
量化的背景
得益于海量数据、超强算力和最新技术,深度学习在视觉、自然语言处理等领域都取得了巨大成功。然而,深度学习模型的网络结构越来越复杂、参数越来越多、计算量越来越大,给模型部署应用带来了不小挑战,尤其对于存储、计算资源都有限的手机等边缘设备。于是,工业界和学术界提出了众多深度学习模型的压缩与加速技术,而模型量化就是最常见的技术之一。

飞桨(PaddlePaddle)是国内首个全面开源开放、技术领先、功能完备的产业级深度学习平台,提供了强大、全流程的模型量化方案,如图1所示。

图 1 飞桨模型量化方案
通过飞桨压缩库PaddleSlim对模型进行量化操作,对模型进行“瘦身”和“提速”,产出量化模型;然后通过飞桨轻量化推理引擎Paddle Lite将量化后的模型部署到移动端、嵌入式等终端,提供全流程的量化方案。除此之外,PaddleSlim还提供了剪裁、蒸馏、超参搜索等一系列模型压缩策略;Paddle Lite提供多硬件、多平台的端侧部署。两者联合使用,帮助大家轻易解决移动和边缘设备上模型部署的各种难题。
接下来,我们首先介绍模型量化原理,然后说明飞桨模型量化解决方案和特性,最后给出一个详细的模型量化示例。
量化技术简介
模型量化是将浮点数替换成整数,并进行存储和计算的方法。举例来讲,模型量化可通过将32比特浮点数转换成8比特整数,大大减少模型存储空间(最高可达4倍);同时将浮点数运算替换成整数运算,能够加快模型的推理速度并降低计算内存。
首先考虑简单情况,将浮点数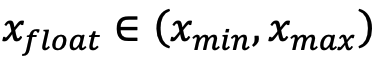 量化为整数
量化为整数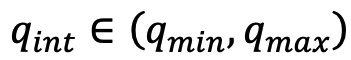 量化的计算公式为
量化的计算公式为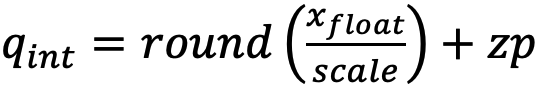 。这里需要提前确定量化信息scale、zp。
。这里需要提前确定量化信息scale、zp。
通常情况下,有以下三种方式来基于浮点数和整数的映射关系进行量化信息的计算,如图2所示。
非饱和方式:将浮点数正负绝对值的最大值对应映射到整数的最大最小值。
饱和方式:先计算浮点数的阈值,然后将浮点数的正负阈值对应映射到整数的最大最小值。
仿射方式:将浮点数的最大最小值对应映射到整数的最大最小值。
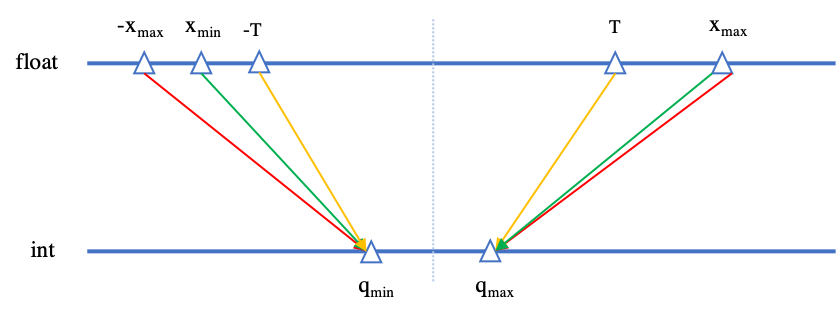
图2 红色代表非饱和方式,黄色代表饱和方式,绿色代表仿射方式
模型量化是对原始模型中的权重和激活进行量化,量化方法分为以下三种。
动态离线量化:此方式不需要样本数据。采用非饱和方式进行权重的量化。
静态离线量化:此方式只需使用少量的样本数据进行模型的前向计算,对激活进行数值采样。使用饱和方式量化权重,非饱和方式量化激活。
量化训练:此方式需要使用大量有标签样本数据。通过非饱和方式进行权重和激活的量化,并在训练过程中更新权重。
三种量化方式的收益对比如下图所示。

