
作者:阿萨姆
众所周知,数据科学是这几年才火起来的概念,而应运而生的数据科学家(data scientist)明显缺乏清晰的录取标准和工作内容。即使在2017年,数据科学家这个岗位的依然显得“既性感又暧昧”。
我随手搜索了几家国内国外不同领域的数据科学家招聘广告(国内:阿里巴巴,百度 | 海外: IBM,道明银行,Manulife保险),通过简单的归纳总结,我们不难发现其实岗位要求有很大的重叠部分:
学历要求:硕士以上学历,博士优先。统计学、计算机科学、数学等相关专业。
工作经历: 3年以上相关工作经验。
专业技能: 熟练掌握HiveSQLhadoop,熟悉大规模数据挖掘、机器学习、自然语言处理(NLP)
分析语言: R, Python, SAS, JAVA
额外要求: 对数据敏感,具备良好的逻辑思维能力、沟通技巧、组织沟通能力、团队精神以及优秀的问题解决能力
有趣的是,这个广告适用于来大部分的数据科学家招聘,甚至不分行业不分地域。可能唯一的不同是,金融领域更强调擅长反欺诈和风控,而电商领域强调熟悉推荐系统,侧重点不同而已。其实这个现象的本质就是:数据科学家是一个不限行业,拥有广泛就业需求,高度”相似”却又”不同”的职位。因此结合我自己的经验,以及与国内国外这一行同事/朋友的交流心得,我想来谈谈我对数据科学家这个岗位的理解。
在个人理解的前提下,我想谈谈:1. 数据科学家为什么是“科学家”?2. 数据科学家的工作内容有什么? 3. 一些对于数据分析的感悟 4. 如何成为一个合格的数据科学家?
数据科学家成为了一个跨学科职位。我将数据科学家定义为: 能够独立处理数据,进行复杂建模,从中攫取商业价值,并拥有良好沟通汇报能力的人。
关于数据科学家这个岗位怎么来的,说法不一。我自己的理解是随着机器学习和更多预测模型的发展,数据分析变得”大有可为”。为了区分拥有建模能力的高端人才和普通商业分析师/数据分析师(data analyst),数据科学家这个职位自然就产生了。通过这个新岗位,行业可以与时俱进的吸收高端人才。在机器学习没有大行其道,也没有大数据支撑之前,这个岗位更贴近统计科学家(statistician),和研究科学家(research scientist)也有一点点相似。
对于科学家,我们的一般的定义是在特定领域有深入研究的人,因此潜台词一般是“拥有博士学位的人”。而数据科学家的基本要求是硕士以上学历,甚至有时候本科学历也会被接受,而且似乎数据科学家的工作并不会在特定领域有深度。那么数据科学家是否言过其实了?
我的看法是:不,数据科学家的“广度”就是其”深度”。从另外一个角度来看,数据科学家的优势在于其优秀的跨领域技能,既可以抓取数据,也可以分析,进行建模,还能将有用的信息用抓人的眼球提供给决策层。能拥有这样解决问题能力的人,似乎并不愧对一声“科学家”。
而正因为数据分析更要求的广度而不是深度,所有现在只有纽约大学提供科学博士,而现在大部分从业的博士都是统计学/计算机/数学/物理背景。正是这个原因,这个行业对于数据科学家的要求是硕士及以上,而计算机或者统计的人更适合的原因是其在机器学习/统计学习方面的积累,其他所需技能可以以很低的代价赶上。相对应的,如果一个心理学博士想要从事这一行就会发现需要补充的技能太多,而因此不能适应这个岗位。
与研究科学家(research scientist)相比,数据科学家更像是全能手但在特定领域深度不足。和普通分析师(analyst)相比,数据科学家应该有更强的建模和分析能力。在和数据工程师相对比时,数据科学家应该具备更强的汇报和沟通能力。
我最近在和朋友闲聊时,惊讶的发现大家的工作内容都很相似。主要包括:
此处的工作特指根据客户需求,从数据中攫取商业价值,而这个过程中一般都会涉及统计模型(statistical learning)和机器学习模型(machine learning)。如果在数据没有处理的情况下,我们的工作偶尔也涉及清理数据。有时候我们反而希望数据是未经过处理的,因为很多重要信息都在被处理中遗失了。一般的项目遵循以下几个流程:
确定商业痛点 – 明白要解决的问题是什么?
