事件起因
七月中旬,我司的系统潜在风险排查工作在如火如荼的进行,其中我发现当前系统的调用源缺少Token信息,难以做到具体的识别和监控,因此需要对其优化。
针对刚提到的两个问题,我只需要实现某个框架基类,然后做一点业务处理即可,根据框架的说明文档,按步骤实现以下内容即可:
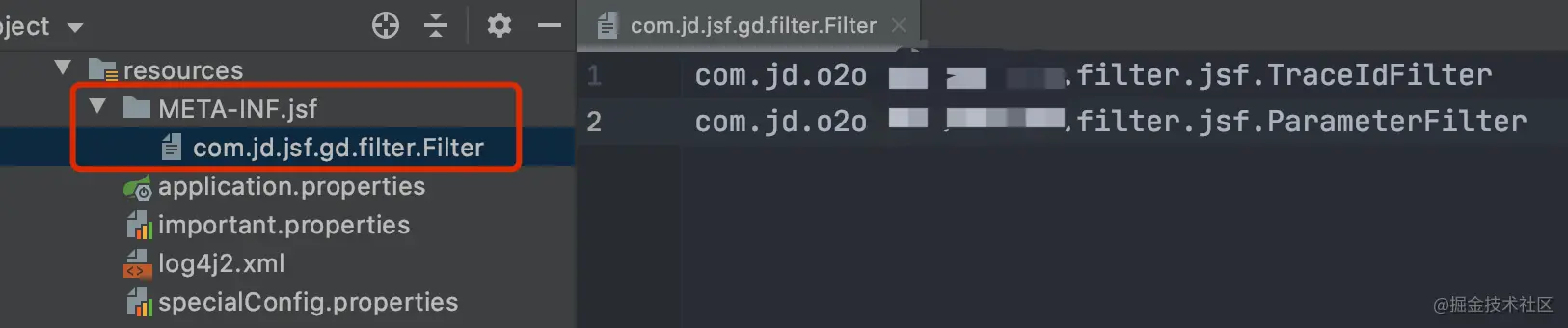
开发、调试一气呵成之后,我对这种实现方式起了好奇之心,非常疑惑它们是如何在框架中实例化并发挥作用的,有兴趣的话就跟我一起一探究竟吧(????)
什么是SPI
最初我甚至都不知道这种技术/方案是Java自身支持的,还以为是框架自身设计的骚操作,后来询问其他同事才知晓这种灵活的提供服务能力的方式被称为SPI,官方一点的解释如下:
SPI:全称为 Service Provider Interface。是Java提供的一套用来被第三方实现或者扩展的接口,多用于框架扩展、插件开发等等。
例如上文中提到的实现参数过滤器就属于框架扩展范畴,简单了解后我们来整一个小Demo吧。
SPI的工作方式
SPI的发现能力是不需要依赖于其他类库,主要有两种实现方式:
- sun.misc.Service Sun公司提供的加载能力
- java.util.ServiceLoader#load JDK自身提供的加载能力
因为方法二是JDK内部代码,包含源码,因此后续都默认使用该方法进行说明
基本使用步骤:
-
定义一个需要对外提供能力的接口
public interface SPIInterface { String handle(); } 复制代码 -
定义实现类,实现指定接口
public class SPIInterfaceImpl implements SPIInterface { @Override public String handle() { return "当前时间为: " + LocalDateTime.now(); } } 复制代码 -
在指定位置配置相关的实现类:resource/META-INF/services
注意 resource为资源文件
# 文件位置(resource/META-INF/services/com.mine.spi.SPIInterface) # 内容(实现类的全类名) com.mine.spi.impl.SPIInterfaceImpl 复制代码 -
使用JDK提供的初始化能力,直接调用即可
public class SpiApp { public static void main(String[] args) { ServiceLoader<SPIInterface> load = ServiceLoader.load(SPIInterface.class); for (SPIInterface ser : load) { System.out.println(ser.handle()); } } } // 响应 // 当前时间为: 2021-08-24T03:30:52.397 复制代码
简单到爆炸,关键还是在于JDK已经帮助我们实现了这一套发现和初始化的步骤,下面咱们来深入分析一下它的基本源码 ????
从方法:java.util.ServiceLoader#load 为入口,将当前接口Class类型及其类加载器传入至Loader变量中:
/**
* service:接口类型
* loader:类加载器
* acc:安全管理器
*/
private ServiceLoader(Class<S> svc, ClassLoader cl) {
service = Objects.requireNonNull(svc, "Service interface cannot be null");
loader = (cl == null) ? ClassLoader.getSystemClassLoader() : cl;
acc = (System.getSecurityManager() != null) ? AccessController.getContext() : null;
reload();
}
复制代码变量传入之后,初始化类:LazyIterator,从名称就可以看出来这是一个懒加载的迭代器,只有真正使用触发时才会进行实例的初始化,核心初始化逻辑在方法:java.util.ServiceLoader.LazyIterator#nextService中。
private S nextService() {
// 省略其他代码...
Class<?> c = null;
try {
c = Class.forName(cn, false, loader);
} catch (ClassNotFoundException x) {
fail(service,
"Provider " + cn + " not found");
}
// 省略其他代码...