图3 量化方法总结对比
全流程量化方案
1. PaddleSlim 产出量化模型
PaddleSlim是基于飞桨框架、功能完备、完全开源的深度学习模型压缩库,集成了量化、剪裁、蒸馏、模型结构搜索、模型硬件搜索等常用压缩方法。
在飞桨模型量化方案中,PaddleSlim负责产出量化模型。PaddleSlim提供了强大、易用的模型量化功能,支持所有主流量化方法,包括动态离线量化、静态离线量化和量化训练方法。而且,产出统一格式的量化模型,在ARM CPU、Intel CPU、Nvidia GPU等预测端都可以进行部署。使用PaddleSlim中的量化功能,大家只需要关注quant_aware、quant_convert等API接口。
2. Paddle Lite 部署量化模型
Paddle Lite是一个高性能、轻量级、多硬件支持的深度学习预测引擎,而且兼容PaddlePaddle和其他训练框架产出的模型。
在飞桨模型量化方案中,Paddle Lite负责在边缘设备上部署量化模型。Paddle Lite强大的量化功能,主要表现在以下几方面:使用汇编实现了底层的Int8 Kernel,具有高效的量化计算能力;全面支持PaddleSlim产出的量化模型;支持对全量化和部分量化模型进行优化加速;支持部署量化模型到ARM CPU、MTK、RK、寒武纪、比特大陆等硬件平台。
Paddle Lite部署量化模型的方法和普通模型相同,首先使用OPT工具转换模型,然后加载模型进行预测推理。相比原始模型,量化模型通常在存储空间、推理速度和计算内存等方面都有明显优势。所以,任何模型都有必要使用飞桨的模型量化方案。
三大亮点
1. 支持主流模型量化方法
飞桨模型量化方案支持所有主流量化方法,包括动态离线量化方法、静态离线量化方法和量化训练方法。给定预测模型,飞桨模型量化可以适用于所有情况,图4说明了如何选择模型量化方法。需要注意,静态离线量化方法只需要少量无标签的样本数据,而量化训练方法需要大量有标签的样本数据。一般而言,建议大家首先使用简单、省时的静态离线量化方法。如果静态离线量化模型精度无法达到要求,再使用量化训练方法。
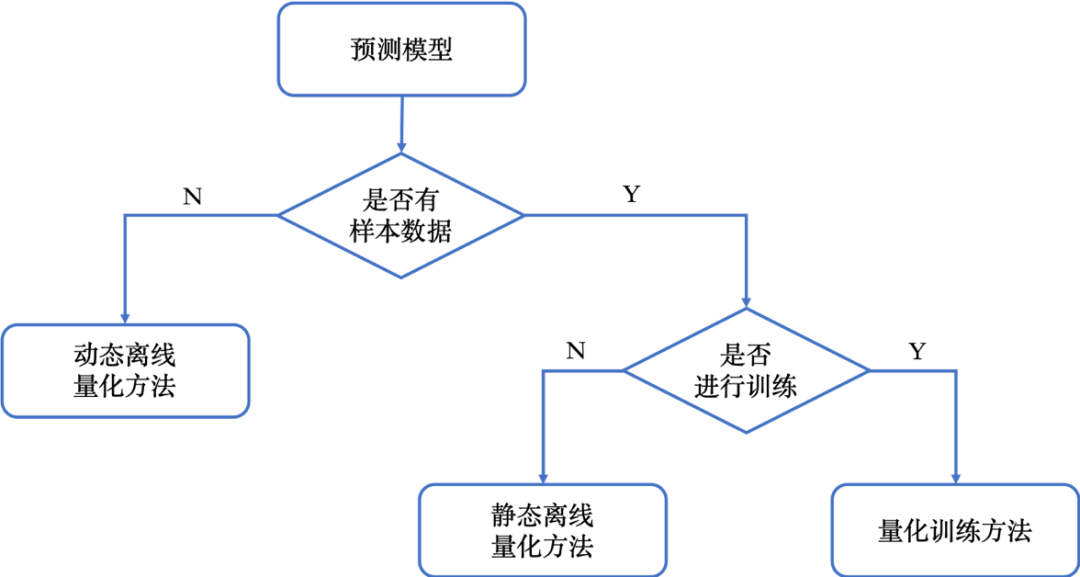
图 4 选择飞桨模型量化方法
2. 模型量化全流程打通
模型量化主要包括两个步骤,第一是将原始模型转换成量化模型,第二是加载量化模型进行预测推理。
在飞桨模型量化方案中,PaddleSlim可以使用多种量化方法对不同模型进行量化,Paddle Lite全面支持所有量化模型在移动端预测推理,具体包括ARM CPU、MTK、RK、寒武纪、比特大陆等硬件平台。虽然不同硬件平台存在精度差异,但是Paddle Lite可以保证绝大多数量化模型的精度无损。
相比NCNN、MNN和Mace等预测推理库,飞桨模型量化具有功能强、全流程打通的优势。而且,飞桨模型量化不依赖第三方框架产出量化模型,具有更好的稳定性和易用性。
3. 模型量化收益显著
目前,飞桨模型量化方案已经在大量模型上进行验证,可以应用于各种业务场景中,同时取得显著收益。
百度人脸识别部署在嵌入式系统上,0.3s完成人脸检测、对齐、活体、识别全流程计算,错误率降低22%。AI电网智能巡检项目,在低端芯片上实现推理速度加快1.8倍,计算内存减少3倍。

