引入
在计算机的上古时代,程序是这样写出来的。借助一种叫做打孔器的物理设备,然后再纸上或者卡片上打洞。这样,要写的程序、要处理的数据,就变成了一条条纸带或者一张张卡片,之后再交给当时的计算机去处理。

这种方法类似于现在考试用的答题卡。然后再特定的位置上打洞或者不打洞,来替代0和1。
那为什么要使用打卡机而不是用C这样的高级语言来写呢? 原因很简单。因为计算机或者说CPU本身,并没有能力理解这些高级语言。即使到了现在,当前的计算机也只能处理所谓的“机器码”,也就是一连串的“0”和“1”这样的数据。
那么,我们每天用高级语言的纯虚,最终是怎么变成一串串的“0”和“1”的?这一串串的“0”和“1”又是怎么在CPU中处理的?
在软硬件接口中,CPU帮我们做了什么事?
CPU(Central Processing Unit),也叫做中央处理器。相当于计算机的大脑。
- 从硬件的角度来看,CPU就是一个超大规模的集成电路,通过电路实现了加法、乘法以及各种各样的处理逻辑
- 从软件的角度来看,CPU就是一个执行各种计算机指令的逻辑机器。这里的计算机指令,就好比一门CPU能够听得懂的语言,我们也可以把它叫做机器语言
不同的CPU能够听懂的语言不太一样。比如,Intel的CPU(个人电脑)和ARM的CPU(手机)能够听懂的语言就不太一样。类似这样两种CPU各自支持的语言,就是两组不同的计算机指令集,英文叫 Instruction Set。这里面的“Set”,其实就是数学上的集合,代表不同的单词、语法。
这也是为什么电脑上的程序不能在手机上运行的原因,因为这两者语言不通。电脑上的程序能够在另一台电脑上运行的原因就是因为两台CPU有着相同的指令集。
一条计算机程序,不可能只有一条指令,而是由成千上万条指令组成的。但是CPU里不能一直放在所有指令,所以计算机程序平时是存储在存储器中的。这种程序指令存储在存储器里面的计算机就叫做存储程序性计算机
从编译到汇编,代码怎么变成机器码?
// test.c
int main()
{
int a = 1;
int b = 2;
a = a + b;
}
如果我们想要这段程序在一个Linux操作系统上跑起来,我们需要把整个程序翻译成一个汇编语言(ASM,Assembly Language)程序,这个过程叫做编译(Compile)成汇编代码。
针对汇编代码,我们可以再用汇编器(Assembler)翻译成机器码(Machine Code)。这些机器码由“0”和“1”组成的机器语言表示。这一条条机器码,就是一条条的计算机指令。这样一串串的16进制,就是我们CPU能够真正认识的计算机指令。
在一个Linux操作系统上,我们可以简单的用gcc和objdump这样的两条指令,把对应的汇编代码和机器码都打印出来
$ gcc -g -c test.c
$ objdump -d -M intel -S test.o
