一.HW机考攻略
【刷题网址】
牛客——https://www.nowcoder.com/ta/huawei
力扣——https://leetcode-cn.com/problemset/all
(带*题目与第一第二道题目难度相近,以下题目基本覆盖大部分知识点)
1. 【基础入门题型】 入门题(5 题)
(1) 输入处理(重要):HJ5.进制转换
(2) 排列组合:(牛客搜索)NC61.两数之和
(3) 快速排序:HJ3.明明的随机数
(4) 哈希表:HJ10.字符个数统计
(5) 递归:NC68.跳台阶
2.字符串操作(6题)
(1) HJ17.坐标移动
(2) HJ20.密码验证合格程序
(3) *HJ23.删除字符串中出现次数最少的字符
(4) *HJ33.整数与IP地址间的转换
(5) HJ101.输入整型数组和排序标识
(6) *HJ106.字符串逆序
3.排序(5题)
(1) HJ8.合并表记录
(2) *HJ14.字符串排序
(3) HJ27.查找兄弟单词
(4) *NC37.合并区间
(5) *HJ68.成绩排序
4.栈(2题)
(1) NC52.括号序列
(2) *leetcode 1614.括号的最大嵌套深度
5.排列组合(2题)
(1) *leetcode 面试题08.08.有重复字符串的排列组合
(2) leetcode 77.组合
6.双指针(3题)
(1) *leetcode 674.最长连续递增序列
(2) NC17.最长回文子串
(3) NC28.最小覆盖子串
7.深搜(1题)
(1) HJ41.称砝码
8.二叉树(2题)
(1) *leetcode 剑指offer 32 — II.从上到下打印二叉树 II
(2) leetcode 剑指offer 32 — III.从上到下打印二叉树 III
9.其他(6题)
(1) *HJ108.求最小公倍数
(2) *HJ28.素数伴侣
(3) *HJ60.查找组成一个偶数最接近的两个素数
(4) *leetcode 994.腐烂的橘子
(5) leetcode 204.计数质数
(6) HJ25. 数据分类处理
模拟套卷链接:https://www.nowcoder.com/test/1088888/summary
网上YT分享: 2 1.https://www.nowcoder.com/discuss/972445(考点范围+题型+解析) . https://www.nowcoder.com/discuss/828230(有考点范围+题型)
二.部分机试题及答案
有的没有处理输入,修改main函数的入参验证各种输入
-
字符串筛选排序: 输入一个由n个大小写字母组成的字符串,按照Ascii码值从小到大的排序规则,查找字符串中第k个最小ascii码值的字母(k>=1), 输出该字母所在字符串的位置索引(字符串的第一个字符位置索引为0)。 k如果大于字符串长度,则输出最大ascii值的字母所在字符串的位置索引,如果有重复的字母,则输出字母的最小位置索引
class TestCaseString_select_sort(): def __init__(self, str1, k): self.str1 = str1 self.k = k print(str1) str2=list(str1) print(str2) str2.sort() print(str2) if k>len(str1): target = str2[-1] else: target = str2[self.k-1] print(target) index=str1.find(target) print(index) if __name__ == "__main__": TestCaseString_select_sort("ABa#sdfd",2) -
GPU执行时长: 为了充分发挥GPU算力,需要尽可能多的将任务交给GPU执行,现在有一个任务数组,数组元素表示在这1秒内新增的任务个数且每秒都有新增任务, 假设GPU最多一次执行n个任务,一次执行耗时1秒,在保证GPU不空闲情况下,最少需要多长时间执行完成
class GPUCalculate(): def __init__(self, max, arry): self.max = max self.arry = arry # 执行时间 time=0 #还剩多少个任务 more=0 for i in arry: if (i+more)>max: more=i+more-max else: more=0 time+=1 while(more>0): more=more-max time+=1 print(time) if __name__=="__main__": GPUCalculate(3,[1,2,3,4,5,6]) -