}
复制代码因为拿到了接口类型及其全类名,所以通过反射构建出实例对象还是非常容易的,拿到实例化的对象后,就和普通的代码没有什么区别了。
下面我们再看看几个框架实际使用SPI的例子,瞻仰一下前辈们的代码 ????
SPI使用案例分析
Log4j-Api
以Log4j日志框架为例,log4j-api-2.13.3.jar 版本就基于 SPI实现了 PropertySource接口,用以收集当前服务器相关的配置信息,如下图所示:
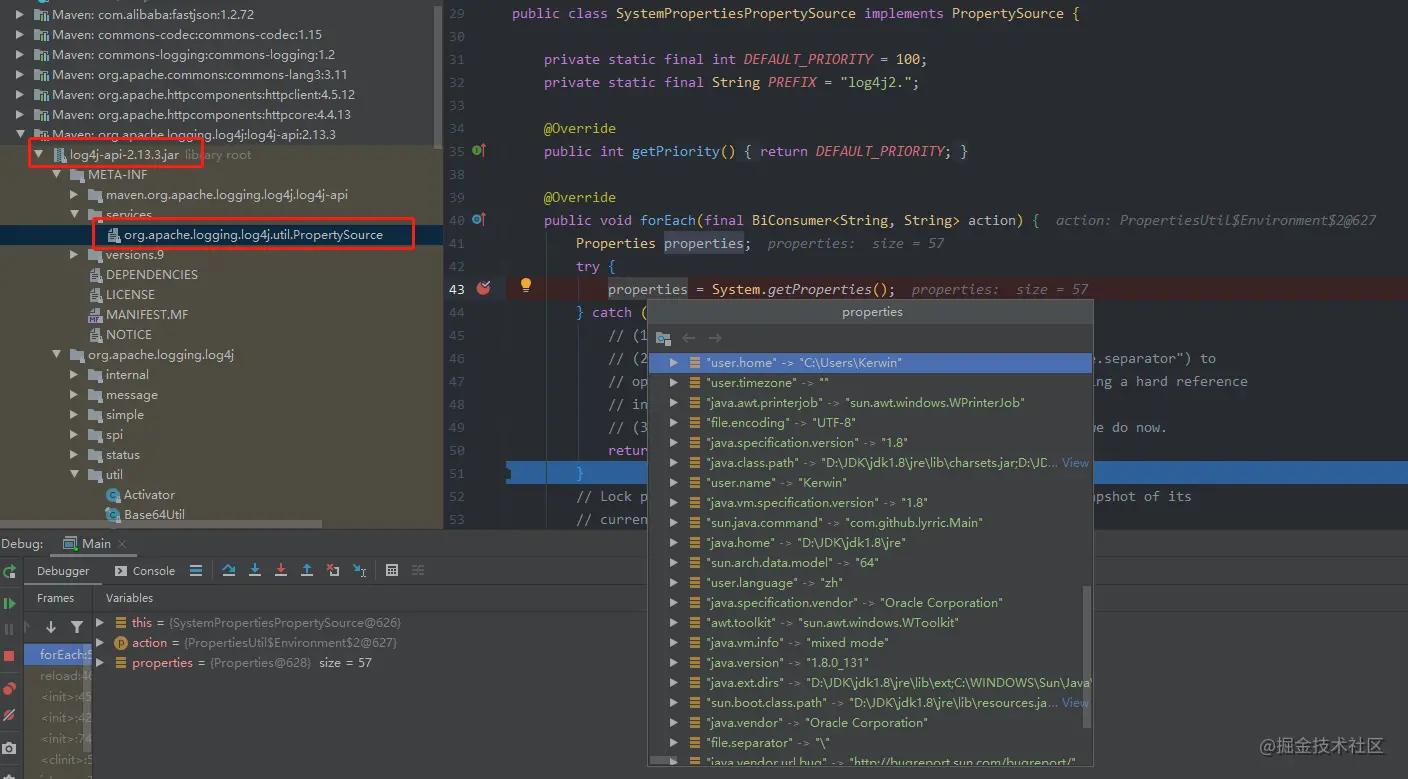
同样的,log4j-core-2.13.3.jar基于 SPI实现了日志门面的绑定,核心代码如下所示:
/**
* Binding for the Log4j API.
