Presto分布式SQL查询引擎
一、课前准备
-
jdk版本要求:Java 8 Update 151 or higher (8u151+), 64-bit
-
安装好hadoop集群
-
安装好hive
二、课堂主题
-
介绍presto
-
presto架构
-
prsto安装部署
-
presto使用
三、课堂目标
-
理解presto
-
独立完成presto安装部署
-
使用presto
四、知识要点
1. Presto是什么?
-
Hadoop提供了大数据存储与计算的一整套解决方案;但是它采用的是MapReduce计算框架,只适合离线和批量计算,无法满足快速实时的Ad-Hoc查询计算的性能要求
-
Hive使用MapReduce作为底层计算框架,是专为批处理设计的。但随着数据越来越多,使用Hive进行一个简单的数据查询可能要花费几分到几小时,显然不能满足交互式查询的需求。
-
Facebook于2012年秋开始开发了Presto,每日查询数据量在1PB级别。Facebook称Presto的性能比Hive要快上10倍多。2013年Facebook正式宣布开源Presto。
-
Presto是apache下开源的==OLAP的分布式SQL查询引擎==,数据量支持从GB到PB级别的数据量的查询,并且查询时,能做到秒级查询。
-
另外,Presto虽然可以解析SQL,但它并非是标准的数据库;不能替代如MySQL、PostgreSQL、Oracle关系型数据库,不是用于处理OLTP的
-
presto是利用分布式查询,高效的对海量数据进行查询;
-
presto可以用来查询hdfs上的海量数据;但是,presto不仅仅可以用来查询hdfs的数据,它还被设计成能够对很多其他的数据源的数据做查询;
-
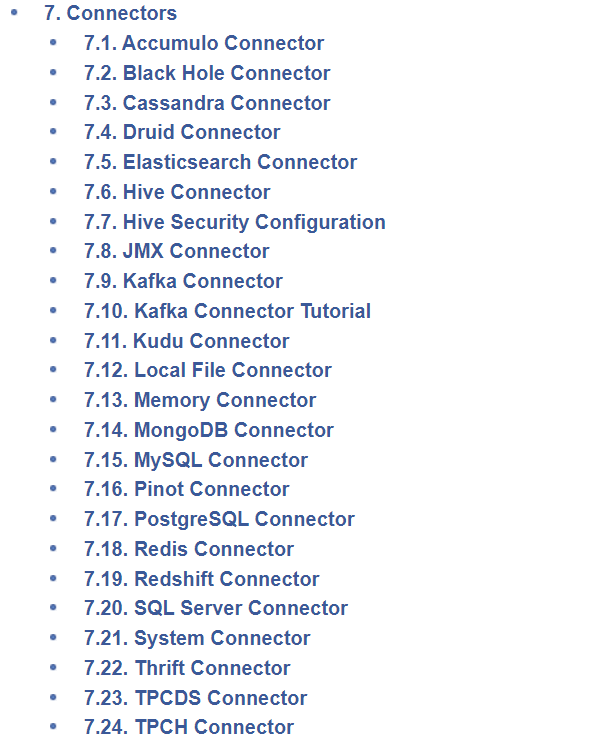
比如数据源有HDFS、Hive、Druid、Kafka、kudu、MySQL、Redis等;下图是Presto 0.237支持的数据源
-
2. Presto架构
-
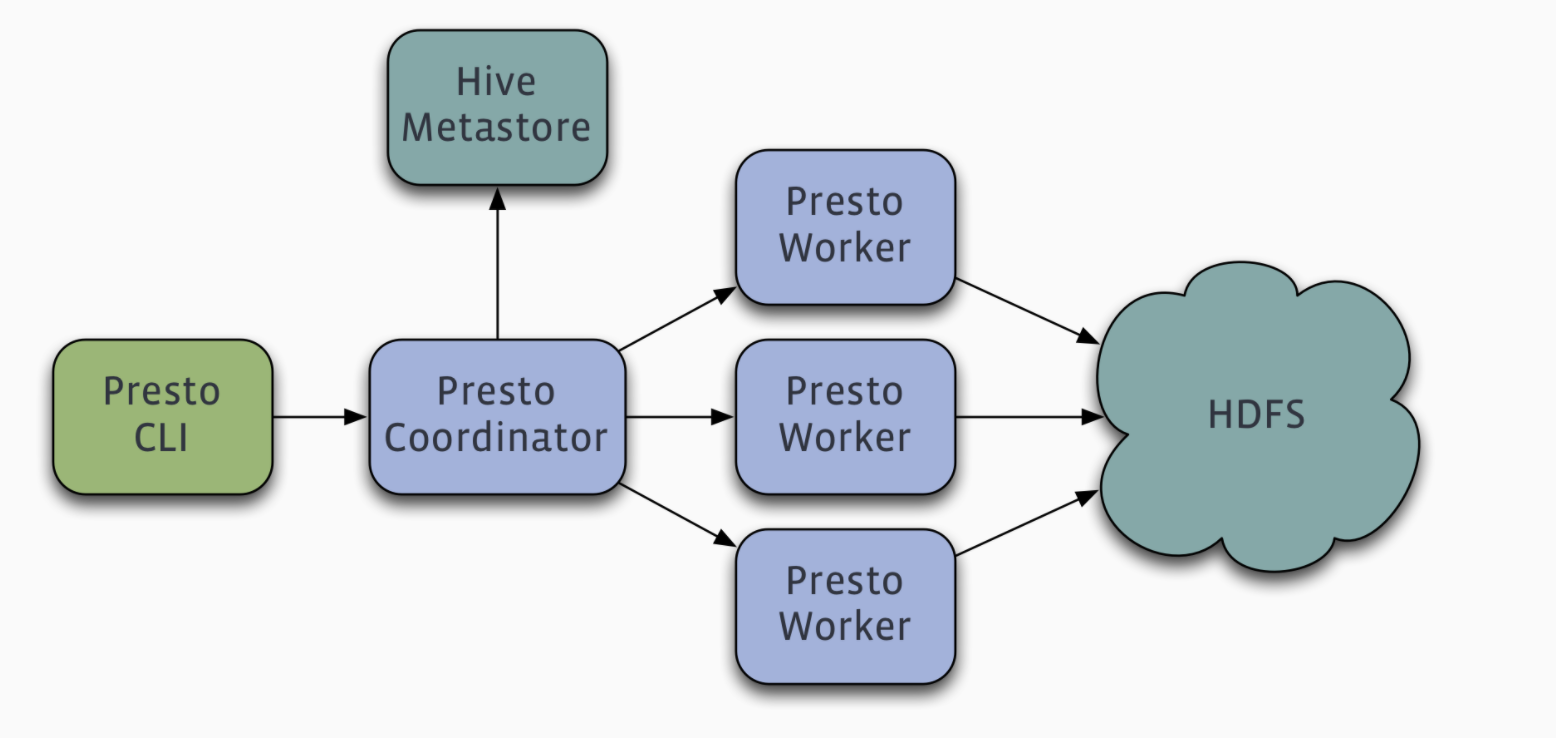
Presto查询引擎是一个Master-Slave的架构,Coordinator是主,worker是从;
-
一个presto集群,由一个Coordinator节点,一个Discovery Server节点(通常内嵌于Coordinator节点中),多个Worker节点组成
-
Coordinator负责接收查询请求、解析SQL语句、生成执行计划、任务调度给Worker节点执行、worker管理。
-
Worker节点是工作节点;负责实际执行查询任务Task;Worker节点启动后向Discovery Server服务注册;Coordinator从Discovery Server获得可以正常工作的Worker节点。
-
-
Presto CLI提交查询到Coordinator
-
catalog表示数据源;每个catalog包含Connector及Schema
-
其中Connector是数据源的适配器;presto通过Connector与不同的数据源(如Redis、Hive、Kafka)连接;如果配置了Hive Connector,需要配置一个Hive MetaStore服务为Presto提供Hive元信息,Worker节点与HDFS交互读取数据。
-
Schema类似于MySQL中的数据库的概念;Schema中又包含Table,类似于MySQL中的表
-
3. Presto特点
1. 优点
-
高性能:Presto基于内存计算,减少数据的落盘,计算更快;轻量快速,支持近乎实时的查询
-
多数据源:通过配置不同的Connector,presto可以连接不同的数据源,所以可以将来自不同数据源的表进行连接查询
-
支持SQL:完全支持ANSI SQL,并提供了sql shell命令行工具
-
扩展性:可以根据实际的需要,开发特定的数据源的Connector,从而可以sql查询此数据元的数据
2. 缺点
-
虽然Presto是基于内存做计算;但是数据量大时,数据并非全部存储在内存中;
-
比如Presto可针对PB级别的数据做计算,但Presto并非将所有数据全部存储在内存中,不同场景有不同做法;
-
比如count, avg等聚合运算,会读部分数据,计算,在清理内存;再读数据再计算、清理内存;所以占据内存并不是很高;