按索引范围反转文章片段: 输入一个英文文章片段,翻转指定区间的单词顺序,标点符号和普通字母一样处理。例如输入字符串"I am a developer. ",区间[0,3],则输出"developer. a am I"。
class Solution(): def reverse_string(self, string, index1, index2): list1=string.split(" ") print(list1) list2=list1[index1:index2+1] print(list2) print(list2[::-1]) return list2[::-1] if __name__=="__main__": Solution().reverse_string("I am a developer. ", 0, 3) -
数组去重和排序: 给定一个乱序的数组,删除所有的重复元素,使得每个元素只出现一次,并且按照出现的次数从高到低进行排序,相同出现次数按照第一次出现顺序进行先后排序
class Solution(): def remove_duplicates_sort(self, arry): #list1用来存放arry中出现的元素 # list1=[] # for i in arry: # if i not in list1: # list1.append(i) # print(list1) # #dict用来存放arry里每个元素及其出现的次数 # dict={} # for i in list1: # dict[i]=arry.count(i) # print(dict) dict={} for i in arry: dict[i]=arry.count(i) print(dict) dict=sorted(dict.items(),key=lambda x:x[1],reverse=True) print(dict) arry1=[] for i in dict: arry1.append(i[0]) print(arry1) return arry1 if __name__=="__main__": Solution().remove_duplicates_sort([1,3,3,3,2,4,4,5]) -
字符串序列判定: 输入两个字符串S和L,都只包含英文小写字母。S长度<=100,L长度<=500,000。判定S是否是L的有效字串。 判定规则:S中的每个字符在L中都能找到(可以不连续),且S在L中字符的前后顺序与S中顺序要保持一致。 (例如,S="ace"是L="abcde"的一个子序列且有效字符是a、c、e,而"aec"不是有效子序列,且有效字符只有a、e)
class Soluction(): def string_judge(self,str1,str2): l1=len(str1) l2=len(str2) index=-1 i=0 j=0 count=0 while i<l2: while j<l1: if str1[j] == str2[i]: i+=1 j+=1 count+=1 print(count) if count%l1==0: index=i else: i+=1 if j==l1: j=0 if i==l2: break print(index-1) return index-1 if __name__=="__main__": Soluction().string_judge("ace", "asadcdedabcdefffafcfef") -
太阳能板最大面积 给航天器一侧加装长方形或正方形的太阳能板(图中的红色斜线区域),需要先安装两个支柱(图中的黑色竖条),再在支柱的中间部分固定太阳能板。 但航天器不同位置的支柱长度不同,太阳能板的安装面积受限于最短一侧的那根支柱长度。如图:
class Solution(): def sunboard_area(self,list): high=list[0]/2 chang=0 for i in list[1:]: if i<high: break else: chang+=1 area=chang*high print(area) return area if __name__=="__main__": Solution().sunboard_area([10,9,8,7,6,5,4,3,2,1]) -
勾股数元组 如果3个正整数(a,b,c)满足a^2 + b^2 = c^2的关系,则称(a,b,c)为勾股数(著名的勾三股四弦五),为了探索勾股数的规律, 我们定义如果勾股数(a,b,c)之间两两互质(即a与b,a与c,b与c之间均互质,没有公约数),则其为勾股数元祖(例如(3,4,5)是勾股数元祖, (6,8,10)则不是勾股数元祖)。请求出给定范围[N,M]内,所有的勾股数元组
class Soluction(): def gougu_tuple(self,m,n): # 勾股数元祖满足两个条件:1,a^2 + b^2 = c^2;2,勾股数(a,b,c)之间两两互质(即a与b,a与c,b与c之间均互质,没有公约数) list=[] flag=0 for j in range(m,n+1): for k in range(j+1,n+1): for x in range(k+1,n+1): if self.exist_divisors(j,k,x)==0 and j**2+k**2==x**2: print("(%d,%d,%d)是勾股数元组"%(j,k,x)) list.append((j,k,x)) flag=1 if flag==0: print("NA") return "NA" else: print(list) return list def exist_divisor(self,num1,num2): flag=0 for i in range(2,min(num1,num2)+1): if num1%i==0 and num2%i==0: flag=1 print("%d和%d的公约数是%d"%(num1,num2,i)) break print(flag) return flag def exist_divisors(self,num1,num2,num3): flag=0 if self.exist_divisor(num1,num2)==1 or self.exist_divisor(num1,num3)==1 or self.exist_divisor(num2,num3)==1: flag=1 print(flag) return flag if __name__=="__main__": Soluction().gougu_tuple(1,20) -
流水线 一个工厂有m条流水线,来并行完成n个独立的作业,该工厂设置了一个调度系统,在安排作业时,总是优先执行处理时间最短的作业。 现给定流水线个数m,需要完成的作业数n, 每个作业的处理时间分别为t1,t2…tn。请你编程计算处理完所有作业的耗时为多少? 当n>m时,首先处理时间短的m个作业进入流水线,其他的等待,当某个作业完成时,依次从剩余作业中取处理时间最短的进入处理
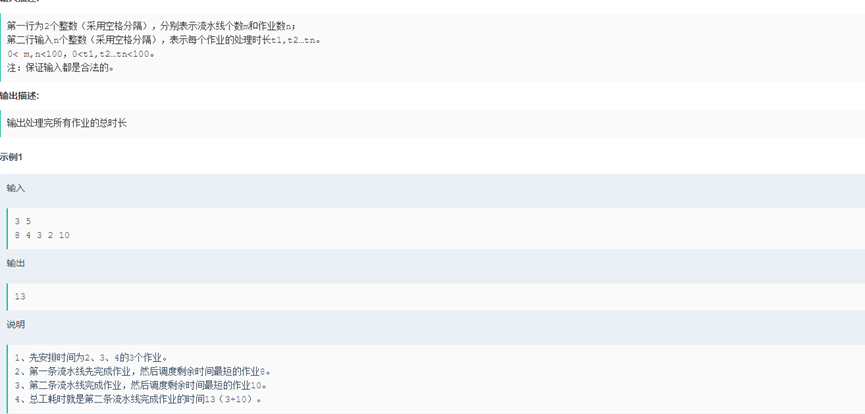
class Soluction():
def waterline(self,m,n,list):
#将作业的处理时间由小到大排序,依次按这个顺序进入流水线
list.sort()
print(list)
#m条流水线的作业时间放在time这个列表里
time=list[:m]
print(time)
#将剩下的作业依次进入流水线,直到全部进入
for i in range(m,n):
list1=list[i:n]
#找到最早完成作业的流水线,下一个作业会进入到该线上
min_time=min(time)
min_time_index=time.index(min_time)
#将该流水线的工作时间更新
min_time+=list1[0]
time[min_time_index]=min_time
print(time)
total=max(time)
print(total)
return total
if __name__=="__main__":
Soluction().waterline(3,5,[8,4,3,2,10])9.整型数组按个位值排序 给定一个非空数组(列表),其元素数据类型为整型,请按照数组元素十进制最低位从小到大进行排序,十进制最低位相同的元素,相对位置保持不变。 当数组元素为负值时,十进制最低位等同于去除符号位后对应十进制值最低位
