文章内容
- 基础准备
- Linux环境安装和准备
- VNC server安装
- 安装Gnome桌面
- 远程桌面窗口启动
- 开发环境配置
- Windows环境安装和准备
- 安装VNC viewer
- 开发调试配置修改
- 总结
基础准备
一台windows系统的工作机,一台linux系统的服务器。
Linux环境安装和准备
我们使用VNCserver来进行远程可视化。首先需要安装VNCServer。
VNC server安装
我这里是Centos7系统。安装步骤如下:
- 运行安装server
yum install tigervnc-server -y - 编辑用户
vim /lib/systemd/system/vncserver@.service
修改user 为myuser
ExecStart=/usr/bin/vncserver_wrapper myuser %i - 修改密码
执行 vncpasswd 修改密码 - 启动服务
service vncserver start
安装Gnome桌面
yum groupinstall GNOME Desktop Environment -y
运行上述命令安装Gnome
远程桌面窗口启动
运行下述命令启动一个窗口服务
vncserver :1 -geometry 1920x1080
这里窗口编号为1,屏幕分辨率为1920x1080,默认服务端口为5901,如果要启动多个,修改命令中的窗口编号和分辨率。
开发环境配置
基础的开发环境需要IDE(我使用的是idea),git, maven,JDK等基础配置,相信作为一个程序员这些安装都是轻车熟路,不需要过多赘述。在安装好上述工具的情况下,使用git拉下来源码放到指定的开发目录。至此Linux下的准备工作暂告一段落。
Windows环境安装和准备
安装VNC viewer
回到我们的工作机,我们下载一个VNCviewer,安装完成后,输入VNC server服务所在的IP:host,如下图,输入我们预置的密码后即可连接到服务器。
 连上以后就是这么个样子:
连上以后就是这么个样子:
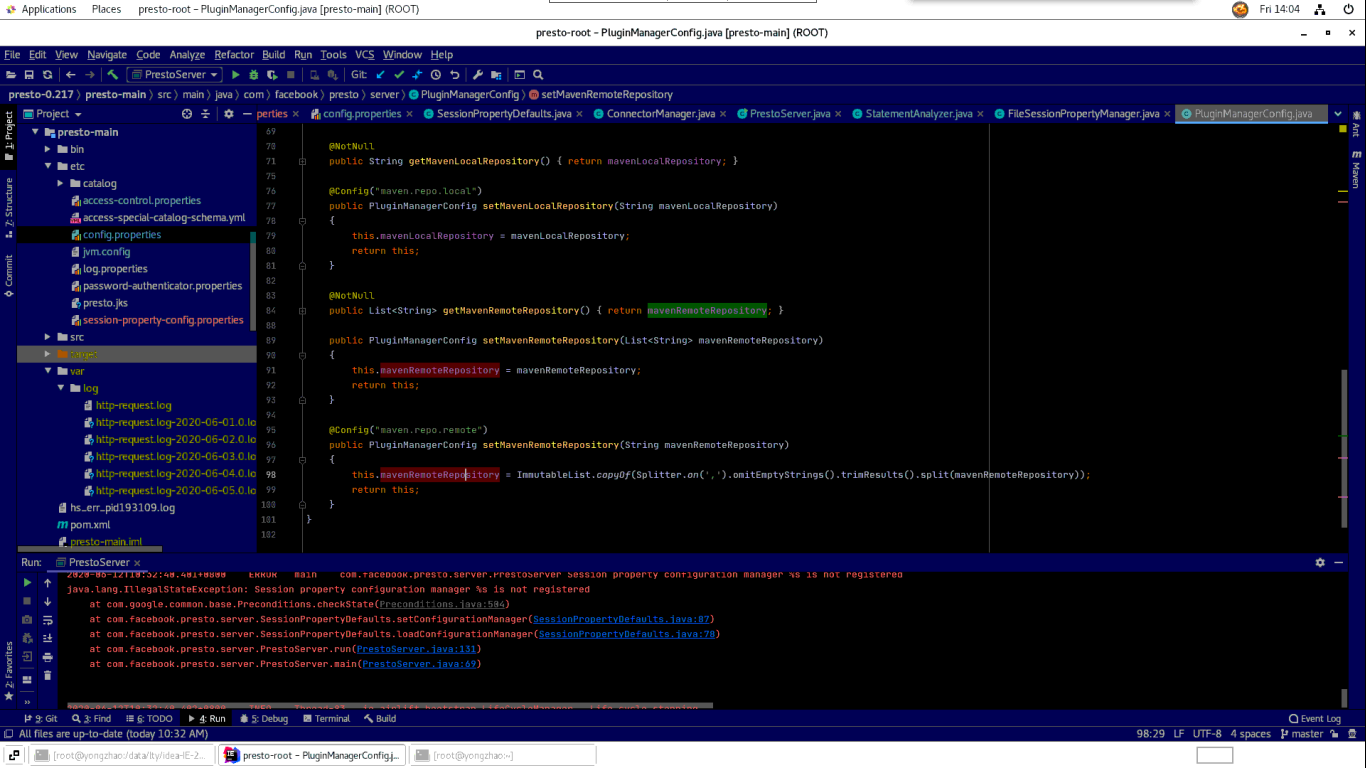 怎么样,是不是瞬间觉得就可以开始板砖了。很遗憾,第一运行还需要一些其他的配置。
怎么样,是不是瞬间觉得就可以开始板砖了。很遗憾,第一运行还需要一些其他的配置。
开发调试配置修改
我们打开Idea,导入源码后,并不能直接开始debug,首先我们使用mvn对整个源码编译一遍,先解决编译过程中的问题。然后,还需要对源码做一部分配置修改,此处我以hive数据源为例大概记录一下修改过程。
- 修改presto-main下数据源的配置
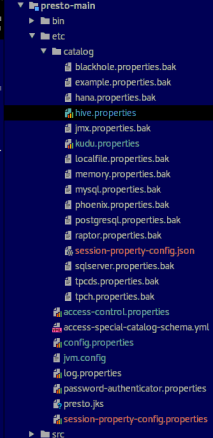 我这里只需要调试hive和kudu数据源,因此我对其他catalog的配置都改名字了,让server启动时不去加载这些配置,加快启动。
我这里只需要调试hive和kudu数据源,因此我对其他catalog的配置都改名字了,让server启动时不去加载这些配置,加快启动。
connector.name=hive-hadoop2
#hive.metastore.uri=thrift://172.17.171.106:9083
hive.metastore.uri=thrift://172.17.202.181:9083
hive.metastore.username=hive
hive.config.resources=/data/lty/core-site.xml,/data/lty/hdfs-site.xml,/data/lty/hive-site.xml
#hive.readonly-mode=false
#hive.bucket-execution=true