-
但是如果做join操作,中间可能会产生大量的临时数据,造成执行速度变慢;join时,hive的数据反而更快些。所以如果join的话,建议在hive中,先进行join生成宽表,再使用presto查询此宽表数据
-
3. presto与impala对比
-
impala性能比presto稍好
-
但是,impala只能对接hive;而presto能对接很多种类的数据源
4. 安装部署Presto
官网地址:https://prestodb.io/
github地址
presto集群规划
| 主机名 | 角色 |
|---|---|
| node01 | coordinator |
| node02 | worker |
| node03 | worker |
1. 安装部署Presto Server
-
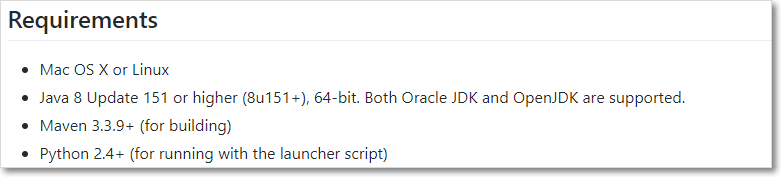
presto要求
-
-
确认python版本是2.4+
-

-
确认java版本是8u151+;若如下图,是151之前的版本,安装presto时,需要特殊处理
-

1. 下载安装包
https://repo1.maven.org/maven2/com/facebook/presto/presto-server/0.237/presto-server-0.237.tar.gz
然后将tar.gz包上传到node01的/kkb/soft目录
2. 解压
cd /kkb/soft/
tar -xzvf presto-server-0.237.tar.gz -C /kkb/install/3. 配置JAVA
-
若java版本低于8u151,那么需要上传8u151+的版本压缩包到/kkb/soft;若不低于,则跳过此步骤
-
解压
cd /kkb/soft/
tar -xzvf jdk-8u251-linux-x64.tar.gz -C /kkb/install/
cd /kkb/install/
scp -r jdk1.8.0_251/ node02:$PWD
scp -r jdk1.8.0_251/ node03:$PWD-
指定presto使用的java版本(3个节点都要修改)
ln -s presto-server-0.237/ presto
vim /kkb/install/presto/bin/launcher添加如下内容
PATH=/kkb/install/jdk1.8.0_251/bin:$PATH
java -version注意:需要加在exec "$(dirname "$0")/launcher.py" "$@"之前

3. 创建相关目录
-
创建存储数据文件夹;presto将存储log及其他数据到此目录
cd /kkb/install
cd presto
mkdir data-
创建存储配置文件的文件夹
<span style="color:#333333">mkdir etc</span>4. 添加JVM配置文件
-
etc目录下添加jvm.config配置文件
cd /kkb/install/presto/etc
vim jvm.config-
内容如下
-server
-Xmx16G
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:+ExitOnOutOfMemoryError</span>5. 配置数据源
presto支持不同的数据源,通过catalog进行配置;不同的数据源,有不同的catalog
-
现以hive数据源为例,创建个hive的catalog
-
etc中创建目录catalog
cd /kkb/install/presto-server-0.237/etc
mkdir catalog
cd catalog
vim hive.properties-
添加如下内容 注:因编辑问题凡遇到<span style="color:#333333"> 、</span>自动忽略
<span style="color:#333333">connector.name=hive-hadoop2
hive.metastore.uri=thrift://node03:9083</span>6. 分发presto
<span style="color:#333333">cd /kkb/install/
