好久不来博客园了,前几天更新个人状态时,也把“技术博客”四个字改成了“荒废已久的博客”。
好久不总结自己的工作和学习了,怎么说也过不去,就来这写一篇浅显的文章,没什么新鲜的内容,算是一篇经验的汇总把。
1. 关于排行榜
各大网站一般来说都少不了排行榜这个东西,一者是提供给商业合作方的数据排行榜,另一者是提供给用户的榜单。
例如豆瓣的新书榜:

2. 打造一个最简单的排行榜
我们先用豆瓣的新书榜为例,看看我们如何来一步步完善我们的榜单。
其实最初的版本很简单,既然是新书,那么我们只需要先得到最近出版的读书,例如:
select * from book where create_datetime > xxxx limit 0,10;
这样其实我们的排行榜就是可用的了。
3. 排行榜的演化
这个榜单我们应该很快就可以发现一些问题:
A. 有很多书其实质量很低,包括《21天精通ASP.NET》这样的书都能够上榜。
B. 一些书得到的关注很少,那么其实它就不值得推出来。
综上所述,我们应该在排行榜中增加两个元素:分数和收藏人数。这个时候解决方案仍然很简单:
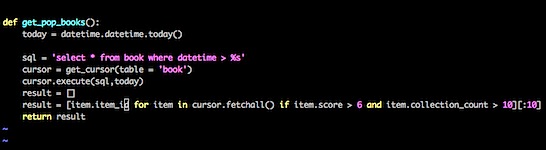
我们其实只是加了两层过滤而已。
但是我们仍然发现了很多问题,对于一本刚刚出版的书来说,很少有人关注,一本书的“绽放期”应该在他出版的两三个月左右,那么这个时候我们就不能这样暴力地利用时间来排序了,此外我们依然需要书条目的Rank问题,现在我们的Rank完全是依赖于时间。
4. 半衰期的引入
我们来重新设计一下整个排行榜的算法,首先,我们整理一下思路,既然是新书榜,无疑我们需要要把时间的概念放大化,但是我们却不能让时间占据过大的因素,而只应该让他成为各种因素的一部分,分配给其较大的权重。
另外一点,我们并非认为昨天和今天出版的书有什么差别,而是涉及到一个逐渐衰减的过程。那么我们第一个想到的应该是高中物理一个基本的概念:半衰期。让我们来复习一下下半衰期的公式:
m = M * (1/2) ^ (t/T)
我们来解释下该公式的含义:M 为初始值,m为反应后的值,t为反应的时间,T为半衰期。
我们把该公式作用于出版时间上,以天作为单位,以一周作为半衰期,从而得到这样的一条函数曲线:
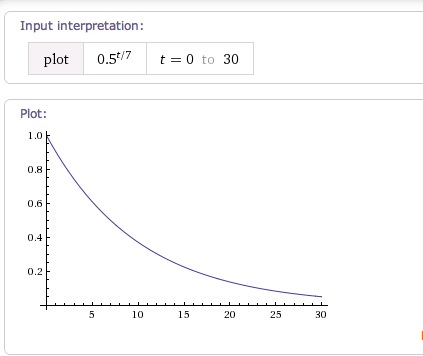
接下来我们考虑分数的因素,其实有两种方案可选择,第一是把分数的因素和之前得到的分数相乘,第二是采用指数的方式。可是由于之前的时间标准<1,函数是一个递减的曲线,所以如果我们需要让分数的评价正作用于之前的函数曲线,我们则需要将分数取反。由于之前我们过滤掉了3分以下的图书,所以我们将分数的参数也归一。(这里我采用第二种,全凭拍脑袋的喜好)从而会这样定义我们的算法:
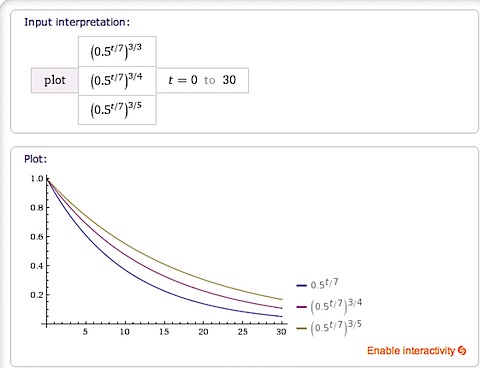
最后一个因素是收藏人数的因素,我们只是归一然后简单相乘即可。
这样我们便出来了一个相对完善排行榜。
5. 排行榜面临的主要问题
其实排行榜更多的是业务问题,而不是算法问题,当我们面对着一个排行榜需求时,我们需要的是先来整理,这个排行榜,我们需要综合哪些因素,这些因素在整个排行榜的Rank中究竟占据多大的比重。然后,我们只需要一个简单的乘法,或者对数即可解决大多数的问题。
那么对于大多数网站的排行榜来说,无外乎这样几个因素,条目的质量,条目的点击率,条目的收藏率等等。而条目的排行榜又往往出现在网站的首页,例如百度听:
如果我们不做任何的优化,则会出现排行榜面临的最大的问题:马太效应。
6. 马太效应
什么是马太效应,我们可以先来看下网上的解释:
马太效应(Matthew Effect),指强者愈强,弱者愈弱的现象,广泛应用于社会心里学,教育,金融等领域。
那么换到我们的排行榜上也就是,越放到排行榜上,他的收听就越多,收听越多,他就越在排行榜上,这样的一个循环。
对于解决马太效应,工程界提出了很多算法,最著名的包括Reddit,Hacker News的Ranking算法,以及我之前提出过的半衰期算法。
我们接下来来逐个介绍一下,并且比较他们的优缺点。
7. Reddit算法
我们先来看下Reddit算法的公式:
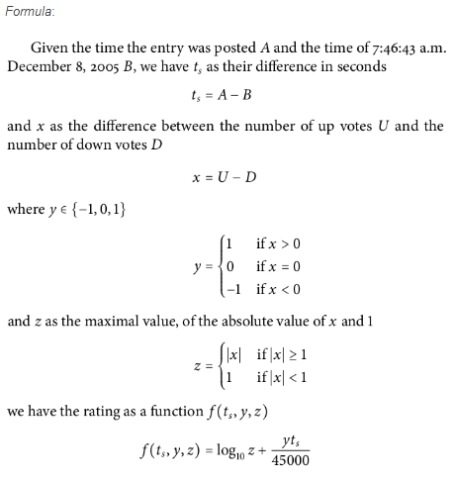
其实Reddit的原理很简单,用发表时间减去固定时间来表示某帖子的新鲜程度,x则表示某帖子的受欢迎程序,然后讲这个参数取对数则是因为该参数的受热度影响较大,产生的值会和另外的时间结果不在同一个数量级上。
而至于10和45000,则属于一个trial-and-error,是算法工程师最头疼的地方,因为该参数并说不出太多的理论道理,只能根据人眼的结果来微调。
8. Hacker New的Ranking算法
这个算法就更为简单:
(p – 1) / (t + 2)^1.5
p来代表这个帖子被推荐的次数,-1则是去掉作者自己的推荐,然后除以时间的一个指数。其中的2和1.5也是一个trial-and-error。
9. 以上算法的优劣
首先是Hacker News的算法,我们从公式即可看出,这个算法的设计是比较简陋的,时间占据了很大的因素,即便是推荐较多的文章,也会被很快的沉没:
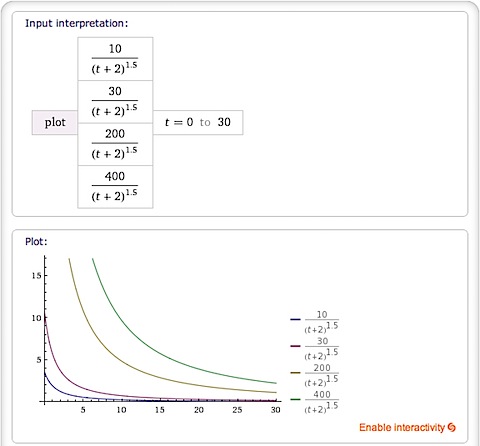
相对来说:Reddit的算法设计较为巧妙,但是Reddit的局限性是对负反馈的要求也比较高,在之前的一个项目中,我尝试过使用Reddit的算法,但是发现如果没有了负反馈,其实消减的效果也比较差。
最后是半衰期的算法,半衰期的算法是我最为推崇的算法,他不依赖于负反馈,而且它的职责很单一,他很专一地来解决时间衰减的问题,然后我们则可以把其他的因素来用单独的方式来计算。最重要的一点是,他的参数是可解释的,Half-life的值,我们是可以根据业务逻辑来解释,比如我们认为一部电影的热门期就应该是一个星期,那么我们则可以把半衰期设置为7,7天后,这个电影的分值则会发生一个较大程度的衰减。这一点是之前的两个算法所无法比拟的。
作为算法工程师, trial-and-error是需要极力避免的,也就是说我们可以从学术界中去得到算法的框架,但是我们要竭力来保持参数的可解释性。
10. 综述
排行榜是一个重业务而轻算法的需求,而且是一个几乎所有网站都会通用的需求,这个需求说简单也简单,说复杂更复杂。
例如应用汇:http://www.appchina.com/soft_rank.html 这种千年不变的排行榜,就完全不需要动脑子。
也有例如近日很火爆的AppStore,也包括豆瓣电影等很多Spammer来刷排名的现象,这就不仅仅需要考虑到马太效应,也包括Anti-spammer的领域。
如果我们把推荐系统这个领域给分成个性化推荐和非个性化推荐,那么排行榜一定是非个性化推荐中最重要的一部分了。
最后
以上就是听话世界最近收集整理的关于关于排行榜的算法经验谈的全部内容,更多相关关于排行榜内容请搜索靠谱客的其他文章。








发表评论 取消回复