#hive.ignore-table-bucketing=true
#hive.optimize-mismatched-bucket-count=true
#hive.recursive-directories=true
hive.parquet.fail-on-corrupted-statistics=false
hive.max-split-size=128MB
hive.dfs.connect.timeout=30s
#hive.multi-file-bucketing.enabled=true
#hive.empty-bucketed-partitions.enabled=true
#hive.collect-column-statistics-on-write=true
#hive.table-statistics-enabled=true
这里需要修改下metastore的uri,并且将连接集群hadoop 的 core-site.xml,hdfs-site.xml,hive-site.xml这几个配置文件拷到本地并配置进来。这里的connector.name 在dubug时只能为hive-hadoop2,否则server 启动时会报找不到connector的异常。
- 修改plugin的配置目录
这里我们需要修改下PluginManagerConfig.java中plugin的目录,如果此前你们有对plugin进行修改,记得更新jar,如果没有修改那么直接去官方下载presto-server的完整tar包,解压后把plugin目录拷过去就行了。
// private File installedPluginsDir = new File("plugin");
private File installedPluginsDir = new File("/data/leapCode4.1/presto-plugin");
private List<String> plugins;
- 找到PrestoServer.java, 配置如下的启动参数,这里可参考github官方的配置,并根据具体情况适当调整:
VM options:
-ea -XX:+UseG1GC -XX:G1HeapRegionSize=32M -XX:+UseGCOverheadLimit -XX:+ExplicitGCInvokesConcurrent -Xmx1G -Dconfig=etc/config.properties -Dlog.levels-file=etc/log.properties -DHADOOP_USER_NAME=hive
WorkDrectory:
$MODULE_DIR$
好了,至此我们就可以运行PrestoServer了。
然后我们到presto-cli的target目录下:
java -jar presto-cli-0.217-executable.jar --server localhost:18080 --catalog hive --user hive
就可以连接到server,开始愉快的调试过程。
总结
一开始我准备在windows下搭建开发环境,浪费了很多时间还是不行,而且编译时也有很多代码的style check,presto确实不适合在windows下直接进行开发调试。于是找了别的team的研发童鞋问了一下,自己捯饬安装了一个presto的开发调试环境。由于公司配的工作机都是windows操作系统,所以这个问题搞得很复杂。不过最终得到解决。
最后
以上就是欣喜小天鹅最近收集整理的关于从零开始搭建一个windows下的presto开发调试环境基础准备Linux环境安装和准备Windows环境安装和准备开发调试配置修改总结的全部内容,更多相关从零开始搭建一个windows下内容请搜索靠谱客的其他文章。








发表评论 取消回复