scp -r presto node02:/kkb/install/
scp -r presto node03:/kkb/install/</span>7. 配置node.properties
-
进入三台节点的
/kkb/install/presto/etc目录,修改node.properties文件
<span style="color:#333333">cd /kkb/install/presto/etc
vim node.properties</span>-
三台节点的内容==分别==如下
<span style="color:#333333"># node01如下内容
node.environment=production
node.id=ffffffff-ffff-ffff-ffff-fffffffffff1
node.data-dir=/kkb/install/presto/data
# node2如下内容
node.environment=production
node.id=ffffffff-ffff-ffff-ffff-fffffffffff2
node.data-dir=/kkb/install/presto/data
# node03如下内容
node.environment=production
node.id=ffffffff-ffff-ffff-ffff-fffffffffff3
node.data-dir=/kkb/install/presto/data</span>说明:
node.environment 环境的名称;presto集群各节点的此名称必须保持一致
node.id presto每个节点的id,必须唯一
node.data-dir 存储log及其他数据的目录
8. 配置config.properties
-
通过配置config.properties文件,指明server是coordinator还是worker
-
虽然presto server可以同时作为coordinator和worker;但是为了更好的性能,一般让server要么作为coordinator,要么作为worker
-
presto是主从架构;主是coordinator,从是worker
-
现设置node01作为coordinator节点;node02、node03节点作为worker节点
-
node01上配置coordinator
<span style="color:#333333">cd /kkb/install/presto/etc
vim config.properties</span>-
添加如下内容
<span style="color:#333333">coordinator=true
node-scheduler.include-coordinator=false
http-server.http.port=8880
query.max-memory=50GB
query.max-memory-per-node=1GB
discovery-server.enabled=true
discovery.uri=http://node01:8880</span>说明:
coordinator=true 允许此presto实例作为coordinator
node-scheduler.include-coordinator 是否允许在coordinator上运行work
http-server.http.port presto使用http服务进行内部、外部的通信;指定http server的端口
query.max-memory 一个查询运行时,使用的所有的分布式内存的总量的上限
query.max-memory-per-node query在执行时,使用的任何一个presto服务器上使用的内存上限
discovery-server.enabled presto使用discovery服务,用来发现所有的presto节点
discovery.uri discovery服务的uri
-
node02、node03上配置worker
<span style="color:#333333">cd /kkb/install/presto/etc
vim config.properties</span>-
添加如下内容
<span style="color:#333333">coordinator=false