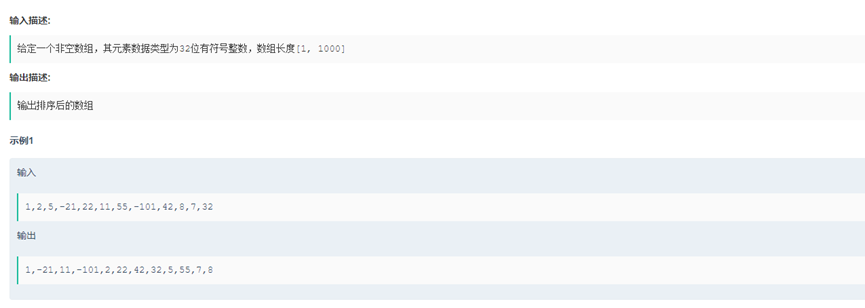
class Soluction():
def intarry_sort_by_gewei(self,nums):
nums.sort(key=lambda x:abs(x)%10)
print(nums)
return nums
if __name__=="__main__":
Soluction().intarry_sort_by_gewei([1,2,5,-21,22,11,55,-101,42,8,7,32])10.矩阵最大值 给定一个仅包含0和1的N*N二维矩阵,请计算二维矩阵的最大值,计算规则如下: 1、 每行元素按下标顺序组成一个二进制数(下标越大越排在低位),二进制数的值就是该行的值。矩阵各行值之和为矩阵的值。 2、允许通过向左或向右整体循环移动每行元素来改变各元素在行中的位置。 比如: [1,0,1,1,1]向右整体循环移动2位变为[1,1,1,0,1],二进制数为11101,值为29。
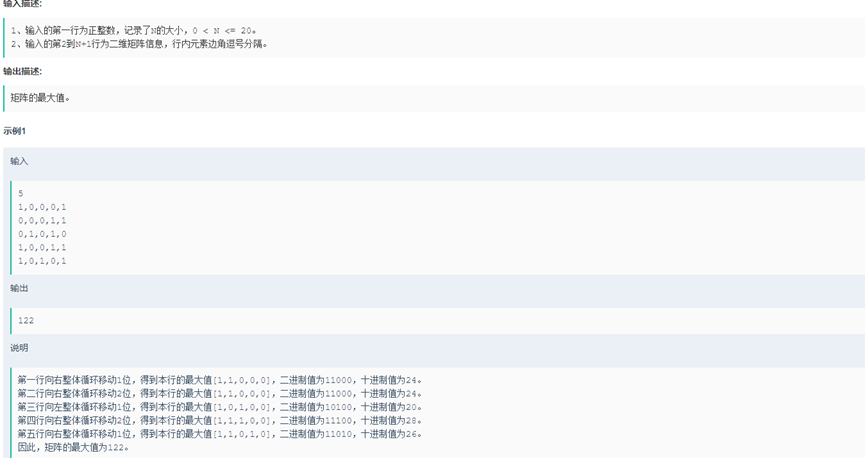
class Soluction():
def matrix_maxvalue(self,n,erwei_list):
max_value = 0
for i in range(n):
print(erwei_list[i])
list1 = []
#向右整体循环移动每行元素,求该行元素组成的最大十进制数
for j in range(n):
str1 = self.list_to_string(erwei_list[i],j)
num1 = self.bin_to_integer(str1)
list1.append(num1)
max1 = max(list1)
print(max1)
#所有行的最大十进制数相加,即为矩阵的最大值
max_value += max1
print(max_value)
return max_value
#将二位矩阵的行的所有元素拼接成字符串
def list_to_string(self,list,start):
#list为一维列表erwei_list[i]
length = len(list)
str1=""
for i in range(start, length):
str1 += str(list[i])
if start>0:
for j in range(0,start):
str1 += str(list[j])
print(str1)
return str1
#将二进制字符串转化为整型
def bin_to_integer(self,str1):
#二进制转为十进制
num = int(str1, 2)
print(num)
return num
if __name__=="__main__":
Soluction().matrix_maxvalue(5,[[1,0,0,0,1],[0,0,0,1,1],[0,1,0,1,0],[1,0,0,1,1],[1,0,1,0,1]])11.给定一个整型数组,请从该数组中选择3个元素组成最小数字并输出(如果数组长度小于3,则选择数组中所有元素来组成最小数字)。
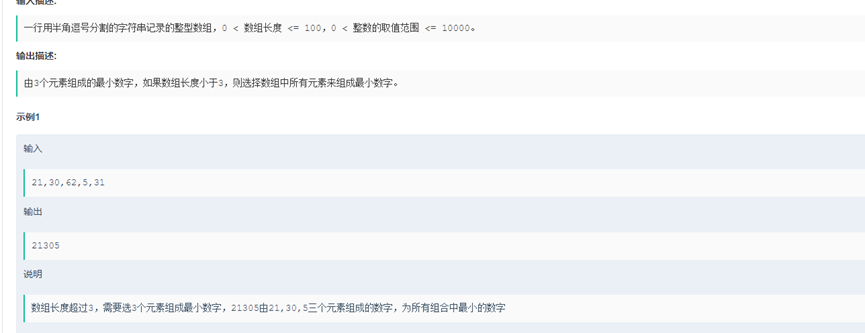
class Soluction():
def min_num(self,nums):
#将整型数字由小往大排序,最小的前3个元素即组成最小数字
nums.sort()
print(nums)
length = len(nums)
if length < 3:
n = length
else:
n = 3
min_value = 0
for i in range(n):
min_value = min_value*10 + nums[i]
print(min_value)
return min_value
if __name__=="__main__":
Soluction().min_num([0,2,4,1,6,44])12.VLAN资源池
