Presto官网: Presto | Distributed SQL Query Engine for Big Data (prestodb.io)
Presto官方安装文档:Deploying Presto — Presto 0.252 Documentation (prestodb.io)
安装Presto:
1、下载presto-server-0.252.tar.gz,上传到Linux 服务器并重命名为presto
mv presto-server-0.252.tar.gz presto
2、进入到presto目录,创建etc目录,创建配置文件命令如下:
cd presto
mkdir etc
mkdir etc/catalog
touch etc/node.properties
touch etc/jvm.config
touch etc/config.properties
touch etc/log.properties
3、添加属性
config.properties: presto服务配置
node.properties:每个节点特定配置
jvm.properties:java虚拟机的命令行选项
log.properties:输出的日志级别
catalog目录:每个连着者配置
a、node.properties添加以下属性,当然也可以根据官网的提示进行修改:
node.environment=production #环境名字,Presto集群中的结点的环境名字都必须是一样的。
node.id=abcd-presto #唯一标识,每个结点的标识都必须是为一的。就算重启或升级Presto都必须还保持原来的标识。
node.data-dir=/var/presto/data #数据目录,Presto用它来保存log和其他数据
b、jvm.config添加以下属性:
-server
-Xmx16G #分配的总内存,此数必须大于每个节点分配的内存总数
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:+ExitOnOutOfMemoryError
c、config.properties添加以下属性(这个是单机版的属性,如果是集群请参考官网):
Coordinator节点:
coordinator=true #是否运行该实例为coordinator(接受client的查询和管理查询执行)
node-scheduler.include-coordinator=true #是否也作为work。对于大型集群来说,在coordinator里做worker的工作会影响查询性能。
http-server.http.port=8080 #指定HTTP端口。Presto使用HTTP来与外部和内部进行交流。
query.max-memory=5GB #查询能用到的最大总内存
query.max-memory-per-node=1GB #查询能用到的最大单结点内存
query.max-total-memory-per-node=2GB
discovery-server.enabled=true #Presto使用Discovery服务去找到集群中的所有结点。每个Presto实例在启动时都会在Discovery服务里注册。这样可以简化部署, 不需要额外的服务,Presto的coordinator内置一个Discovery服务。也是使用HTTP端口。
discovery.uri=http://example.net:8080 #Discovery服务的URI。将example.net:8080替换为coordinator的host和端口。这个URI不能以斜杠结尾,这个错误需特别注意,不然会报404错误。
worker节点:
coordinator=false
http-server.http.port=8080
query.max-memory=10GB
query.max-memory-per-node=3GB
query.max-total-memory-per-node=3GB
discovery.uri=http://example.net:8080 #Coordinator节点的域名或者IP
d、log.properties添加以下属性
com.facebook.presto = INFO #日志级别有四种,DEBUG, INFO, WARN and ERROR
e、catalog/hive.properties添加以下属性
connector.name=hive-hadoop2
hive.metastore.uri=thrift://cdh001.bigdata.com:9083
hive.config.resources=/etc/hadoop/conf/core-site.xml,/etc/hadoop/conf/hdfs-site.xml
4、下载 presto-cli-0.252-executable.jar 客户端jar包,上传到Linux服务器,并将jar包变为可执行环境,命令如下:
chmod +x presto-cli-0.252-executable.jar
可修改名为presto,放置bin下:
mv presto-cli-0.252-executable.jar presto
mv presto presto/bin/
启动Presto:
1、进入到presto/bin目录下,执行以下命令:
bin/launcher start
2、客户端登录服务器,执行
./presto --server localhost:8080 --catalog hive --schema default
# catalog 是catalog目录的连接器文件名,而非配置名称,很重要。
# schema 相当于数据库,但并非是真正的数据库
# 8080 是config.properties中配置的端口,自己根据需要改
服务器连接Presto:
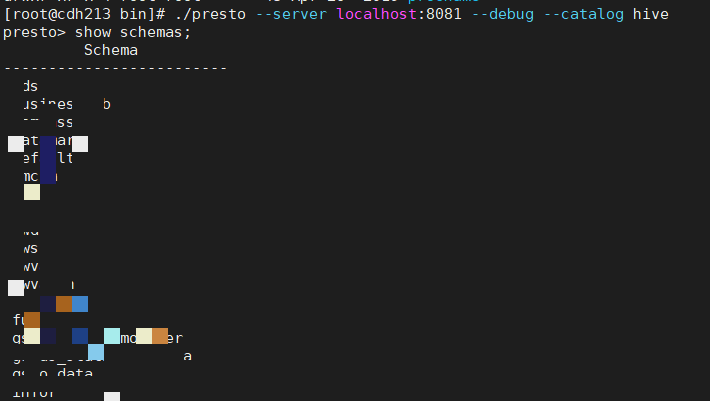
DBeaver连接Presto:
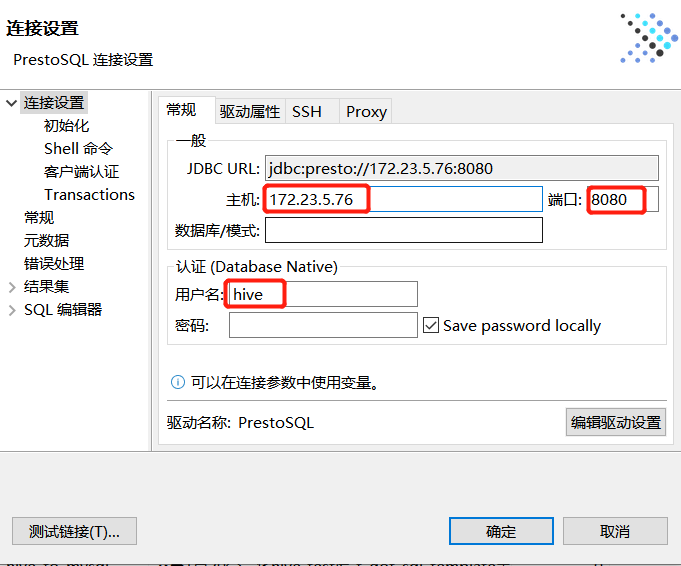
最后
以上就是怕孤独鱼最近收集整理的关于Presto安装的全部内容,更多相关Presto安装内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复