presto
- presto简介
- 前期准备
- presto官方打包版本部署
- 连接客户端并测试
- IDEA本地编译运行presto源码
- 关于presto集群部署和后续深入使用
presto简介
presto是Facebook的一个开源的分布式查询引擎。主要是java语言开发。是一个能够处理PB级别数据交互分析查询的项目。在大数据领域会有较多的应用。那我最近是公司可能有这方面的业务需求,所以对presto展开了一些学习和研究。然后,基于我个人的学习习惯,我会倾向于先直接上手搭建,然后再来慢慢摸索它的一些使用,所以这一篇没有presto实现原理和背后逻辑相关的介绍,如果有这方面的需求,大家可以移步看看其他人的文章。那么这篇主要是讲什么呢?主要就是介绍presto的服务搭建和一些我踩的坑的记录。也算是整合一下网上很多朋友的内容。本次使用的presto版本为0.271,会有官方打包好的版本部署和git上开源presto的本地编译与启动。这种方式会比较方便通过本地运行来查看断点,看源码等等,对比起来会更好找问题。
前期准备
presto下载:
官方包:presto-server-0.271.tar.gz
github:github版本
以上两个下载地址的presto,第一个是官方编译打包后的版本,下载大小在1.28G左右。后一个是git上的presto开源代码,不同分支里面就是不通的版本。大家根据需要选择自己的版本下载,如果要两个版本同时使用方便看源码,最好就保持两个版本一致。我这里是下载的0.271的版本。
presto客户端下载:
官方包:presto-cli-0.271-executable.jar
客户端我这里主要是用来测试使用,presto服务搭建好后,使用客户端连接presto然后可以执行查询。同样的客户端选择与presto对应的版本下载。
presto官方打包版本部署
以下内容是我根据网友的文章和官方文档获取的。实际上官方文档就可以很好的帮助我们完成presto的单机版的简单部署。官方文档0.272(官方最新版本是0.272,所以这里文档是0.272的,我没有找到对应0.271的文档,但是基本的使用没什么影响)。
- 将presto压缩包presto-server-0.271.tar.gz拷贝到服务器路径下。安装路径视自己的情况来定。

- 命令解压文件
tar -zxvf presto-server-0.271.tar.gz
- 命令更改文件夹名称(解压后文件夹名称较长,我改短了的)
mv presto-server-0.271 presto
- 进入presto路径下,创建etc文件夹(此文件夹下主要是放配置文件)
cd presto/
mkdir etc