http-server.http.port=8880
query.max-memory=50GB
discovery.uri=http://node01:8880</span>9. 启动presto server
-
若要用presto对接hive数据,需要启动hive metastore服务
-
上课环境:hive安装在node03上,所以在node03启动metastore服务
<span style="color:#333333">nohup hive --service metastore > /dev/null 2>&1 &</span>-
在node01、node02、node03上分别启动presto server,执行以下命令
<span style="color:#333333">cd /kkb/install/presto
# 前台启动,控制台打印日志
bin/launcher run
# 或使用后台启动presto
bin/launcher start</span>-
jps查看,各节点出现名为PrestoServer的进程
-
日志所在目录
<span style="color:#333333">/kkb/install/presto/data/var/log</span>
2. 安装部署Presto命令行接口
1. 下载安装包
-
下载地址:https://repo1.maven.org/maven2/com/facebook/presto/presto-cli/0.237/presto-cli-0.237-executable.jar
-
安装包放到node01的目录
/kkb/soft
2. 重命名文件
<span style="color:#333333">cd /kkb/soft
mv presto-cli-0.237-executable.jar prestocli</span>3. 增加可执行权限
<span style="color:#333333">chmod u+x prestocli</span>4. 启动presto cli
-
注意:==先启动HDFS==
-
查看presto客户端jar包的使用方式
<span style="color:#333333">./prestocli --help</span>-
两种方式;方式一
<span style="color:#333333">./prestocli --server node01:8880 --catalog hive --schema default</span>说明:
--catalog hive 中的hive指的是etc/catalog中的hive.properties的文件名
-
方式二
<span style="color:#333333">java -jar presto-cli-0.237-executable.jar --server node01:8880 --catalog hive --schema default</span>-
退出presto cli
<span style="color:#333333">quit</span>
5. 体验命令操作
Presto的命令行操作,相当于Hive命令行操作。每个表必须要加上schema前缀;例如
<span style="color:#333333">select * from schema.table limit 5
或者切换到指定的schema,再查询表数据
use myhive;
select * from score limit 3;</span>
3. 安装部署Presto 可视化客户端
1. 下载安装包
-
presto有个开源的带可视化界面的客户端yanagishima
-
源码下载地址:yanagishima
-
官网地址
-
将下载的包yanagishima-18.0.zip上传到node01点/kkb/soft目录
2. 解压缩
<span style="color:#333333">cd /kkb/soft
unzip -d /kkb/install yanagishima-18.0.zip
# 若出现-bash: unzip: command not found,表示没有安装unzip;需要安装;然后再解压缩
sudo yum -y install unzip zip