*/
public class Log4jProvider extends Provider {
public Log4jProvider() {
super(10, "2.6.0", Log4jContextFactory.class);
}
}
复制代码JDBC驱动
以我们常用的JDBC驱动 mysql-connector-java-5.1.43.jar为例,它同样实现了SPI接口,驱动类分别为:Driver,FabricMySQLDriver,其底层实现是向驱动管理类注册自身,核心代码如下,它帮我们自动做了 Class.forName("com.mysql.jdbc.Driver")这一步加载动作。
public class Driver extends NonRegisteringDriver implements java.sql.Driver {
//
// Register ourselves with the DriverManager
//
static {
try {
java.sql.DriverManager.registerDriver(new Driver());
} catch (SQLException E) {
throw new RuntimeException("Can't register driver!");
}
}
}
复制代码FabricMySQLDriver类则同理,当然了,我们也可以主动破坏这种加载的机制,比如自行实现一个MySQLDriver,来实现数据库连接,核心代码如下:
public class CustomDriver extends NonRegisteringDriver implements Driver {
static {
try {
java.sql.DriverManager.registerDriver(new CustomDriver());
} catch (SQLException ignored) {}
}
public CustomDriver() throws SQLException { }
@Override
public Connection connect(String url, Properties info) throws SQLException {
System.out.println("[Kerwin] 执行数据库连接...");
return super.connect(url, info);
}
@Override
public Logger getParentLogger() throws SQLFeatureNotSupportedException {
return null;
}
}
复制代码然后将 CustomDriver注入到SPI中即可。

需要注意的是 CustomDriver类需要实现继承 NonRegisteringDriver类,否则会被默认的Driver优先注册,完成之后使用上古的JDBC代码调用,即可模拟破坏SPI的情况,如图:
public void customDriver() throws SQLException {
Connection conn = DriverManager.getConnection("jdbc:mysql://127.0.0.1:3306/db_file?characterEncoding=UTF-8&useSSL=false", "root", "");
Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery("SELECT * FROM script_dir LIMIT 1");
while (rs.next()) {
System.out.println(rs.getString(1));
}
}
复制代码可以看到,我们使用自定义驱动类成功获取到数据库连接,替换了原本的Driver驱动类,具体细节需要大家再Debug看看,因为涉及接口类型,拿到连接后Return等等。

控制台输出:
[Kerwin] 执行数据库连接...
复制代码SPI的应用场景
了解完它的基本使用方法和原理之后,SPI的神秘感顿时化为虚有,说到底就是基于约定在指定位置选择性配置接口实现类,由JDK动态初始化及执行的机制。
日常开发要不要使用SPI?
我们从上文中能直接体会到SPI机制的好处,它可以起到策略选择、动态初始化、解耦的作用,那我们在普通项目开发中要不要使用呢?我个人是不推荐使用SPI的方式,主要原因还是我们可以使用更优雅的方式来替代SPI机制,比如:
- 动态初始化、策略选择 =》我们可以使用策略+工厂模式实现策略的动态选择,配合ZK来实现动态初始化(启用/禁用)
- 解耦 =》基于良好的设计,可以很容易的实现解耦
基于上述的方案,可以保证项目代码具备SPI的好处的同时更加易读,降低理解成本。
框架/组件工具开发要不要使用SPI?
答案是毋庸置疑的,现在的诸多框架及工具就是使用SPI来实现的,引入了SPI机制后,服务接口与服务实现就会达成分离的状态,可以实现解耦以及可扩展机制。
例如Sharding-jdbc的加密算法接口,原生仅提供了AES和MD5两种加密方式,需要其他加密方式的项目就可以使用SPI机制将自己需要的加密方式写入框架内,然后根据需要调用即可,无论是使用还是维护都更加方便。
因为Java实现的SPI版本相对比较粗糙和暴力,导致它会把所有接口实现类全部实例化一遍,所以还有框架会对Java的SPI进行封装和优化,比如Dubbo,它将配置文件中的全类名修改为了键值对的方式,以满足按需加载的需要,同时增加了IOC及AOP的特性,自适应扩展等机制。
通过上文的工作方式我们就可以了解到SPI的机制并不神秘,如果个人需要简单封装的话,还是轻而易举的。
学习SPI的思想
SPI机制有一定的必然性,以上文提到的Sharding-jdbc的加密算法为例,只有真正的使用者才知道自己到底需要什么,因此把一部分决定权(实现)交给用户的能力是必须要具备的,不然的话框架也好,工具也罢,为了满足所有的情况,代码势必都会变的非常臃肿。这其中最关键的设计原则即:
依赖倒置原则(要针对抽象层编程,而不要针对具体类编程)
我们在日常开发中同样要思考如何设计接口,如何依赖抽象层进行编程,减少与实现类之间的耦合,同样的,为了实现这一要求,我们必然会去学习设计模式、设计原则之类的知识,去了解各种设计模式的最佳实践,一步步的去优化代码,在此推荐一下我之前的文章:设计模式总篇:从为什么需要原则到实际落地(附知识图谱)。
总结
截止到这里,我们明白了什么是SPI及其工作的原理,熟悉了它的典型案例,也了解了它的应用场景、设计理念等等,下面是一些针对性的建议:
- SPI机制是框架/工具级项目必备的能力之一,立志于高级工程师的小伙伴一定要吃透它的设计理念和实现原理
- SPI的核心思想:把一部分决定权(实现)交给用户,即依赖倒置
- 了解SPI的优势和特点后,在单体项目中我们完全可以使用别的方案达到更好的效果,切忌为了使用而去用它
- 未来在开发或使用某些中间件/工具时,可以多加留意它是否提供了相关的SPI接口,可能会起到事半功倍的效果。
最后
以上就是闪闪鞋子最近收集整理的关于「一探究竟」Java SPI机制的全部内容,更多相关「一探究竟」Java内容请搜索靠谱客的其他文章。








发表评论 取消回复