获得数据并进行清理,常见的数据预处理包括: a. 缺失值处理 b.特征变量转化 c.特征选择和维度变化(升维或者降维) d. 标准化/归一化/稀疏化。涉及文字的时候可能还要使用一些自然语言处理的手段,更多的相关方法可以看我最近的回答[1]。
模型选择与评估。这个过程常常是比较粗暴的,往往需要做多个模型进行评估对比。
提取商业价值,编写报告或意见书,并向相关负责人汇报。
与纯粹的机器科学工程师不同,数据科学家的重要工作内容是交流沟通。如果无法了解清楚客户的需求是什么,可能白忙活一场。如果无法了解数据工程师在采集数据时的手段,我们使用的原始数据可能有统计学偏见。如果不能讲清楚如何才能有效的评估模型,负责在云端运行模型的工程师可能给出错误的答案。因此,数据科学家除了建模必须亲手来做以外,其他的环节可以“外包”给别人。在数据量特别大的时候,这个需求变得更为明显。
良好的沟通能力不仅仅是指和团队成员的沟通,向老板和客户的汇报也很考察数据科学家的能力。作为一个数据科学家,我们一般有几个原则:
汇报时避免“黑话”,避免给不同背景的老板和客户造成疑惑。
直击重点而不炫技。尽量简明扼要,不要过分介绍模型的内部构造,重心是得到的结论。
实事求是不夸大模型能力。很多机器学习模型其实都已经不同程度过拟合,不刻意避开交叉验证而选择“看似表现良好的”过拟合模型。
给出可以进一步优化和提高的方向,为项目提出新的方向。
在汇报时尽量用可视化来代替枯燥的文字。
以我去年做的一个项目为例:
我们公司的领导层希望了解为什么我们的员工离职率很高,如何才可以避免这一点。遵循我上面介绍的流程:
从人事部门收集数据,清楚的告诉他们我需要的数据时间跨度,变量。并和法务部门一起将数据中的隐私部分去除。
进行数据预处理,建模并评估。
从中挖掘商业价值,如 a. 为什么员工会离职(将变量重要性进行排序,用决策树可视化分类结果) b. 什么样的员工值得留住?
制作报告,并像领导层汇报我的发现,过程设计可视化等。
和其他部门的同事将这个项目包装成一个案例,卖给我们的其他客户。
这个基本包括了数据分析项目的基本流程,对于这个项目的一些有趣发现可以看我的另一个回答[2]。但不难看出,整个流程中有大量的沟通过程,甚至还包括销售的部分,这在一次体现了数据科学家的工作广度。
数据科学家是个听起来非常“性感的”的岗位,别忘了我们小时候的梦想都是成为一个科学家。但抛开这些虚的东西,我们必须认清这个岗位的核心就是将很多技能封装到一个人身上。而我们工作的正常开展少不了其他同事的支持和帮助,所以千万不要看不起别人的工作内容。没有数据工程师进行数据采集,没有分析师帮我们美化图表和提出质疑,我们无法得到最好的结果。
数据分析项目一直都是众人拾柴火焰高,没有人可以当超人。所以在得到这样“高薪性感”的职位后,我们更应该把心装回肚子里,脚踏实地。
承接上一点,虽然我们的工作重点之一是建模,但请不要神话算法,也不要挟算法以令同事,觉得只有自己做的部分才有价值。
简单来说,可以通过没有免费的午餐定理(No Free Lunch Theorem -> NFL Theorem)来解释。NFL由Wolpert在1996年提出,其应用领域原本为经济学。和那句家喻户晓的”天下没有免费的午餐”有所不同, NFL讲的是优化模型的评估问题。
在机器学习领域,NFL告诉机器学习从业者:”假设所有数据的分布可能性相等,当我们用任一分类做法来预测未观测到的新数据时,对于误分的预期是相同的。” 简而言之,NFL的定律指明,如果我们对要解决的问题一无所知且并假设其分布完全随机且平等,那么任何算法的预期性能都是相似的。这个定理对于“盲目的算法崇拜”有毁灭性的打击。例如,现在很多人沉迷“深度学习”不可自拔,那是不是深度学习就比其他任何算法都要好?在任何时候表现都更好呢?未必,我们必须要加深对于问题的理解,不能盲目的说某一个算法可以包打天下。
