Presto是什么?
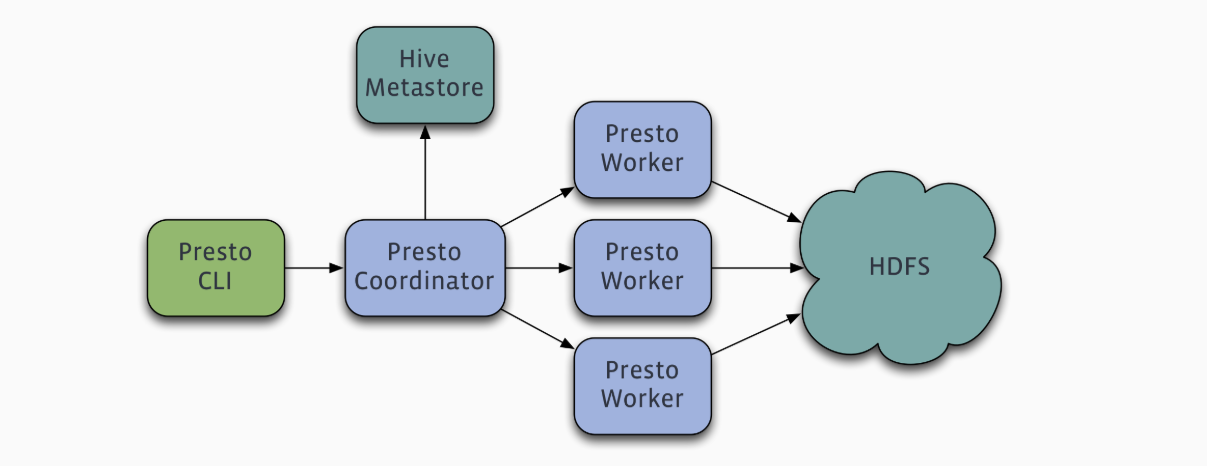
Presto通过使用分布式查询,可以快速高效的完成海量数据的查询。如果你需要处理TB或者PB级别的数据,那么你可能更希望借助于Hadoop和HDFS来完成这些数据的处理。作为Hive和Pig(Hive和Pig都是通过MapReduce的管道流来完成HDFS数据的查询)的替代者,Presto不仅可以访问HDFS,也可以操作不同的数据源,包括:RDBMS和其他的数据源(例如:Cassandra)。Presto被设计为数据仓库和数据分析产品:数据分析、大规模数据聚集和生成报表。这些工作经常通常被认为是线上分析处理操作
安装部署:
(需要JDK8以上)
1、下载presto的tar包
链接: https://repo1.maven.org/maven2/com/facebook/presto/presto-server/0.219/presto-server-0.219.tar.gz
2、解压:


data 用于存储日志、本地元数据等的数据目录。 建议在安装目录的外面创建一个数据目录。这样方便Presto进行升级。
3、生成配置
在安装目录中创建一个目录 etc , 加入以下配置:
节点属性:特定于每个节点的环境配置 --- etc/node.properties
JVM Config:Java虚拟机的命令行选项 --- etc/jvm.config
配置属性:Presto服务器的配置 --- etc/config.properties
日志级别配置文件 --- etc/log.properties
目录属性:连接器(数据源)的配置
节点属性
包含特定于每个节点的配置:
| 属性 | 解释 |
|---|---|
| node.environment | 环境的名称。群集中的所有Presto节点必须具有相同的环境名称。 |
| node.id | 此Presto安装的唯一标识符。对于每个节点,这必须是唯一的。在重新启动或升级Presto时,此标识符应保持一致。如果在一台计算机上运行多个Presto安装(即同一台计算机上的多个节点),则每个安装必须具有唯一标识符。 |
| node.data-dir | 数据目录的位置(文件系统路径)。Presto将在此处存储日志和其他数据。 |
先 touch 一个 /etc/node.properties
然后复制配置进去:
node.environment=production
node.id=presto1
node.data-dir=/opt/presto/data
JVM Config
包含用于启动Java虚拟机的命令行选项列表。该文件的格式是一个选项列表,每行一个。shell不会解释这些选项,因此不应引用包含空格或其他特殊字符的选项。
touch etc/jvm.config
加入以下配置:
-server
-Xmx16G
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:+ExitOnOutOfMemoryError
配置属性:
包含Presto服务器的配置。每个Presto服务器都可以充当协调器和工作器,但是专用一台机器来执行协调工作可以在更大的集群上提供最佳性能。
现在自己测试,不考虑性能。为方便起见,只用单节点,即当coordinator 也当worker。
将以下配置复制加入新建的config.properties
(8080端口容易起冲突,修改为了8081)
coordinator=true
node-scheduler.include-coordinator=true
http-server.http.port=8081
query.max-memory=5GB
query.max-memory-per-node=1GB
query.max-total-memory-per-node=2GB
discovery-server.enabled=true
discovery.uri=http://192.168.79.101:8081
(修改为自己的ip或主机名和对应端口)
属性解释如下:
coordinator:允许此Presto实例充当协调器(接受来自客户端的查询并管理查询执行)。
node-scheduler.include-coordinator:允许在协调器上安排工作。对于较大的集群,协调器上的处理工作可能会影响查询性能,因为计算机的资源不可用于调度,管理和监视查询执行的关键任务。
http-server.http.port:指定HTTP服务器的端口。Presto使用HTTP进行内部和外部的所有通信。
query.max-memory:查询可能使用的最大分布式内存量。
query.max-memory-per-node:查询可在任何一台计算机上使用的最大用户内存量。
query.max-total-memory-per-node:查询可在任何一台计算机上使用的最大用户和系统内存量,其中系统内存是读取器,写入程序和网络缓冲区等执行期间使用的内存。
discovery-server.enabled:Presto使用Discovery服务查找群集中的所有节点。每个Presto实例都会在启动时使用Discovery服务注册自己。为了简化部署并避免运行其他服务,Presto协调器可以运行Discovery服务的嵌入式版本。它与Presto共享HTTP服务器,因此使用相同的端口。
discovery.uri:Discovery服务器的URI。因为我们在Presto协调器中启用了Discovery的嵌入式版本,所以它应该是Presto协调器的URI。替换example.net:8080以匹配Presto协调器的主机和端口。此URI不得以斜杠结尾。
如果想按分布式搭建,请参考官网,修改配置:
附上链接: https://prestodb.github.io/docs/current/installation/deployment.html
日志级别配置文件
允许为命名的记录器层次结构设置最小日志级别。每个记录器都有一个名称,通常是使用记录器的类的完全限定名称。记录器具有基于名称中的点的层次结构(如Java包)。例如,请考虑以下日志级别文件:
在etc/log.properties中加入以下配置
com.facebook.presto = INFO
这将 com.facebook.presto.server和com.facebook.presto.hive设置为最低级别。默认的最低级别是INFO (因此上面的示例实际上并没有改变任何东西)。共有四个级别:DEBUG,INFO,WARN和ERROR。
目录属性
通过在目录中创建目录属性文件来注册etc/catalog目录。
touch etc/catalog/hive.properties
加入配置
connector.name=hive-hadoop2
hive.metastore.uri=thrift://example.net:9083 (替换为自己的hive metastore的ip和端口)
hive.config.resources=/etc/hadoop/conf/core-site.xml,/etc/hadoop/conf/hdfs-site.xml (可选,选择hdfs-site.xml和core-site.xml)
还有很多其他的连接器可选,请参考官网
https://prestodb.github.io/docs/current/connector.html
开始运行
安装目录包含启动器脚本bin/launcher。可以通过运行以下命令将Presto作为守护程序启动:
bin / launcher start
启动后,您可以在var/log以下位置找到日志文件:
| launcher.log | 此日志由启动程序创建,并连接到服务器的stdout和stderr流。它将包含初始化服务器日志记录时发生的一些日志消息以及JVM生成的任何错误或诊断信息。 |
| server.log | 这是Presto使用的主日志文件。如果服务器在初始化期间出现故障,它通常会包含相关信息。它会自动旋转和压缩。 |
| http-request.log | 这是HTTP请求日志,其中包含服务器收到的每个HTTP请求。它会自动旋转和压缩。 |
命令行界面
Presto CLI提供了一个基于终端的交互式shell,用于运行查询。CLI是一个 自动执行的 JAR文件,这意味着它的行为类似于普通的UNIX可执行文件。
下载 presto-cli-0.219-executable.jar,将其重命名为presto
增加执行权限,并绑定调度器端口

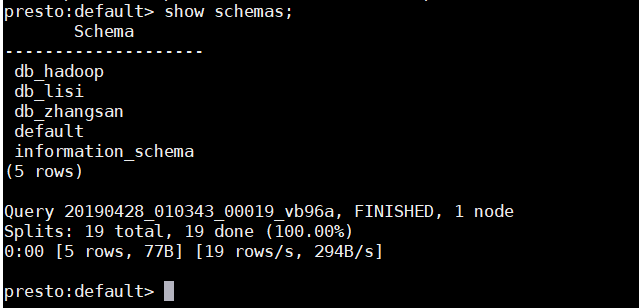
有一点点不同,hivesql中的database,在这里叫schema。
所以查看数据库时,就得用show schemas;
最后
以上就是缥缈指甲油最近收集整理的关于presto的安装部署的全部内容,更多相关presto内容请搜索靠谱客的其他文章。








发表评论 取消回复