我是靠谱客的博主 俏皮牛排,这篇文章主要介绍一篇文章搞懂SQL在Oracle和MySQL中是如何执行的Oracle中的SQL是如何执行的MySQL中的SQL是如何执行的,现在分享给大家,希望可以做个参考。
快速到达看这里-->
- Oracle中的SQL是如何执行的
- Oracle中应该多使用硬解析还是软解析呢?
- MySQL中的SQL是如何执行的
- MySQL与Oracle执行的区别
Oracle中的SQL是如何执行的
首先来看一看SQL在Oracle中的执行过程
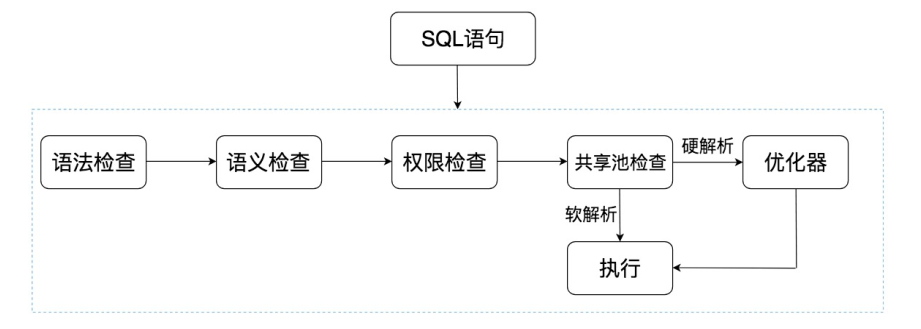
SQL的执行经历了以下的步骤:
- 语法检查:检查SQL的拼写是否正确,如果不正确会报错
- 语义检查:检查SQL中的访问对象是否存在,比如我们查询的时候,查询列
'username',但是不小心写成了'usernames',列名写错了,系统就会提示错误 - 权限检查:检查当前用户是否拥有对该数据的权限
- 共享池检查:共享池(Shared Pool) 是一块内存池,主要作用是缓存SQL语句和该语句的执行计划。Oracle通过检查共享池是否存在SQL语句的执行计划来判断使用软解析还是硬解析
- 如果存在SQL语句的执行计划,就直接拿来执行,进入执行器环节,这就是软解析
- 如果不存在SQL语句的执行计划,生成执行计划,进入优化器步骤,这就是硬解析
- 优化器:用来进行硬解析,决定应该怎么做,如创建解析树,生成执行计划等
- 执行器:当有了解析树和执行计划后,就知道SQL怎么执行了,就可以执行SQL
Oracle中应该多使用硬解析还是软解析呢?
在Oracle中,可以使用绑定变量的方式实现软解析。
绑定变量:
- 优点:提升了软解析的可能性,减少硬解析,较少Oracle的工作量
- 缺点:参数不同导致执行效率不同,优化比较难做,可能会导致生成的执行计划不够优化
所以,是否需要绑定变量还需要视情况而定
举个栗子:
我们需要使用以下查询语句
SQL> select * from player where player_id = 10001;
如果使用绑定变量就是
SQL> select * from player where player_id = :player_id;
两个查询在第一次一次查询时效率是一致的,但是如果查了10001之后,我们还要继续查10002等等的值,如果不使用绑定变量,每次都需要创建新的查询解析,如果使用了绑定变量,在共享池中就存在这类查询的执行计划,可以直接调用。
总结:
- 当查询较灵活,重复查询不多时不使用绑定变量进行查询(尽量多使用硬解析)
- 当查询较单一,重复查询较多时使用绑定变量进行查询(尽量多使用软解析)
MySQL中的SQL是如何执行的
首先我们来了解下MySQL的架构,MySQL差用的是C/S架构,服务器端程序使用的是mysqld,执行流程如图:
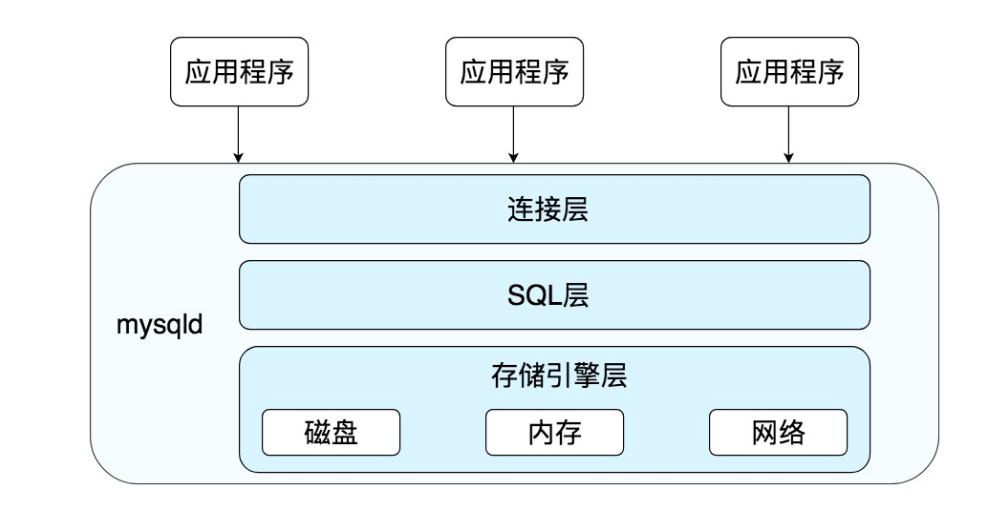
MySQL由三成组成:
- 连接层:客户端与服务器端建立连接,客户端发送SQL到服务器端
- SQL层:对SQL语句进行查询处理
- 存储引擎层:与数据库打交道,真正的负责数据的存储和读取
SQL层的结构:
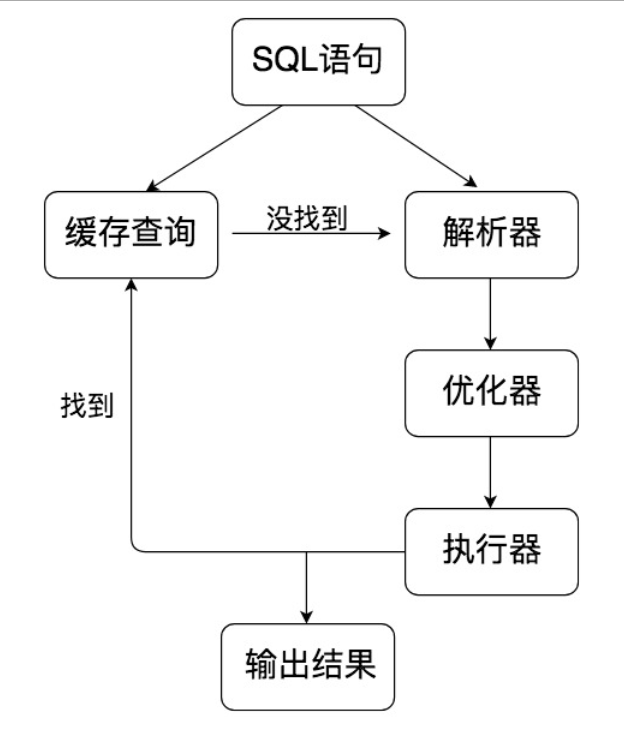
SQL层与数据库文件使用哪种存储引擎无关,是一种通用的处理。执行流程如下:
- 查询缓存:如果查询缓存发现这句SQL语句,就会直接将结果返回给客户端,如果没有,就进入到解析器环节(MySQL8.0之后就抛弃了查询缓存这个功能了)
- 解析器:对SQL语句进行语法分析,语义分析
- 优化器:在优化器中确定SQL语句的执行路径,如:是根据全表检索还是根据索引进行检索
- 执行器:在执行前需要判断该用户是否具备权限。如果具备权限就执行SQL返回结果,(在MySQL8.0之前如果设置了查询缓存,这是会将查询结果进行缓存)
MySQL与Oracle执行的区别
MySQL的存储引擎采用插件的形式,每个存储引擎都面对一种特定的数据库应用环境,每一张表都可以设置自己的存储引擎。常见的存储引擎:
- InnoDB 存储引擎:它是 MySQL 5.5 版本之后默认的存储引擎,最大的特点是支持事务、行级锁定、外键约束等。
- MyISAM 存储引擎:在 MySQL 5.5 版本之前是默认的存储引擎,不支持事务,也不支持外键,最大的特点是速度快,占用资源少。
- Memory 存储引擎:使用系统内存作为存储介质,以便得到更快的响应速度。不过如果 mysqld 进程崩溃,则会导致所有的数据丢失,因此我们只有当数据是临时的情况下才使用Memory 存储引擎
- NDB 存储引擎:也叫做 NDB Cluster 存储引擎,主要用于 MySQL Cluster 分布式集群环境,类似于 Oracle 的RAC 集群
- Archive 存储引擎:它有很好的压缩机制,用于文件归档,在请求写入时会进行压缩,所以也经常用来做仓库
本文参考了:《SQL必知必会》
更多Java面试复习笔记和总结可访问我的面试复习专栏《Java面试复习笔记》,或者访问我另一篇博客《Java面试核心知识点汇总》查看目录和直达链接
最后
以上就是俏皮牛排最近收集整理的关于一篇文章搞懂SQL在Oracle和MySQL中是如何执行的Oracle中的SQL是如何执行的MySQL中的SQL是如何执行的的全部内容,更多相关一篇文章搞懂SQL在Oracle和MySQL中是如何执行内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。


![论文阅读 [TPAMI-2022] AlignSeg: Feature-Aligned Segmentation Networks论文阅读 [TPAMI-2022] AlignSeg: Feature-Aligned Segmentation Networks](https://www.shuijiaxian.com/files_image/reation/bcimg6.png)





发表评论 取消回复