cd /kkb/install/yanagishima-18.0</span>
3. 修改配置文件
-
修改yanagishima.properties文件
<span style="color:#333333">cd /kkb/install/yanagishima-18.0/conf
vim yanagishima.properties</span>-
添加如下内容
<span style="color:#333333">jetty.port=7080
presto.datasources=kkb-presto
presto.coordinator.server.kkb-presto=http://node01:8880
catalog.kkb-presto=hive
schema.kkb-presto=default
sql.query.engines=presto</span>
4. 启动yanagishima
<span style="color:#333333">后台启动:nohup bin/yanagishima-start.sh >yanagishima.log 2>&1 &
[hadoop@node01 yanagishima-18.0]$ pwd
/kkb/install/yanagishima-18.0
前台启动:bin/yanagishima-start.sh
>yanagishima.log </span>-
node01上多出名为YanagishimaServer的进程
-
启动web界面
http://node01:7080
在界面中进行查询了
若ui界面显示很慢,或者不显示,可以尝试将node01替换成相应的ip地址
-
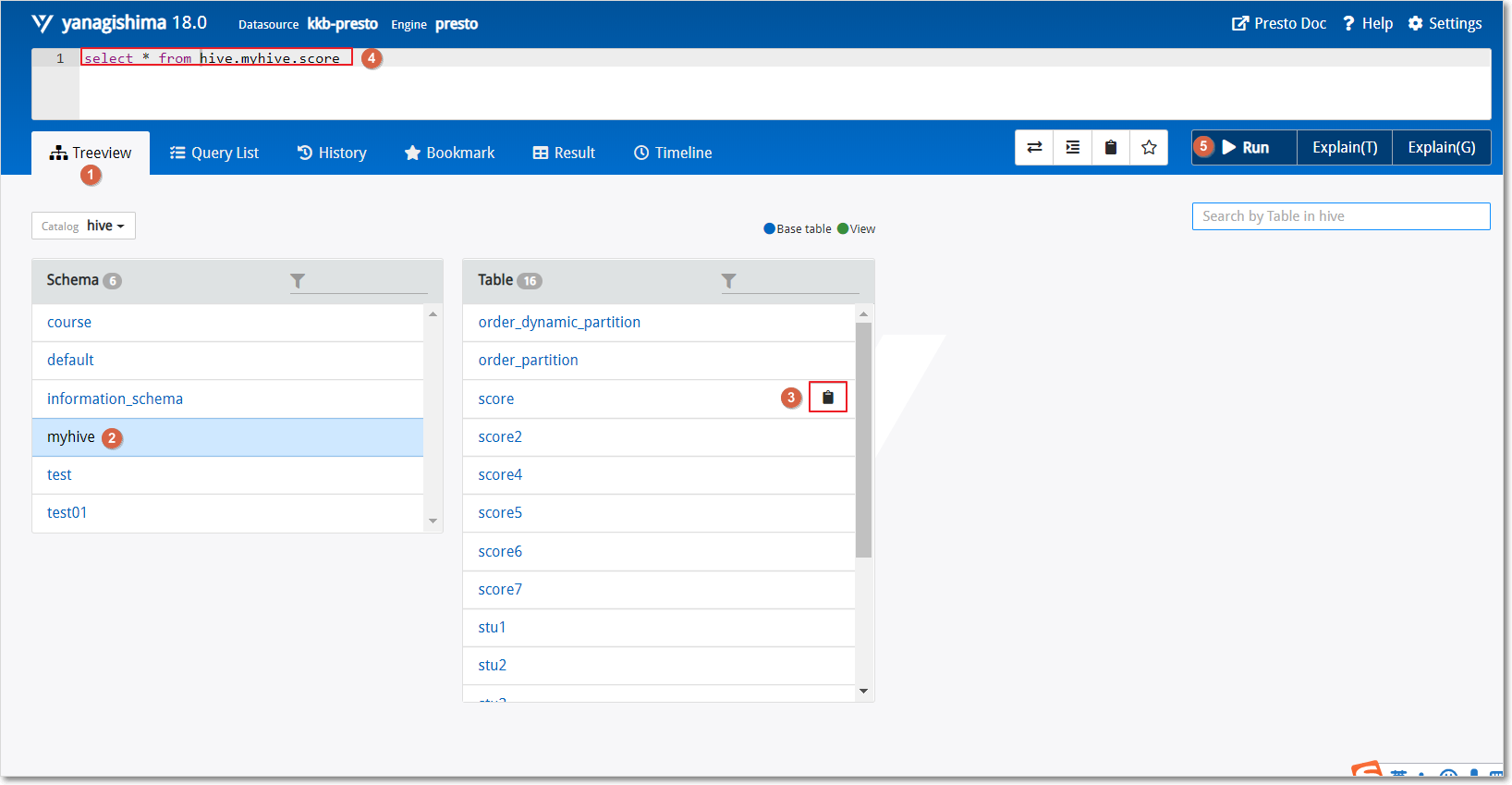
查看表结构;
-
每个表后面都有个复制键,点一下会复制完整的表名,然后再上面框里面输入sql语句,ctrl+enter组合键或Run按钮执行显示结果
-
-
这里有个Tree View,可以查看所有表的结构,包括Schema、表、字段等。
-
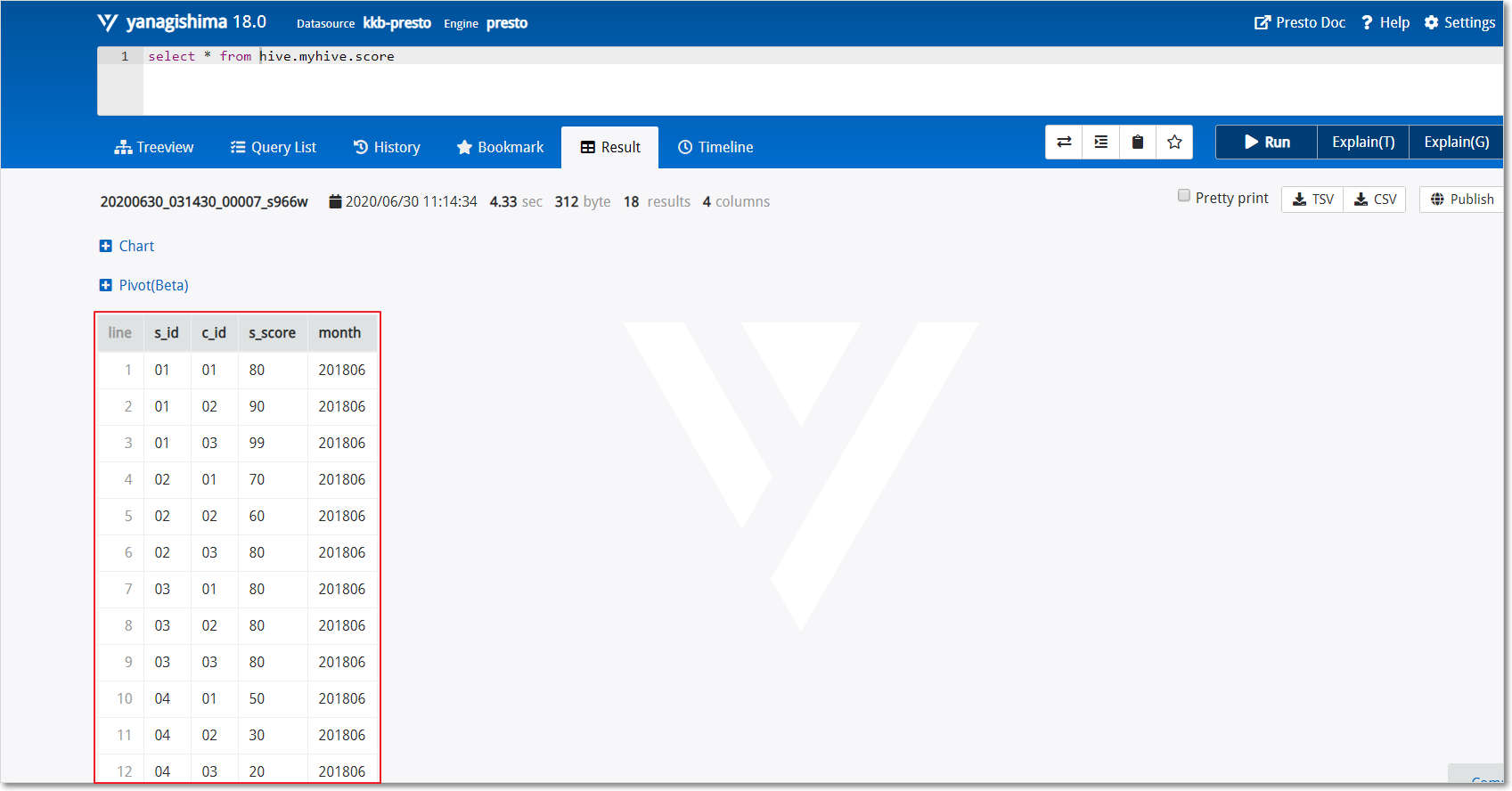
比如执行
select * from hive.myhive.score,这个句子里Hive这个词可以删掉,即变成select * from myhive.score;hive是上面配置的Catalog名称 -
注意:==sql语句末尾不要加分号;否则报错==
-
5. Presto查询及优化
1. Presto sql语法
-
以下用hive connector演示
-
查看schema有哪些
<span style="color:#333333">SHOW SCHEMAS;</span>-
查看有哪些表
<span style="color:#333333">SHOW TABLES;</span>-
创建schema
<span style="color:#333333">语法:CREATE SCHEMA [ IF NOT EXISTS ] schema_name
CREATE SCHEMA testschema;</span>-
删除schema
<span style="color:#333333">语法:DROP SCHEMA [ IF EXISTS ] schema_name
drop schema testschema;</span>-
创建表
<span style="color:#333333">语法:CREATE TABLE [ IF NOT EXISTS ]
table_name (column_name data_type [ COMMENT comment],... ]
create table stu4(id int, name varchar(20));</span>-
创建表CTAS
<span style="color:#333333">语法:
CREATE TABLE [ IF NOT EXISTS ] table_name [ ( column_alias, ... ) ]
[ COMMENT table_comment ]
[ WITH ( property_name = expression [, ...] ) ]
AS query
[ WITH [ NO ] DATA ]
