Semantic Flow for Fast and Accurate Scene Parsing
https://arxiv.org/abs/2002.10120arxiv.org一 文章出发点
文章的出发点可以从下面一段话一窥究竟。
众所周知,语义分割为像素级分类任务,有的像素需要高阶的语义信息才能较好的识别,而有的像素比较依赖空间细节。所以现有实时深度语义分割基本都会融合多种不同分辨率的特征进行语义分割。那么怎么融合才能又快又好了,作者借鉴光流的思想,提出利用语义流来对齐不同层次的特征MAP。

二 怎么做
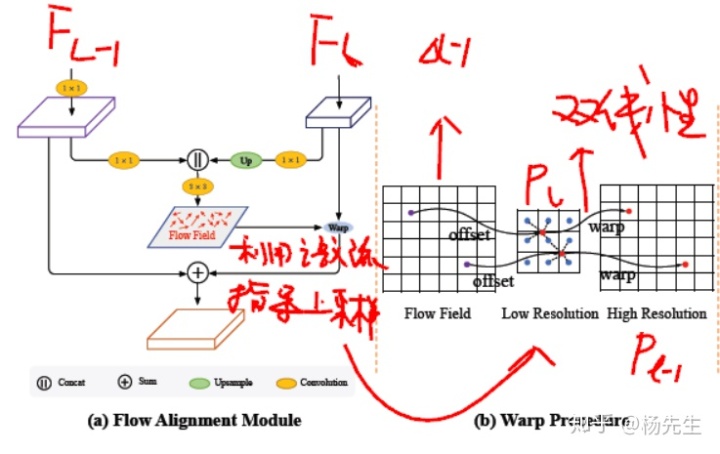
语义流怎么来
从上图看出,语义流就是两个不同层次特征简单拼接后经一个卷积层获取,典型的黑盒子模式。
有了语义流,实际上某种程度上就有了高分辨率特征降采样到低分辨率语义特征时的采样索引,所以作者根据这个索引 △L-1,可以将高分辨率特征每个(整数坐标)像素点(PL-1)对应到低分辨率的一个(小数坐标)像素点(PL)。
然后根据这个小数坐标,找到4个最近的整数邻居进行双线性插值即可将低分辨率特征与高分辨率特征进行语义对齐。

最后
以上就是丰富宝贝最近收集整理的关于特征级融合_ECCV2020(oral) 实时语义分割之利用语义流对齐不同层次特征的全部内容,更多相关特征级融合_ECCV2020(oral)内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。



![论文阅读 [TPAMI-2022] AlignSeg: Feature-Aligned Segmentation Networks论文阅读 [TPAMI-2022] AlignSeg: Feature-Aligned Segmentation Networks](https://www.shuijiaxian.com/files_image/reation/bcimg6.png)




发表评论 取消回复