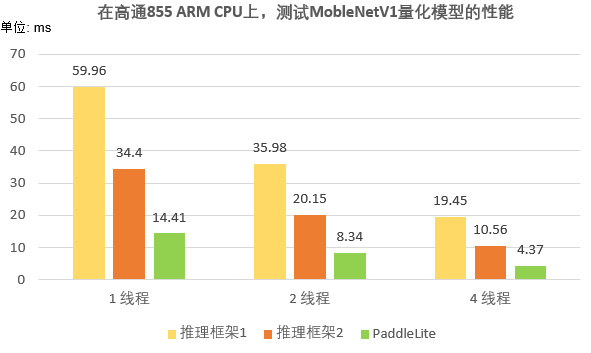
图 5 在高通855 ARM CPU,Paddle Lite测试量化模型的结果
将常见的分类、分割模型作为Benchmark,我们测试了飞桨模型量化方案的数据(如图5)。对比分析,量化后模型精度有一点点下降,但是模型存储空间减少73.0%-74.7%,推理速度加快170%-216%。同时,我们在三个推理框架上测试了MobileNetV1量化模型的性能(如图6),可以发现Paddle Lite的表现远超另外两个推理框架。
由此可见,飞桨模型量化方案可以在计算和存储方面带来显著收益,帮助深度学习模型在更多业务中应用落地。
模型量化实战
接下来,我们使用百度AI Studio平台和MobileNetV1模型,详细介绍模型量化产出和部署的整个流程。强烈推荐阅读相关说明,并按照说明执行所有代码,具体请参考:
https://aistudio.baidu.com/aistudio/projectdetail/526625
1. 准备环境
AI Studio中初始配置安装了PaddlePaddle 1.8.0,需要手动安装PaddleSlim 1.1.1和Paddle Lite 2.6.1。如果本地执行示例,需要参考飞桨官方文档安装PaddlePaddle,CPU或者GPU版本皆可。
pip install paddleslim==1.1.1 -i https://pypi.org/simple
pip install paddlelite==2.6.1 -i https://mirror.baidu.com/pypi/simple
2. 准备数据和模型
使用AI Studio中准备好的校准数据集,解压到./data/quant_100imgs文件夹,其中其中val文件夹保存100张图片,val_list.txt保存图片名字和标签。
tar zxf /home/aistudio/data/data38675/quant_100imgs.tgz -C ./data/
下载原始FP32预测模型,解压到./data/mobilenetv1_fp32文件夹。
wget -c -P ./data/ https://paddle-inference-dist.cdn.bcebos.com/PaddleLiteDemo/mobilenetv1_fp32.tgz
!tar zxf ./data/mobilenetv1_fp32.tgz -C data/
3. PaddleSlim产出量化模型
基于PaddleSlim,我们使用静态离线量化方法产出MobileNetV1量化模型。
首先,导入特定的Python库,定义变量。
# 导入
import os
import shutil
from work import reader
import paddle.fluid as fluid
from paddleslim.quant import quant_post
# 定义变量
model_fp32_path = "./data/mobilenetv1_fp32/"
model_int8_path = "./data/mobilenetv1_int8/"
data_path = "./data/quant_100imgs/"
use_gpu = False # 如果是GPU环境,可以设置use_gpu=True,加快执行时间
place = fluid.CUDAPlace(0) if use_gpu else fluid.CPUPlace()
executor = fluid.Executor(place)
然后,静态离线量化方法使用异步数据读取的方式读取校准数据,需要根据模型的输入,配置相应的数据读取器。更多数据生成器配置方法,请参考“飞桨官网-进阶教程-异步数据读取”文档。此处,我们使用导入的reader创建数据读取器。
sample_generator = reader.val(data_path)
最后,调用PaddleSlim的quant_post接口执行模型量化,得到量化模型。
quant_post(
executor=executor,
model_dir=model_fp32_path,
quantize_model_path=model_int8_path,
sample_generator=sample_generator,
batch_size=10,
batch_nums=10,
save_model_filename=None,
save_params_filename=None)
4. Paddle Lite部署量化模型
基于Paddle Lite,我们首先转换量化模型,然后对比模型量化前后的存储空间、推理速度和精度,最后将量化模型部署到ARM CPU端。
1 ) 转换量化模型
基于Paddle Lite的Python库,可以在命令行使用OPT工具对量化模型进行转化。
paddle_lite_opt
--optimize_out_type=naive_buffer
--valid_targets=arm
--model_dir=./data/mobilenetv1_int8/
--optimize_out=./data/mobilenetv1_opt
2 ) 对比模型存储空间
执行如下命令查看模型量化前后的模型存储空间(如图6),可以发现量化后模型存储空间减小了74.7%。
du -sh ./data/mobilenetv1_fp32 ./data/mobilenetv1_opt.nb