周志华老师在《机器学习》一书中也简明扼要的总结:“NFL定理最重要的寓意,是让我们清楚的认识到,脱离具体问题,空泛的谈‘什么学习算法更好’毫无意义。”
在这个深度学习就是一切的时代,作为数据科学家,我们要有自己的独立判断。
数据科学家作为一个更偏商业应用的岗位,而不是研究岗位,需要重视数据可视化的重要性以及模型可解释度的意义。原因很简单,如果客户看不懂我们做的是什么,或者客户不相信我们做的东西的可靠性,你即使有再酷炫的模型,也只是浪费时间。在大部分中小型的数据分析项目中,用深度学习的机会是很有限的。原因包括但不限于:
数据量要求很大
调参成本太高且奇淫巧技太多
模型可视化即解释度低
而比较常用的机器学习模型是: 广义线性模型(generalized linear models),如最普通的逻辑回归;还有以决策树为基底的模型,如随机森林和Gradient Boosting Tree等。这两种模型都有很好的可解释性,而且都可以得到变量重要性系数。以Sklearn官方文档中的简单的决策树可视化为例:
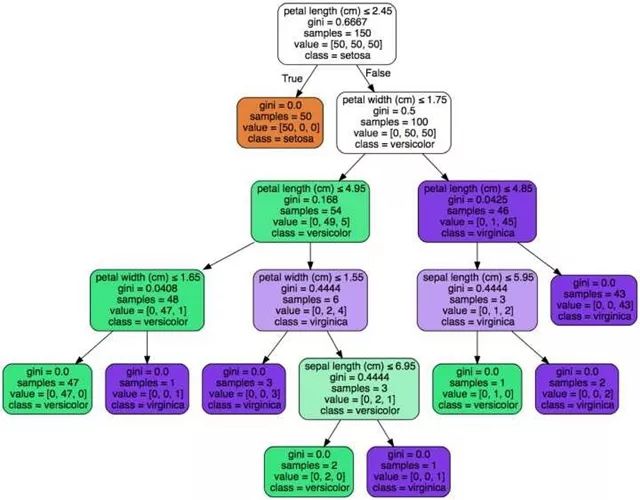
我们可以清楚的看到一个数据点如何从上至下被分到了不同的类别当中。作为一个需要和不同背景的人沟通的职业,分类器可视化是一个很好沟通基础。
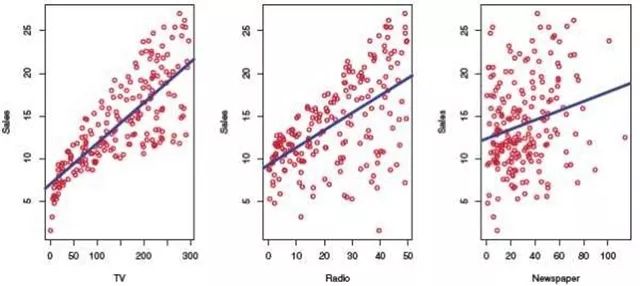
而可视化的好处远不止于此,在数据建模初期的可视化可以避免我们走很多弯路。以ISL[3]中附带的线性回归为例,我们一眼就可以看出最右边的图不像左边的图中的数据可以通过简单的线性回归进行拟合,可以直接跳过线性回归来节省时间。
承接上一点,对于一个问题我们通常无法得到所有的相关变量,这导致了大部分数据分析的结果其实或多或少都有偏见。讲个经典的统计学笑话,夏天溺水身亡的人数相比冬天大幅度上升,而夏天吃冰激凌的人数也上升,所以得到结论: “吃冰激凌”会导致“溺水”。这种数据会说谎的本质就在于我们无法获得所有的隐变量,如夏天去海边的人数上升,游泳的人数上升等。
而在数据分析的项目中,大部分谬误无法像上面这个例子一眼就可以看穿,我们常常会获得很多看起来很可信但实则大误的结论。作为一个数据科学家,请在分析时小心在小心,谨慎再谨慎,因为我们的分析结果往往会直接影响到公司或者客户的收益。假设你做人事分析的项目,错误的结论可能导致优秀的员工被解雇。
所以万望大家不要总想搞个大新闻,对于没有足够显著性的结论请再三检查,不要言过其实。这是我们的责任,也是义务。
假设你已经有了基本的从业资格:即有相关领域的学位,掌握了数据分析和建模的基础能力,也懂得至少一门的分析语言(R或Python)和基本的数据库知识。下面的这些小建议可以帮助你在这条路上走的更远。
像我在另一个机器学习面试回答[4]中提到过的,保证对基本知识的了解(有基本的广度)是对自己工作的基本尊重。什么程度就算基本了解呢?以数据分析为例,我的感受是:
对基本的数据处理方法有所了解
对基本的分类器模型有所了解并有所使用(调包),大概知道什么情况使用什么算法较好
对基本的评估方法有所掌握,知道常见评估方法的优劣势
有基本的编程能力,能够独立的完成简单的数据分析项目
有基本的数据挖掘能力,可以对模型进行调参并归纳发现
至于其他软实力,暂时按下不表。
屠龙之技相信大家都有,我常常听别人说他已经刷完了X门在线课,熟读了X本经典书籍,甚至现代、优化、概率统计都又学了一遍,但为什么Kaggle上还是排名靠后或者工作中缺乏方向?