create table if not exists myhive.stu5 as select id, name from stu1;</span>-
删除表中符合条件的行
<span style="color:#333333">语法:DELETE FROM table_name [ WHERE condition ]
说明:hive connector只支持一次性的删除一个完整的分区;不支持删除一行数据
DELETE FROM order_partition where month='2019-03';</span>-
查看表的描述信息
<span style="color:#333333">DESCRIBE hive.myhive.stu1;</span>-
ANALYZE获得表及列的统计信息
<span style="color:#333333">语法:ANALYZE table_name
ANALYZE hive.myhive.stu1;</span>-
prepare 给statement起一个名称,等待将来的执行
-
execute执行一个准备好的statement
<span style="color:#333333">语法:PREPARE statement_name FROM statement
prepare my_select1 from select * from score;
execute my_select1;
prepare my_select2 from select * from score where s_score < 90 and s_score > 70;
execute my_select2;
prepare my_select3 from select * from score where s_score < ? and s_score > ?;
execute my_select3 using 90, 70;</span>-
EXPLAIN:查询一个statement的逻辑计划或分布式执行计划,或校验statement
<span style="color:#333333">语法:
EXPLAIN [ ( option [, ...] ) ] statement
where option can be one of:
FORMAT { TEXT | GRAPHVIZ | JSON }
TYPE { LOGICAL | DISTRIBUTED | VALIDATE | IO }
查询逻辑计划语句:
explain select s_id, avg(s_score) from score group by s_id;
等价于
explain (type logical)select s_id, avg(s_score) from score group by s_id;
查询分布式执行计划distributed execution plan
explain (type distributed)select s_id, avg(s_score) from score group by s_id;
校验语句的正确性
explain (type validate)select s_id, avg(s_score) from score group by s_id;
explain (type io, format json)select s_id, avg(s_score) from score group by s_id;</span>-
SELECT查询
<span style="color:#333333">语法:
[ WITH with_query [, ...] ]
SELECT [ ALL | DISTINCT ] select_expr [, ...]
[ FROM from_item [, ...] ]
[ WHERE condition ]
[ GROUP BY [ ALL | DISTINCT ] grouping_element [, ...] ]
[ HAVING condition]
[ { UNION | INTERSECT | EXCEPT } [ ALL | DISTINCT ] select ]
[ ORDER BY expression [ ASC | DESC ] [, ...] ]
[ LIMIT [ count | ALL ] ]