网上有大佬的在这一步提到在presto路径下创建data文件夹。根据我这个版本的测试,服务启动是会自己创建data文件夹的。data文件夹下会存放日志和一些运行的数据。
完成后:
-
配置文件
根据官方文档,可以使用最小配置,单间创建一个presto。因为presto的分布式属性,所以presto的设计中有两个重要的角色,一个协调器coordinator,一个是工作器workers。在实际应用中,多采用一个coordinator和多个workers的部署方式。本次的测试中,采用单机的方式,也就是部署一个presto服务即作为coordinator也作为workers。
以下配置文件在官方文档中均有最小配置和各个配置的说明,可以参阅。-
Node Properties
说明:节点配置文件,在presto部署的集群中,给每个节点做配置。主要作用是标识同一个集群下单个节点的唯一性。
存放路径:etc/node.properties
内容:# 环境的名称。集群中的所有 Presto 节点必须具有相同的环境名称。 node.environment=production # 此 Presto 安装的唯一标识符。这对于每个节点必须是唯一的。此标识符应在 Presto 重新启动或升级期间保持一致。如果在一台机器上运行多个 Presto 安装(即同一台机器上的多个节点),每个安装必须有一个唯一标识符。 node.id=ffffffff-ffff-ffff-ffff-ffffffffffff-001 # 数据目录的位置(文件系统路径,前面创建的data文件夹的路径)。Presto 将在此处存储日志和其他数据。 node.data-dir=/home/presto/data # 这里是我踩的坑,服务器上有双网卡,在部署集群时,workers和coordinator通信确认节点状态时会自动获取服务器ip # 创建地址访问,这时如果获取到的ip不是服务指定的ip,则会连接不上,可以通过此配置指定该节点的ip地址。则在presto的内部会获取这个配置的ip来组成访问路径。 node.internal-address=192.168.31.85特殊说明:
关于"node.internal-address" 配置,通过查看presto源码,可以找到。目前我在网上没有找到相关的说明。文件NodeConfig.java,里面可以看到关于node.preperties的可能配置。
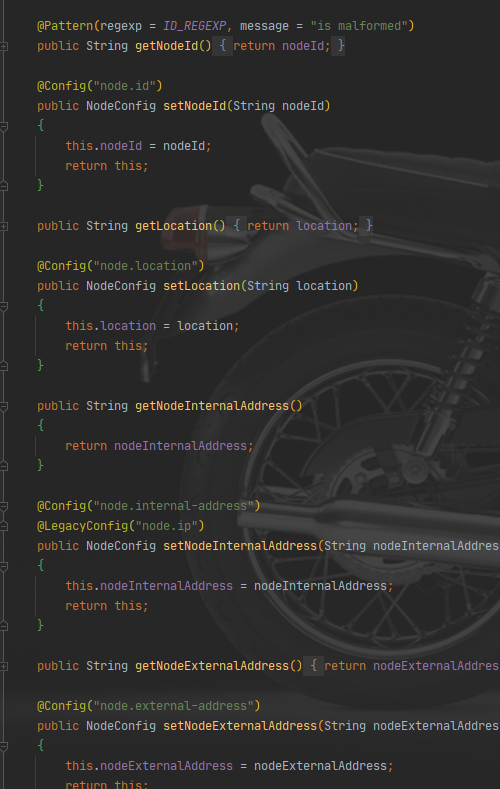
-
JVM Config
说明:presto启动java虚拟机的配置选择。可以指定运行内存。
存放路径:etc/jvm.config