可以看到,左侧有一堆数字,这些就是一条条机器码;右边有一系列的push、mov、add、pop等,这些就是对应的汇编代码。一行C语言代码,有时候值对应一条机器码和汇编代码,有时候则随对应两条机器码和汇编代码。汇编代码和机器码之间是一一对应的
test.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <main>:
int main()
{
0: 55 push rbp
1: 48 89 e5 mov rbp,rsp
int a = 1;
4: c7 45 fc 01 00 00 00 mov DWORD PTR [rbp-0x4],0x1
int b = 2;
b: c7 45 f8 02 00 00 00 mov DWORD PTR [rbp-0x8],0x2
a = a + b;
12: 8b 45 f8 mov eax,DWORD PTR [rbp-0x8]
15: 01 45 fc add DWORD PTR [rbp-0x4],eax
}
18: 5d pop rbp
19: c3 ret
那为什么我们用GCC编译器的时候,不直接把代码编译成机器码,而是要先编译成汇编代码呢?原因很简单,调试方便,人类很难直接阅读机器码的,而我们通过机器码对应的汇编码就可以猜测机器码到底干了写什么。
汇编代码其实就是“给程序员看的机器码”,也正因为这样,机器码和汇编代码是一一对应的。人类很容易记住add、move这些指令,但是 8b 45 f8 这样的指令,由于很难一下子看明白是在干什么,所以会非常难以记忆。
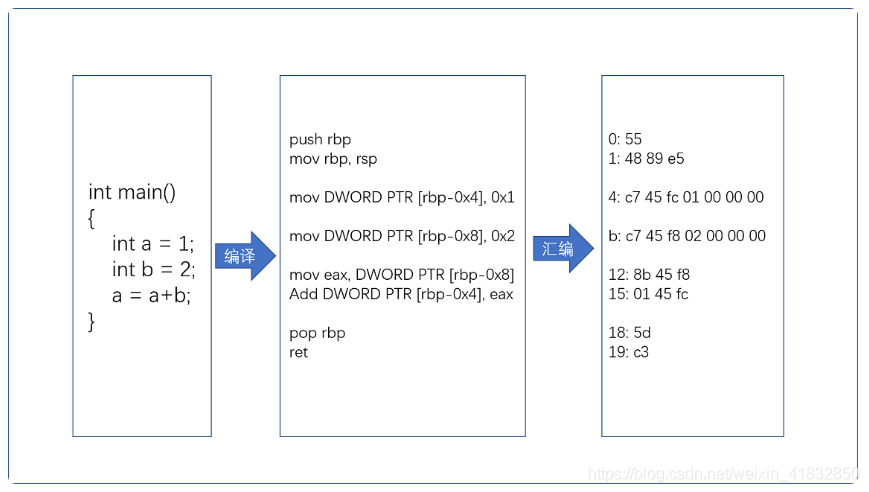
从高级语言到汇编代码,再到机器码,就是一个日常开发程序,最终变成了CPU可以执行的计算机指令的过程
了解了这个过程,下面我们放大局部,来看看这一行行的汇编代码和机器指令,到底是什么意思。
解析指令和机器码
我们日常用的 Intel CPU,有 2000 条左右的 CPU 指令,所以只需要了解常见的指令即可。一般来说,常见指令可以分为五大类:
- 算术类指令:我们的加减乘除,在CPU层面,都会变成一条条算术类指令
- 数据传输类指令:给变量赋值、在内存中读写数据,用的都是数据传输类指令
- 逻辑类指令:逻辑上的与或非,都是这一类指令。
- 条件分支类指令:日常我们写的“if/else”,其实都是条件分支类指令。
- 无条件跳转指令:写一些大一点的程序,我们尝尝需要写一些函数和方法。在调用函数的时候,其实就是发起来一个无条件跳转指令。
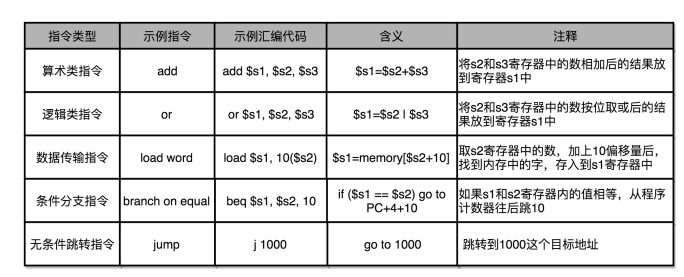
下面我们来看看,汇编器是怎么把对应的汇编指令,翻译成为机器码的。
不同的CPU有不同的指令集,也就对应着不同的汇编语言和不同的机器码。下面以MIPS指令集,来看看机器码是如何生成的。
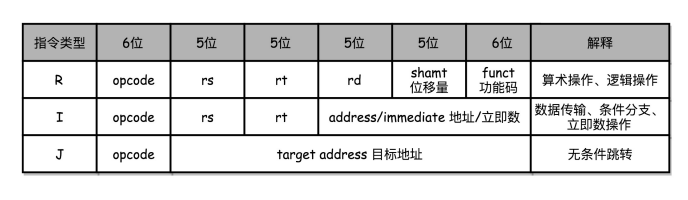