from_item:
table_name [ [ AS ] alias [ ( column_alias [, ...] ) ] ]
from_item join_type from_item [ ON join_condition | USING ( join_column [, ...] ) ]
join_type:
[ INNER ] JOIN
LEFT [ OUTER ] JOIN
RIGHT [ OUTER ] JOIN
FULL [ OUTER ] JOIN
CROSS JOIN
grouping_element:
()
expression
GROUPING SETS ( ( column [, ...] ) [, ...] )
CUBE ( column [, ...] )
ROLLUP ( column [, ...] )
语句:
with语句:用于简化内嵌的子查询
select a, b
from (
select s_id as a, avg(s_score) as b from score group by s_id
) as tbl1;
等价于:
with tbl1 as (select s_id as a, avg(s_score) as b from score group by s_id)
select a, b from tbl1;
多个子查询也可以用with
WITH
t1 AS (SELECT a, MAX(b) AS b FROM x GROUP BY a),
t2 AS (SELECT a, AVG(d) AS d FROM y GROUP BY a)
SELECT t1.*, t2.*
FROM t1
JOIN t2 ON t1.a = t2.a;
with语句中的关系可以串起来(chain)
WITH
x AS (SELECT a FROM t),
y AS (SELECT a AS b FROM x),
z AS (SELECT b AS c FROM y)
SELECT c FROM z;
group by:
select s_id as a, avg(s_score) as b from score group by s_id;
等价于:
select s_id as a, avg(s_score) as b from score group by 1;
1代表查询输出中的第一列s_id
select count(*) as b from score group by s_id;</span>-
可参考官网文档
2. 存储优化
-
合理设置分区
与Hive类似,Presto会根据元信息读取分区数据,合理的分区能减少Presto数据读取量,提升查询性能。
-
使用列式存储
Presto对ORC文件读取做了特定优化,因此在Hive中创建Presto使用的表时,建议采用ORC格式存储。相对于Parquet,Presto对ORC支持更好。
-
使用压缩
数据压缩可以减少节点间数据传输对IO带宽压力,对于即席查询需要快速解压,建议采用snappy压缩
-
预先排序
对于已经排序的数据,在查询的数据过滤阶段,ORC格式支持跳过读取不必要的数据。比如对于经常需要过滤的字段可以预先排序。
3. SQL优化
-
列剪裁
只选择使用必要的字段: 由于采用列式存储,选择需要的字段可加快字段的读取、减少数据量。避免采用*读取所有字段
<span style="color:#333333">[GOOD]: SELECT s_id, c_id FROM score
[BAD]: SELECT * FROM score</span>-
过滤条件必须加上分区字段
对于分区表,where语句中优先使用分区字段进行过滤。day是分区字段,vtime是具体访问时间
<span style="color:#333333">[GOOD]: SELECT vtime, stu, address FROM tbl where day=20200501
[BAD]: SE LECT * FROM tbl where vtime=20200501</span>-
Group By语句优化:
合理安排Group by语句中字段顺序对性能有一定提升。将Group By语句中字段按照每个字段distinct数据多少进行降序排列, 减少GROUP BY语句后面的排序一句字段的数量能减少内存的使用.