内容:-server -Xmx4G -XX:+UseG1GC -XX:G1HeapRegionSize=32M -XX:+UseGCOverheadLimit -XX:+ExplicitGCInvokesConcurrent -XX:+HeapDumpOnOutOfMemoryError -XX:+ExitOnOutOfMemoryError -
Config Properties
说明:config.properties是presto服务的主要配置文件,通过该配置文件可以指定该服务是作为coordinator还是workers,或者同时作为两个角色存在。当然实际使用中,最佳配置是一个服务作为coordinator。
存放路径:etc/config.properties
即作为coordinator又作为workers配置内容:# 是否作为coordinator部署 coordinator=true # 是否将该节点作为coordinator和workers同时工作 node-scheduler.include-coordinator=true # 服务端口 http-server.http.port=8080 # 单个查询在所有分布节点上能用的内存之和 query.max-memory=2GB # 单个查询在单个节点上用户内存能用的最大量 query.max-memory-per-node=1GB #查询可以在任何一台机器上使用的最大用户和系统内存量,其中系统内存是读取器、写入器和网络缓冲区等执行期间使用的内存 # 该内存值 + heapHeadroom < availableMemory(jvm允许运行内存值),其中heapHeadroom = availableMemory* 0.3 query.max-total-memory-per-node=2GB # Presto 使用 Discovery 服务查找集群中的所有节点。每个 Presto 实例都会在启动时向 Discovery 服务注册。为了简化部署并避免运行额外的服务,Presto 协调器可以运行 Discovery 服务的嵌入式版本。它与 Presto 共享 HTTP 服务器,因此使用相同的端口 discovery-server.enabled=true # presto服务coordinator的发现uri,不得以“/”结束。 discovery.uri=http://localhost:8080作为coordinator的最小配置:
coordinator=true node-scheduler.include-coordinator=false http-server.http.port=8080 query.max-memory=2GB query.max-memory-per-node=1GB query.max-total-memory-per-node=2GB discovery-server.enabled=true discovery.uri=http://localhost:8080作为workers的最小配置:
coordinator=false http-server.http.port=8080 query.max-memory=2GB query.max-memory-per-node=1GB query.max-total-memory-per-node=2GB discovery.uri=http://localhost:8080 -
Log Levels
说明:日志输出等级。presto输出的日志会记录在/data/var/log下面。主要有三个日志文件:http-request.log、launcher.log、server.log。主要是运行日志记录在server.log中。日志配置文件log.properties。四个日志输出等级:DEBUG、INFO、WARN、ERROR
存放路径:etc/log.properties。
内容:com.facebook.presto=DEBUG -
Catalog Properties
说明:catalog是presto中各类连接器的配置所在。根据官方文档,presto支持多种类型的数据源连接,包括且不限于非关系型数据库和关系型数据库。我贴一个源码中catalog下面的各类连接的配置文件。
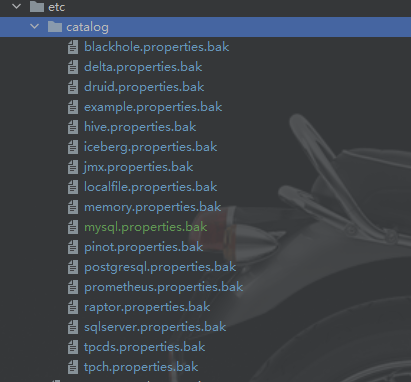
同样在官方文档中,也有各类连接器的示例说明可供参考:
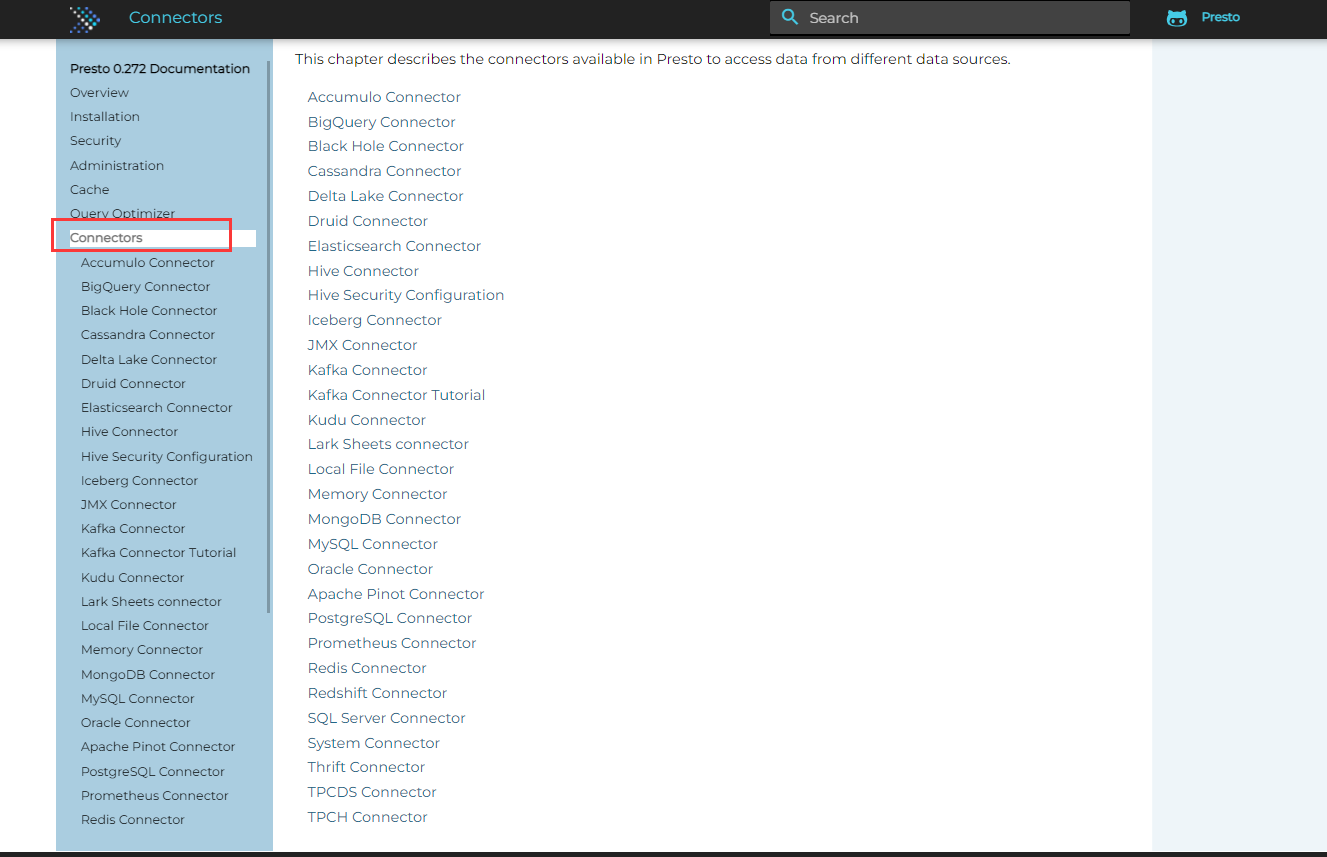
本次简单测试了以下连接TiDB数据源,因此使用配置文件mysql.properties。
存放路径:/catalog/mysql.properties
内容:connector.name=mysql connection-url=jdbc:mysql://192.168.31.80:4000 connection-user=root connection-password=root
-
-
服务启动
presto配置完成后就可以通过命令启动。
前台运行命令:
bin/launcher run
后台运行命令:
bin/launcher start
通过查看data/var/log/server.log可以看服务是否启动成功。并且成功加载了我们配置的数据源连接器。
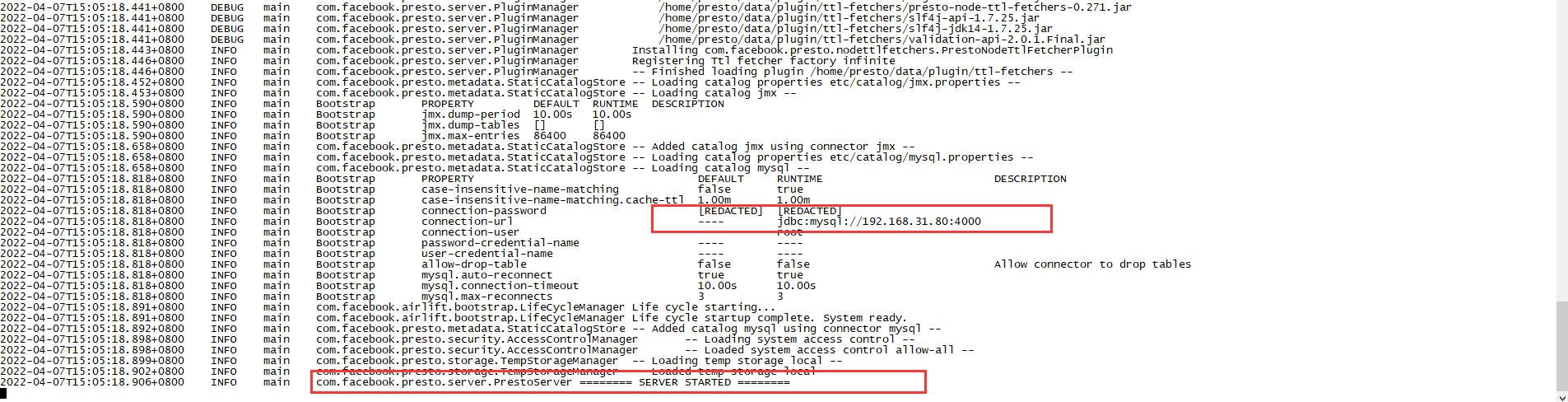
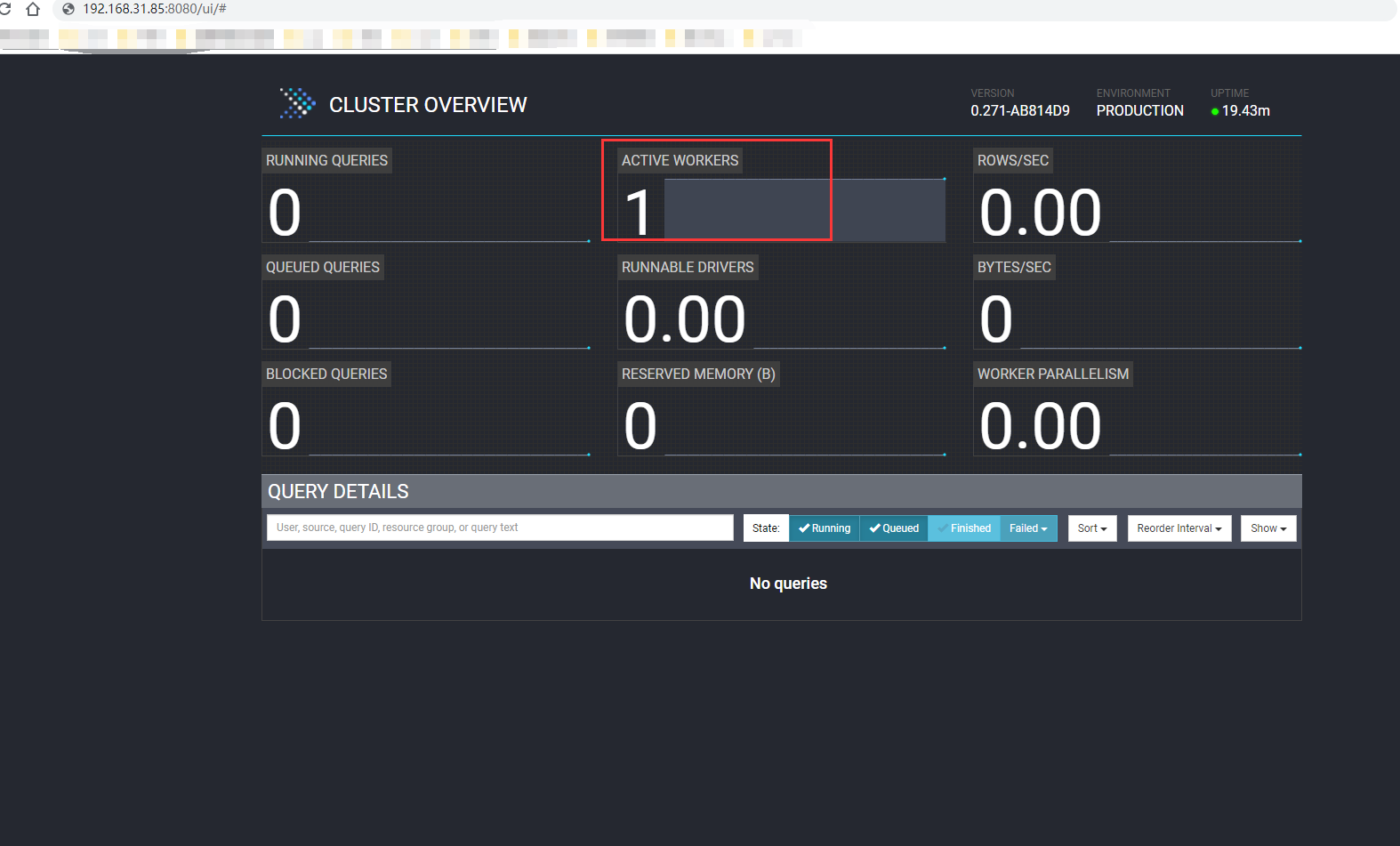
最后访问config.properties中配置的服务路径,可以打开presto的一个监管界面。http://localhost:8080.