VLAN是一种对局域网设备进行逻辑划分的技术,为了标识不同的VLAN,引入VLAN ID(1-4094之间的整数)的概念。 定义一个VLAN ID的资源池(下称VLAN资源池),资源池中连续的VLAN用开始VLAN-结束VLAN表示,不连续的用单个整数表示,所有的VLAN用英文逗号连接起来。 现在有一个VLAN资源池,业务需要从资源池中申请一个VLAN,需要你输出从VLAN资源池中移除申请的VLAN后的资源池 按照VLAN由小到大升序字符串输出,如果申请的VLAN ID不在资源池里,返回原资源池由小到大升序字符串输出
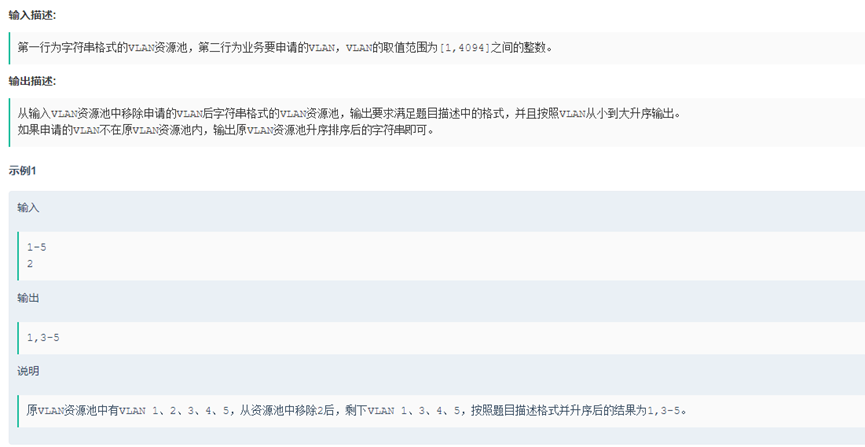
class Soluction():
def remove_valnID(self,vlan,id):
#先把vlan里各个ID拆分开,放在列表里;然后移除申请的id,再将剩下的列表排序后按格式组成字符串
list = vlan.split(',')
for r in list:
index = str(r).find('-')
if index != -1:
list1 = r.split('-')
for i in range(int(list1[0]),int(list1[-1])+1):
list.insert(index,i)
index+=1
list.remove(r)
else:
index = list.index(r)
list.remove(r)
r = int(r)
list.insert(index,r)
print(list)
list.sort()
list.remove(id)
print(list)
list2=[]
list3=[]
j=0
tmp =[]
while j < len(list)-1:
if (list[j] + 1 != list[j+1]):
if list2 != []:
min2 = min(list2) - 1
list3.append("-".join((str(min2), str(max(list2)))))
list2=[]
print("list3=%s" % list3)
if list[j] not in tmp:
list3.append(list[j])
j+=1
else:
list2.append(int(list[j + 1]))
j += 1
print(list2)
tmp = list2
continue
print(list2)
if list2!=[]:
min2=min(list2)-1
list3.append("-".join((str(min2),str(max(list2)))))
print("list3=%s"%list3)
return list3
if __name__=="__main__":
Soluction().remove_valnID("1-5,7,8", 2)13.冒泡排序(Bubble Sort):
也是一种简单直观的排序算法。它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。 走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。这个算法的名字由来是因为越小的元素会经由交换慢慢"浮"到数列的顶端 从列表开头,重复下一轮“冒泡”,每进行一轮“冒泡”,需要比较的元素都少一个,直到没有元素对需要比较时,整个列表排序完成
class Soluction():
def bubble_sort(self, arr):
length = len(arr)
#i表示排到最后的i个元素已经就位,只需要排列剩下的length-1-i个元素
for i in range(0,length):
for j in range(length-1-i):
if arr[j] > arr[j+1]:
tmp = arr[j]
arr[j] = arr[j+1]
arr[j+1] = tmp
print(arr)
return arr
if __name__=="__main__":
Soluction().bubble_sort([64, 34, 25, 12, 22, 11, 90])14.最长连续子序列 有N个正整数组成的一个序列。给定整数sum,求长度最长的连续子序列,使他们的和等于sum,返回此子序列的长度,如果没有满足要求的序列,返回-1
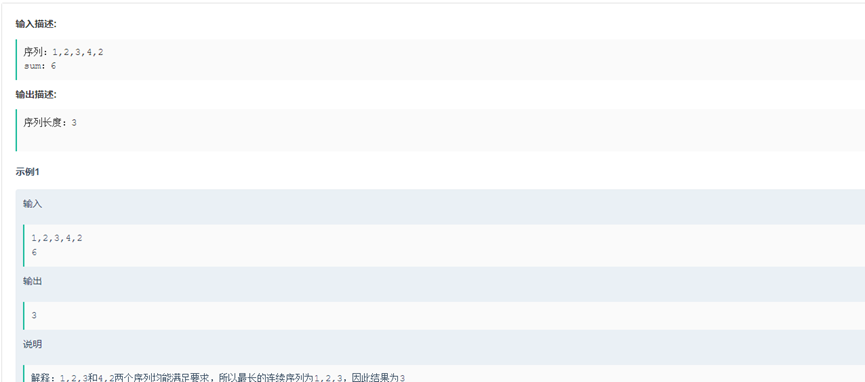
class Soluction():
def longest_arry(self,nums,sum):