图6 模型量化前后存储空间
3 ) 对比模型推理速度
我们复用Paddle Lite的Benchmark方法,在骁龙855手机上测试模型量化前后的推理速度。注意,在AI Studio中无法直接连接骁龙855手机,如果需要亲自测试,请参考下面步骤准备测试文件、模型,然后本地连接手机执行。
首先,准备所需的模型、可执行文件和测试脚本,保存在lite_test.tgz文件。
# 创建文件夹
lite_test_path = "./lite_test"
if os.path.exists(lite_test_path):
shutil.rmtree(lite_test_path)
os.mkdir(lite_test_path)
if os.path.exists("./lite_test.tgz"):
os.remove("./lite_test.tgz")
# 下载可执行文件
!wget -c -P ./lite_test https://paddle-inference-dist.bj.bcebos.com/PaddleLite/benchmark_2.6/benchmark_bin_v8
# 整理模型和脚本
!cp ./work/run.sh ./lite_test
!cp -r ./data/mobilenetv1_fp32 ./lite_test
!cp -r ./data/mobilenetv1_opt.nb ./lite_test
!tar zcf ./lite_test.tgz ./lite_test
然后,将lite_test.tgz文件下载、解压到在本地;确保骁龙855手机打开USB调试、连接本地电脑;执行run.sh测试脚本得到计算时间数据(如图7)。对比结果,可以发现量化模型平均加速216%。

图7 模型量化前后推理速度
4 ) 对比模型精度
基于Paddle Lite和ImageNet2012全量测试集,我们也可以在手机端测试量化前后模型的精度。但是,考虑到操作细节较多,这里不展开叙述,直接给出模型精度的测试数据(如图8)。
可以发现,MobileNetV1模型量化后,TOP1和TOP5精度分别只下降0.39%和0.11%。更加重要的是,如果使用量化训练方法产出量化模型,模型精度损失会更小。

图 8 模型量化前后精度
5 ) 部署量化模型
目前,Paddle Lite可以将量化模型部署到ARM CPU、MTK、RK、寒武纪、比特大陆等硬件平台。如果考虑将量化模型部署到安卓或者IOS手机上,可以参考Paddle Lite官方文档中的量化、安卓Demo和IOS Demo的使用方法,将原始预测模型替换成量化模型,执行可以得到结果(如图9)。

图 9 量化模型执行结果
本项目代码和文件均放在百度一站式在线开发平台AI Studio上,链接如下:
https://aistudio.baidu.com/aistudio/projectdetail/526625
如在使用过程中有问题,可加入飞桨官方推理部署QQ群:696965088
如果您想详细了解更多飞桨的相关内容,请参阅以下文档。
官网地址:
https://www.paddlepaddle.org.cn
PaddleSlim:
官方文档:
https://paddleslim.readthedocs.io/zh_CN/latest/
Github:
https://github.com/PaddlePaddle/PaddleSlim
Paddle Lite
官方文档:
https://paddle-lite.readthedocs.io/zh/latest/
Github:
https://github.com/PaddlePaddle/Paddle-Lite
飞桨开源框架项目地址:
GitHub:
https://github.com/PaddlePaddle/Paddle
Gitee:
https://gitee.com/paddlepaddle/Paddle
END

最后
以上就是酷酷短靴最近收集整理的关于一个方案搞定从模型量化到端侧部署全流程本项目代码和文件均放在百度一站式在线开发平台AI Studio上,链接如下:https://aistudio.baidu.com/aistudio/projectdetail/526625的全部内容,更多相关一个方案搞定从模型量化到端侧部署全流程本项目代码和文件均放在百度一站式在线开发平台AI内容请搜索靠谱客的其他文章。








发表评论 取消回复