连接客户端并测试
将下载的客户端jar包presto-cli-0.271-executable.jar拷贝到服务器中presto/bin/路径下,可以更改文件名称为presto。并授权文件。
命令连接presto服务:./更改的名称 -server ip:端口 – catalog
./presto --server 192.168.31.85:8080 --catalog mysql
连接成功:

选择数据库:
use database;
执行查询sql:
show tables;
查询表:
select ID from TB_DRUG;
特殊说明:在没有选择数据库的情况下,执行查询时在sql中带上数据库名称即可。例如:datasource.databse.tableName =>> mysql.testbase.orderT
当我在执行查询表sql时出现了表不存在的异常。
先说解决办法,在排除表真的的不存在在数据库中的情况下。
在mysql.properties中添加如下配置:
# 不区分大小写名称匹配
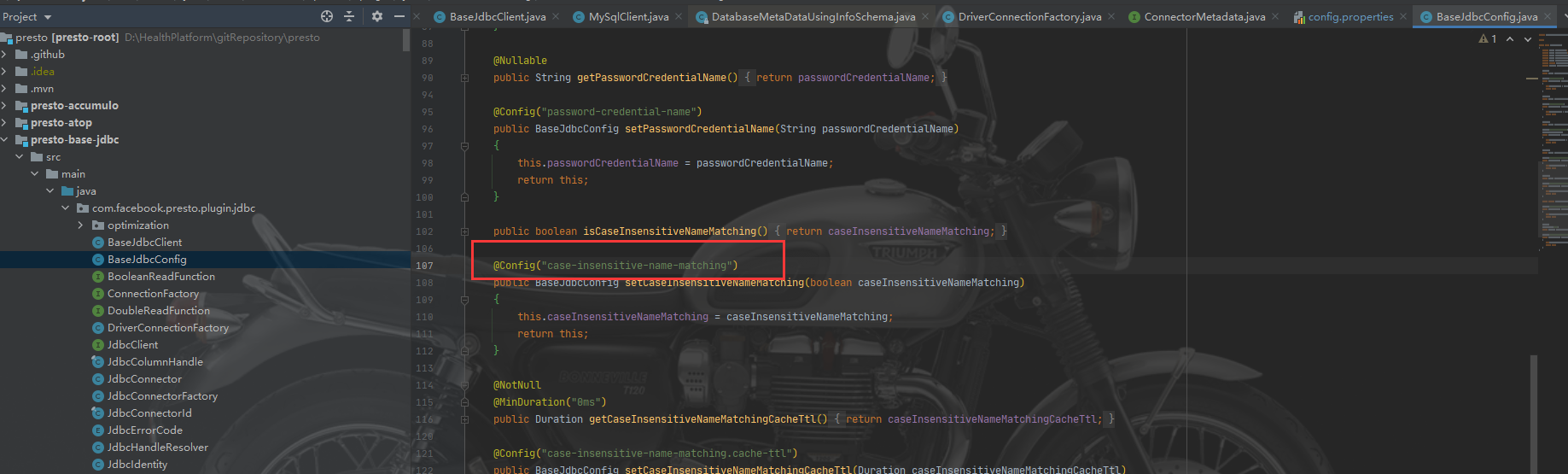
