A的call方法执行结束,main线程get到结果后才会去创建提交下一个线程,所以所有线程都变成了串行执行。
2、线程类不变,使用Executors.newFixedThreadPool()创建一个固定线程数量的线程池,运行时候可以发现,同一时间只有五个线程执行。
public class CreateThreadPoolByExecutors {
public static void main(String[] args) {
ExecutorService executorService = Executors.newFixedThreadPool(5);
for (int i = 0; i < 15; i++) {
MyTask myTask = new MyTask(i);
executorService.submit(myTask);
}
}
}
最后
以上就是炙热天空最近收集整理的关于Java多线程-线程池的全部内容,更多相关Java多线程-线程池内容请搜索靠谱客的其他文章。








发表评论 取消回复