<span style="color:#333333">uid个数多;gender少
[GOOD]: SELECT GROUP BY uid, gender
[BAD]: SELECT GROUP BY gender, uid</span>-
Order by时使用Limit, 尽量避免ORDER BY: Order by需要扫描数据到单个worker节点进行排序,导致单个worker需要大量内存
<span style="color:#333333">[GOOD]: SELECT * FROM tbl ORDER BY time LIMIT 100
[BAD]: SELECT * FROM tbl ORDER BY time</span>-
使用近似聚合函数: 对于允许有少量误差的查询场景,使用这些函数对查询性能有大幅提升。比如使用approx_distinct() 函数比Count(distinct x)有大概2.3%的误差
<span style="color:#333333">select approx_distinct(s_id) from score;</span>-
用regexp_like代替多个like语句: Presto查询优化器没有对多个like语句进行优化,使用regexp_like对性能有较大提升
<span style="color:#333333">SELECT
...
FROM
access
WHERE
method LIKE '%GET%' OR
method LIKE '%POST%' OR
method LIKE '%PUT%' OR
method LIKE '%DELETE%'
优化:
SELECT
...
FROM
access
WHERE
regexp_like(method, 'GET|POST|PUT|DELETE')</span>-
使用Join语句时将大表放在左边: Presto中join的默认算法是broadcast join,即将join左边的表分割到多个worker,然后将join右边的表数据整个复制一份发送到每个worker进行计算。如果右边的表数据量太大,则可能会报内存溢出错误。
<span style="color:#333333">[GOOD] SELECT ... FROM large_table l join small_table s on l.id = s.id
[BAD] SELECT ... FROM small_table s join large_table l on l.id = s.id</span>-
使用Rank函数代替row_number函数来获取Top N
-
UNION ALL 代替 UNION :不用去重
-
使用WITH语句: 查询语句非常复杂或者有多层嵌套的子 查询,请试着用WITH语句将子查询分离出来
6. 其他注意事项
1. 字段名引用
-
避免和关键字冲突:MySQL对字段加反引号`;Presto对字段加双引号分割
当然,如果字段名称不是关键字,可以不加这个双引号。
2. 函数
-
对于Timestamp,需要进行比较的时候,需要添加Timestamp关键字,而MySQL中对Timestamp可以直接进行比较。
<span style="color:#333333"><span style="color:#aa5500">/*MySQL的写法*/</span>
<span style="color:#770088">SELECT</span> t <span style="color:#770088">FROM</span> a <span style="color:#770088">WHERE</span> t > <span style="color:#aa1111">'2020-05-01 00:00:00'</span>;
<span style="color:#aa5500">/*Presto的写法*/</span>
<span style="color:#770088">SELECT</span> t <span style="color:#770088">FROM</span> a <span style="color:#770088">WHERE</span> t > <span style="color:#116644">timestamp '2020-05-01 00:00:00'</span>;</span>
3. 不支持INSERT OVERWRITE语法
-
Presto中不支持insert overwrite语法,只能先delete,然后insert into。
4. QUET格式
-
Presto目前支持Parquet格式,支持查询,但不支持insert
五、拓展点、未来计划、行业趋势
-
官网走一遭
-
安装部署
-
connector
-
function
-
sql statement syntax
-
注:以上来自kkb课堂笔记
最后
以上就是健康橘子最近收集整理的关于2020-12-03《Presto分布式SQL查询引擎——kkb笔记复习》Presto分布式SQL查询引擎一、课前准备二、课堂主题三、课堂目标四、知识要点五、拓展点、未来计划、行业趋势注:以上来自kkb课堂笔记的全部内容,更多相关2020-12-03《Presto分布式SQL查询引擎——kkb笔记复习》Presto分布式SQL查询引擎一、课前准备二、课堂主题三、课堂目标四、知识要点五、拓展点、未来计划、行业趋势注内容请搜索靠谱客的其他文章。








发表评论 取消回复