case-insensitive-name-matching=true
解决思路,如有兴趣,可以看一看。
踩坑:这里是我踩的一个坑,在官方和网上我找的文档中,都没有提到的一个配置是“case-insensitive-name-matching”不区分大小写名称匹配。这个问题出现情况是,我连接了TiDb数据源,并且成功执行了show tables的sql。但是当在查询具体的表时,总是报表不存在,实际表也是存在的,然后为了找问题,因此下载了git上的presto源码,断点后一步一步查看,最终发现在presto中,将客户端发送的sql中出现的大写表名称转换成了小写,并在执行客户端sql前做了一次表是否存在的判断。这个判断是presto内部通过执行sql查询数据库中的INFORMATION_SCHEMA.TABLES去匹配。此时表名称被转换为小写,然后在数据库中INFORMATION_SCHEMA.TABLES存的表名称为大写。因此查询无结果,报异常表不存在。增加case-insensitive-name-matching=true配置后问题解决。
问题查找流程:感兴趣的可以看看问题是怎么查找的。
异常截图:
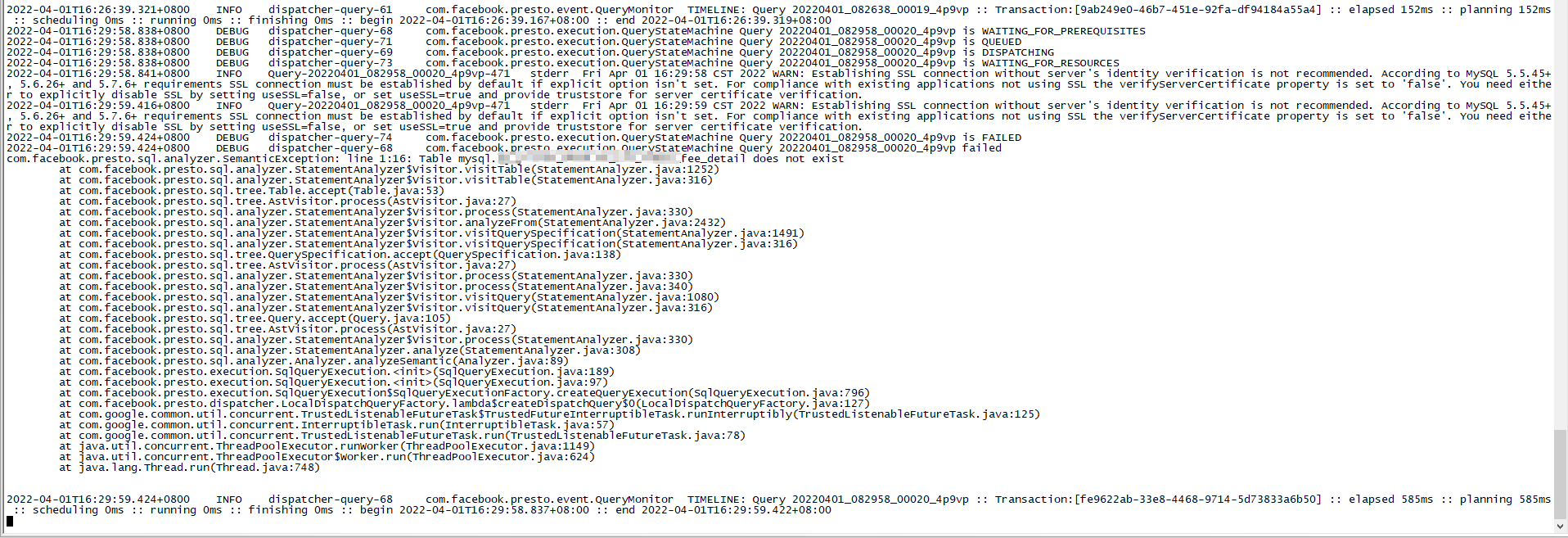
首先是定位到报错的地方在类StatementAnalyzer中的1252行,如果运行的版本和源码不一致可能行数有偏差。
可以看到日志输出的代码:
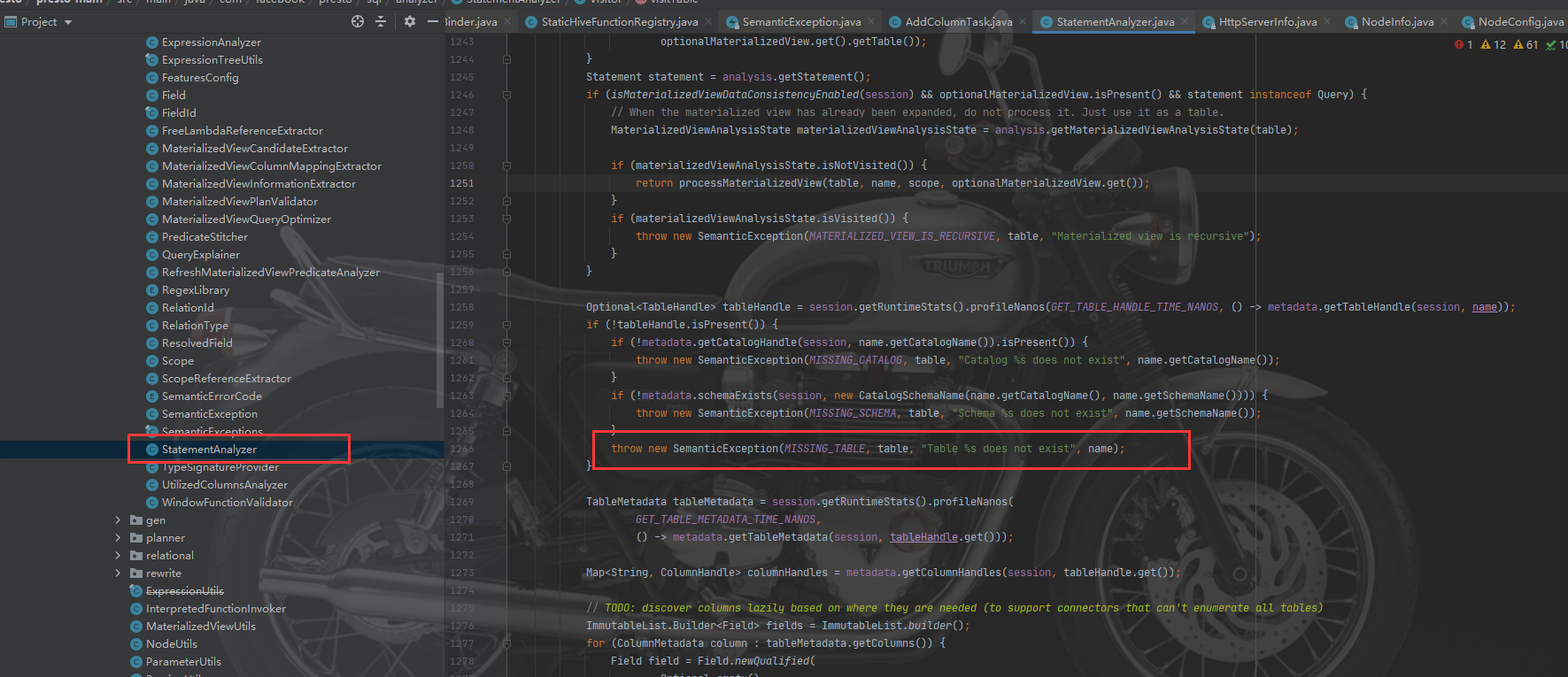
找到位置后就很简单了,打断点,进调试。最终会调用到类MySqlClient中的getTables方法。
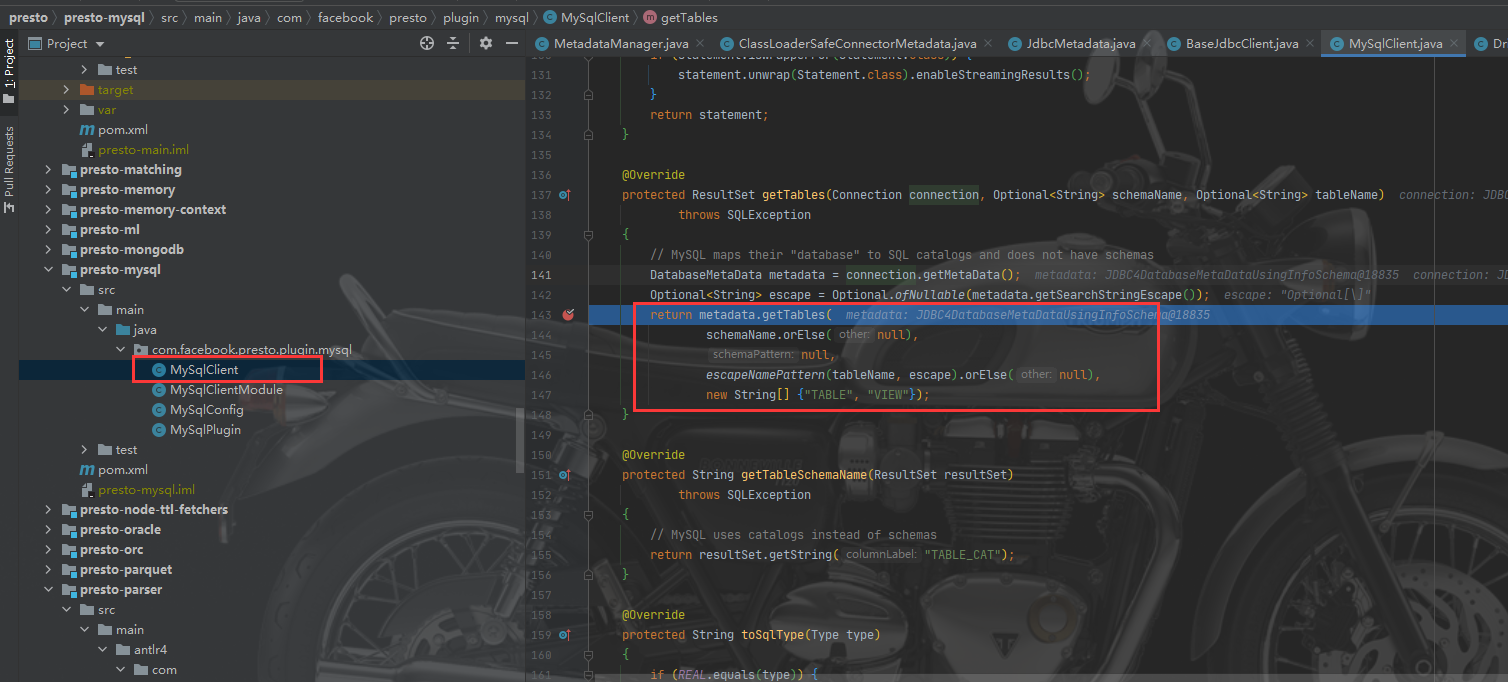
接着进入方法中查询数据库表的方法调用,就可以发现前面提到的判断表是否存在的查询:
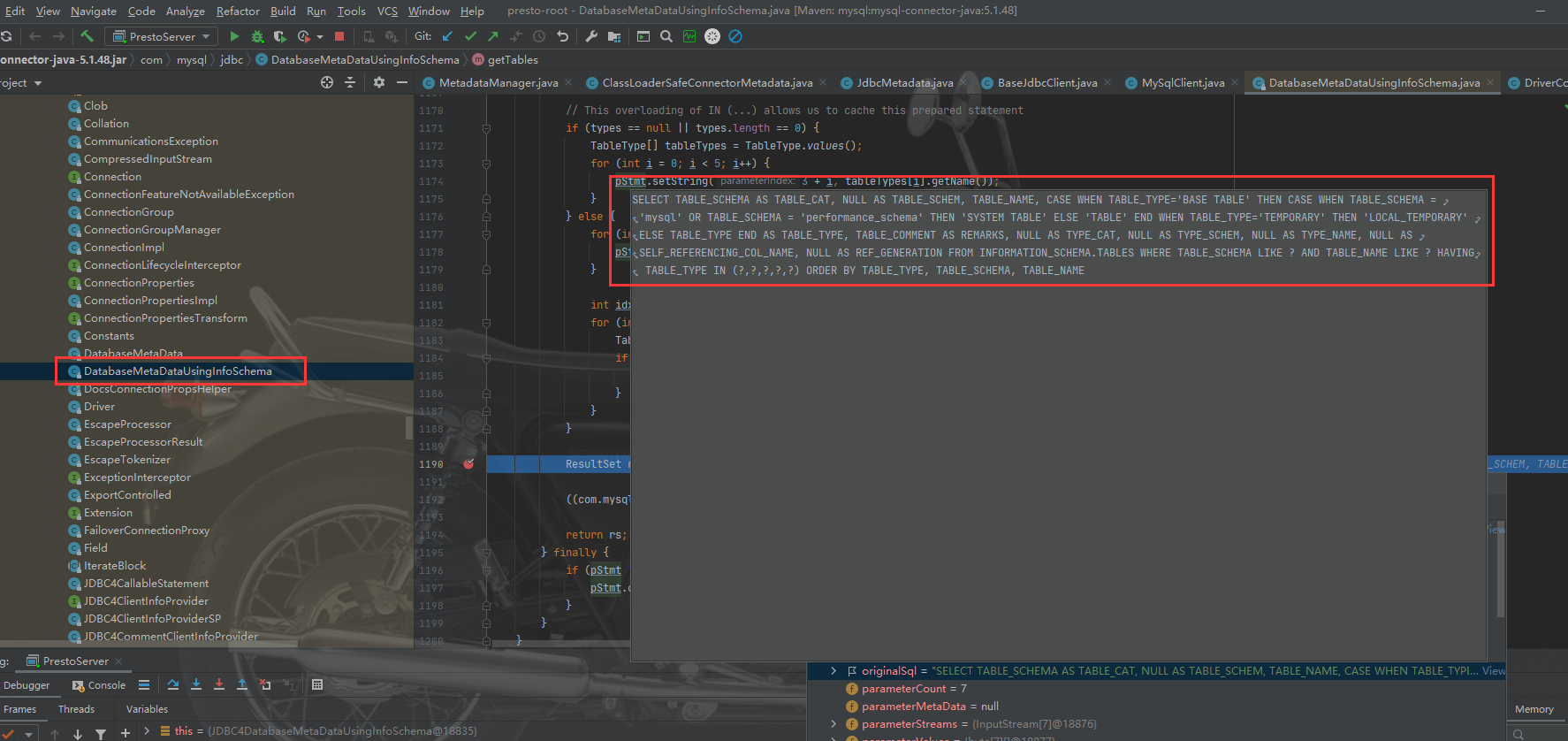
然后就是找解决办法,第一想到的肯定是会有配置来处理这个事情。原理就是找到加载mysql.properties的类。最终找到的就是BaseJdbcConfig.java。
到此,在linux上部署就完成了。可以成功查询数据库。
IDEA本地编译运行presto源码
此部分内容比较基础,网上资料也很多,我就转载一个大佬的博客,给大家参考。注:如需删除请联系我。
在Windows的IDEA运行Presto
关于presto集群部署和后续深入使用
集群部署按照前面给出的配置,对不同节点做相应的配置即可完成。目前对于presto还是处于小白状态,此篇仅作为自己的学习笔记来记录,归纳整合网上零散的资料,方便自己后面的学习。关于presto更加深入的使用还在学习当中,共同进步!!!!!!!!
最后
以上就是雪白大神最近收集整理的关于presto分布式查询引擎踩坑记录presto简介前期准备presto官方打包版本部署连接客户端并测试IDEA本地编译运行presto源码关于presto集群部署和后续深入使用的全部内容,更多相关presto分布式查询引擎踩坑记录presto简介前期准备presto官方打包版本部署连接客户端并测试IDEA本地编译运行presto源码关于presto集群部署和后续深入使用内容请搜索靠谱客的其他文章。








发表评论 取消回复