简单来说,上面提到的这些储备,甚至包括Kaggle经验,都属于屠龙之技。数据分析领域的陷阱随处可见,远不是几本书几篇论文就能讲得清楚。最好的方法只有从工作中实践,跟着你的师傅学习怎么分解项目,怎么提取价值。
我记忆很深的一个例子是:有一次我和我的老板为某国家铸币中心制定最优的纪念币定价方案,来最大化收益。但根据客户给我们的例子,我们的优化模型效果很差,误差极大。我的老板给了我几个建议:1. 把回归问题转为分类问题,牺牲一部分精度 2. 舍弃掉一部分密度很低的数据,对于高密度区域根据密度重建模型 3. 如果不行,对于高密度区域用有限混合模型(Finite Mixture Model)再做一次。采纳了老板的建议,最终我们对于百分之75%的纪念币做到了最佳的优化结果,为客户带来了价值。客户对于剩下25%无法预测表示理解,因为他们无法提供更多的市场数据。
那个时候的我总觉得不能舍弃数据,但我的老板用行动告诉我客户最需要的是获得价值,而不是完美的模型。而这种感悟,我们只有在实际工作中才能获得。所以当你作为数据科学家开始工作时,请多想想如何产生价值,而不是一味地炫屠龙之技。
数据科学家的重要工作内容就是汇报和写报告,因而良好的”讲故事”(storytelling)能力非常重要。在学习的过程中,请不要把全部的重心放在技术能力上。技术能力可以保证你有东西可以说,但讲故事这种软实力可以保证你的辛苦没有白费,你的能力获得大家的认可。同时,这种沟通能力也可以让你在社交中更加如鱼得水,一改理工科给人留下的沉闷的印象。轻沟通,重技术,是一种工程师思维,但这并不适用于数据科学家。
最后想不恰当的引用一句西方谚语:“欲戴王冠,必承其重。”在这个数据为王的时代里面,成为优秀的数据科学家不仅仅代表着高薪,还代表着我们对于这个时代的贡献与价值。然而道路阻且长,还有太多太多需要我们学习和完善的方向。
End
阅读排行榜/精华推荐1 入门学习如果有人质疑大数据?不妨把这两个视频转给他
视频:大数据到底是什么 都说干大数据挣钱 1分钟告诉你都在干什么
人人都需要知道 关于大数据最常见的10个问题
2 进阶修炼从底层到应用,那些数据人的必备技能
如何高效地学好 R?
一个程序员怎样才算精通Python?
3 数据源爬取/收集排名前50的开源Web爬虫用于数据挖掘
33款可用来抓数据的开源爬虫软件工具
在中国我们如何收集数据?全球数据收集大教程
4 干货教程PPT:数据可视化,到底该用什么软件来展示数据?
干货|电信运营商数据价值跨行业运营的现状与思考
大数据分析的集中化之路 建设银行大数据应用实践PPT
【实战PPT】看工商银行如何利用大数据洞察客户心声?
六步,让你用Excel做出强大漂亮的数据地图
数据商业的崛起 解密中国大数据第一股——国双
双11剁手幕后的阿里“黑科技” OceanBase/金融云架构/ODPS/dataV
金融行业大数据用户画像实践
“讲述大数据在金融、电信、工业、商业、电子商务、网络游戏、移动互联网等多个领域的应用,以中立、客观、专业、可信赖的态度,多层次、多维度地影响着最广泛的大数据人群

36大数据
长按识别二维码,关注36大数据
搜索「36大数据」或输入36dsj.com查看更多内容。
投稿/商务/合作:dashuju36@qq.com
↓↓↓
最后
以上就是冷艳洋葱最近收集整理的关于数据科学工作者(Data Scientist) 的日常工作内容包括什么?的全部内容,更多相关数据科学工作者(Data内容请搜索靠谱客的其他文章。








发表评论 取消回复