#先找出所有和为sum的连续正数序列:维持left~right的连续整数区间,求和:(1)若该区间之和小于sum,right前移(right++);
# (2)若该区间之和等于sum,right前移,并且输出当前区间;(3)若该区间之和大于sum,left前移。循环结束条件是判断left是否超过了sum/2
answer=[]
current_sum=0
left=1
right=2
while left<=sum/2:
#求left到right之间的连续数字相加之和,公式为right*(right+1)/2-(left-1)*left/2
current_sum=right*(right+1)/2-left*(left-1)/2
current_answer=[]
if current_sum==sum:
for i in range(left,right+1):
current_answer.append(i)
answer.append(current_answer)
right+=1
elif current_sum<sum:
right+=1
else:
left+=1
print(answer)
#在所有和为sum的连续正数序列里,找哪些序列里的元素全部在nums里,找出最长的序列
length=0
for ele in answer:
for element in ele:
if element not in nums:
break
current_length=len(ele)
length=max(length,current_length)
print(length)
if length==0:
return -1
else:
return length
if __name__=="__main__":
Soluction().longest_arry([1,2,3,4,7,8,6,5],15)15.单词接龙
单词接龙的规则是:可用于接龙的单词首字母必须要前一个单词的尾字母相同;当存在多个首字母相同的单词时,取长度最长的单词,如果长度也相等, 则取字典序最小的单词;已经参与接龙的单词不能重复使用。 现给定一组全部由小写字母组成单词数组,并指定其中的一个单词作为起始单词,进行单词接龙,请输出最长的单词串,单词串是单词拼接而成,中间没有空格。
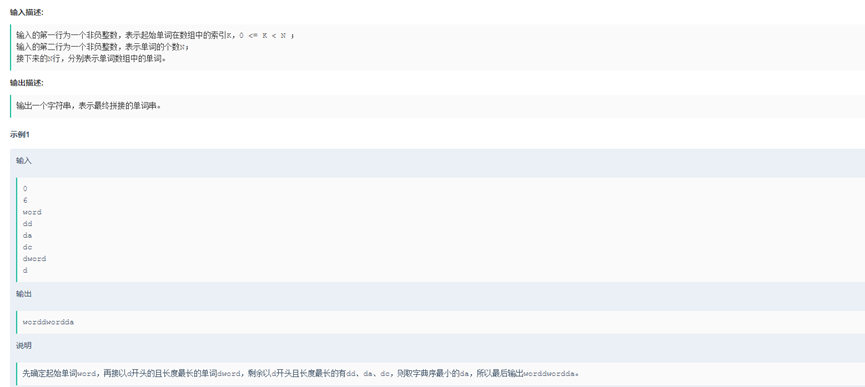
class Soluction():
def word_dragon(self,start_index,n,word_list):
result=word_list[start_index]
#start为起始单词
start=word_list[start_index]
word_list.remove(start)
next_word=self.next_word(start[-1],word_list)
while next_word!="":
result+=next_word
start=next_word
word_list.remove(next_word)
next_word=self.next_word(start[-1],word_list)
print(result)
return result
#根据单词末尾字母找出所有下一个可接龙的单词,再找出长度最长的那个,长度相同时找字典序最小的
def next_word(self,end,word_list):
list1 = []
for i in word_list:
if i[0]==end:
list1.append(i)
print(list1)
if list1==[]:
longest_word=""
return longest_word
max_length=0
longest_word = list1[0]
for i in list1:
length=len(i)
if max_length<length:
max_length=length
longest_word=i
elif max_length==length:
longest_word=min(i,longest_word)
print(longest_word)
return longest_word
if __name__=="__main__":
Soluction().word_dragon(0,6,["word","dd","da","dc","dword","d"])16.男女孩比例:
阿里巴巴的一道面试题:说澳大利亚的父母喜欢女孩,如果生出来的是女孩,就不再生了,如果是男孩就继续生,直到生到第一个女孩为止,问若干年后,男女的比例是多少?
import random
class Sluction():
def child_bili(self,n):
#生男生女的几率各是50%,所以男孩用奇数表示,女孩用偶数表示;
#获取随机数来表示生的孩子,n表示家庭数量
#如果生的是男孩,就递归调用生孩子方法,是女孩就停止
boy_num = 0
girl_num = 0
for i in range(n):
digit=self.add_child()
print(digit)
while digit>=0:
if digit % 2 == 0:
girl_num += 1
break
elif digit % 2 == 1:
boy_num += 1
digit=self.add_child()
else:
print("孩子性别错误!%d" % digit)
break
print(boy_num)
print(girl_num)
bili=float(boy_num)/float(girl_num)
print("男孩女孩比例为%f"%bili)
return bili
def add_child(self):
digit = random.randint(0, 100)
return digit
if __name__=="__main__":
Sluction().child_bili(10000)
#结果一般是0.96~0.99,偶尔也出现1.00717.字符串数组的最长公共前缀:
给你一个大小为 n 的字符串数组 strs ,其中包含n个字符串 , 编写一个函数来查找字符串数组中的最长公共前缀,返回这个公共前缀。

class Solution:
def longestCommonPrefix(self , strs: List[str]) -> str:
if strs==[]:
return ""
if len(strs)==1:
return strs[0]
length=len(strs[0])
for x in strs[1::]:
length=min(len(x),length)
print(length)
common_pre=""
flag=False
for i in range(0,length):
for y in strs[1::]:
if strs[0][i]!=y[i]:
flag=False
break
else:
flag=True
if flag==False:
#注意用flag的作用是当数组是['a','b']时,执行一次内循环就结束了,此时公共前缀应该返回""
break
else:
common_pre+=strs[0][i]
return common_pre18.字符串变形:
对于一个长度为 n 字符串,我们需要对它做一些变形。
首先这个字符串中包含着一些空格,就像"Hello World"一样,然后我们要做的是把这个字符串中由空格隔开的单词反序,同时反转每个字符的大小写。
比如"Hello World"变形后就变成了"wORLD hELLO"。
数据范围: 1le n le 10^61≤n≤106 , 字符串中包括大写英文字母、小写英文字母、空格。
class Solution:
def trans(self , s: str, n: int) -> str:
str_list=s.split(' ')
str_list.reverse()
print(str_list)
list1=[]
for ele in str_list:
ele_new=""
for i in range(0,len(ele)):
if ele[i].islower() is True:
ele_new+=(ele[i].upper())
else:
ele_new+=(ele[i].lower())
print(ele_new)
list1.append(ele_new)
s_new=" ".join(list1)
return s_new最后
以上就是繁荣手套最近收集整理的关于机试算法编程题练习附答案-python的全部内容,更多相关机试算法编程题练习附答案-python内容请搜索靠谱客的其他文章。








发表评论 取消回复