MIPS 的指令是一个 32 位的整数,高 6 位叫操作码(Opcode),也就是代表这条指令具体是一条什么样的指令,剩下的 26 位有三种格式,分别是 R、I 和 J。
- R 指令是一般用来做算术和逻辑操作,里面有读取和写入数据的寄存器的地址。如果是逻辑位移操作,后面还有位移操作的位移量,而最后的功能码,则是在前面的操作码不够的时候,扩展操作码表示对应的具体指令的。
- I 指令,则通常是用在数据传输、条件分支,以及在运算的时候使用的并非变量还是常数的时候。这个时候,没有了位移量和操作码,也没有了第三个寄存器,而是把这三部分直接合并成了一个地址值或者一个常数。
- J 指令就是一个跳转指令,高 6 位之外的 26 位都是一个跳转后的地址。
以一个简单的加法算术指令 add s1, $s2, 为例(为了方便,我们下面都用十进制来表示对应的代码):
add $t0,$s2,$s1
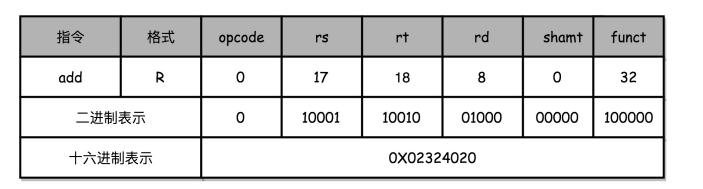
- 对应的 MIPS 指令里 opcode 是 0,rs 代表第一个寄存器 s1 的地址是 17,rt 代表第二个寄存器 s2 的地址是 18,rd 代表目标的临时寄存器 t0 的地址,是 8。因为不是位移操作,所以位移量是 0。把这些数字拼在一起,就变成了一个 MIPS 的加法指令。
- 为了读起来方便,我们一般把对应的二进制数,用16进制表示出来。在这里,也就是0X02324020。这个数字也就是这条指令对应的机器码。
回到开头我们说的打孔带。如果我们用打孔代表 1,没有打孔代表 0,用 4 行 8 列代表一条指令来打一个穿孔纸带,那么这条命令大概就长这样:
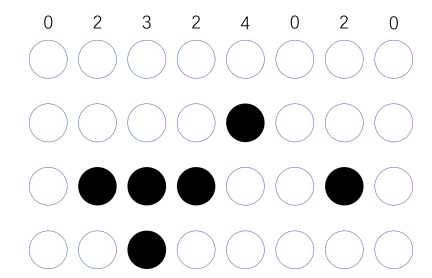
总结
打孔卡,其实就是一种存储程序型计算机。
- 只是着整个程序的机器码,不是通过计算机编译出来的,而是由程序员,由人脑“编译”成一张张卡片的。对应的程序,也不是存储在设备里,而是存储成一张打好孔的卡片。
- 但是整个程序运行的逻辑和其他CPU的机器码没有什么区别,也是处理一串“0”和“1”组成的机器码而已。
上面,我们看到了一个 C 语言程序,是怎么被编译成为汇编语言,乃至通过汇编器再翻译成机器码的。
- 除了C这样的编译器的语言之外,不管是python这样的解释型语言,还是Java这样使用虚拟机的语言,其实最终都是由不同形式的程序,把我们写好的代码,转换成CPU能够理解的机器码来执行的
- 只是解释型语言是通过解释器在程序运行的时候逐句翻译,而Java这样使用虚拟机的语言,则是由虚拟机对编译出来的中间代码进行解释,或者即时编译称为机器码来最终执行
最后
以上就是酷酷钻石最近收集整理的关于计算机组成原理:纸带编程与计算机指令引入在软硬件接口中,CPU帮我们做了什么事?从编译到汇编,代码怎么变成机器码?解析指令和机器码总结的全部内容,更多相关计算机组成原理:纸带编程与计算机指令引入在软硬件接口中内容请搜索靠谱客的其他文章。








发表评论 取消回复