第五次作业——软件设计
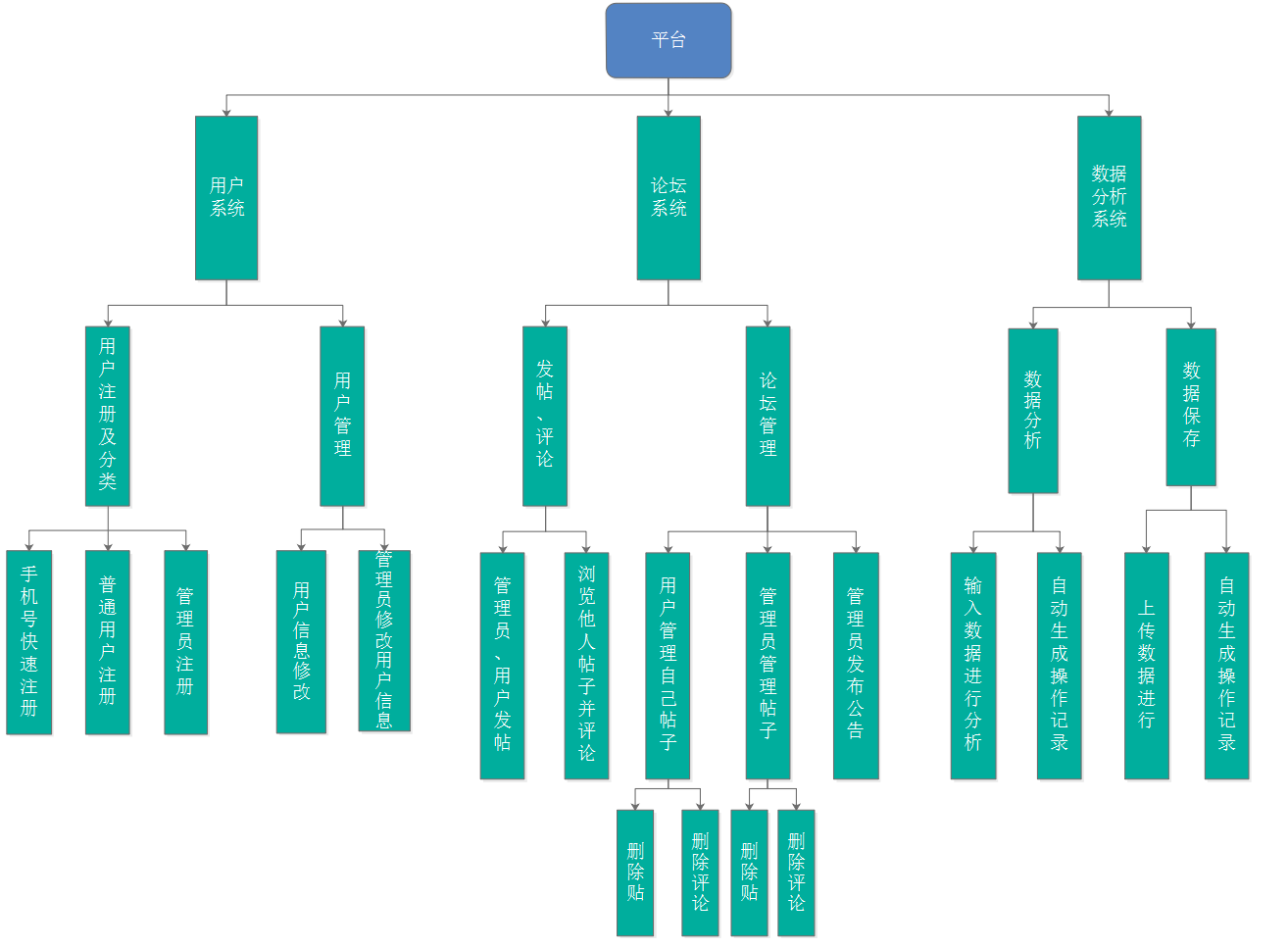
在开始软件设计之前,首先确定软件设计中的各个模块需要考虑的任务,绘制概要图如下:
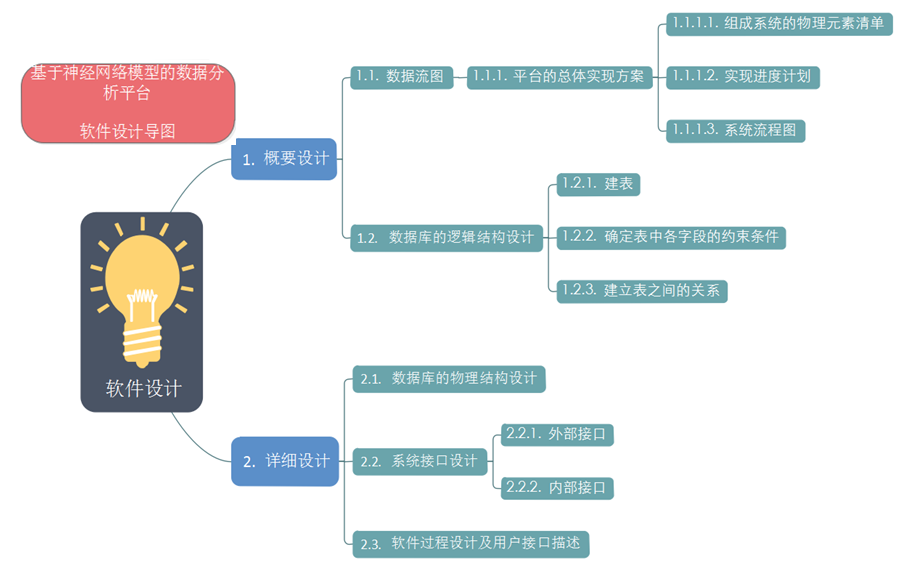
下面根据上述各个模块,逐层进行软件设计:
一、概要设计
首先,概要设计的目的是确定软件的结构以及各组成成分(子系统或模块)之间的相互关系,这样,意味着需要确定我们平台的总体实现方案,这个实现方案由于需从软件各模块进行考虑,因此我们在设计过程中选择由数据流图入手,各组分逐一分析。
除此之外,在概要设计部分,我们要大致确定平台所使用数据库的表、约束以及表之间的联系,这个设计决定了之后系统各模块能够达到的耦合、内聚程度。
1.1 数据流图
由在需求分析中所确定的针对不同用户的产品功能性的需求分析,绘制平台数据流图如下:
①平台顶层数据流图
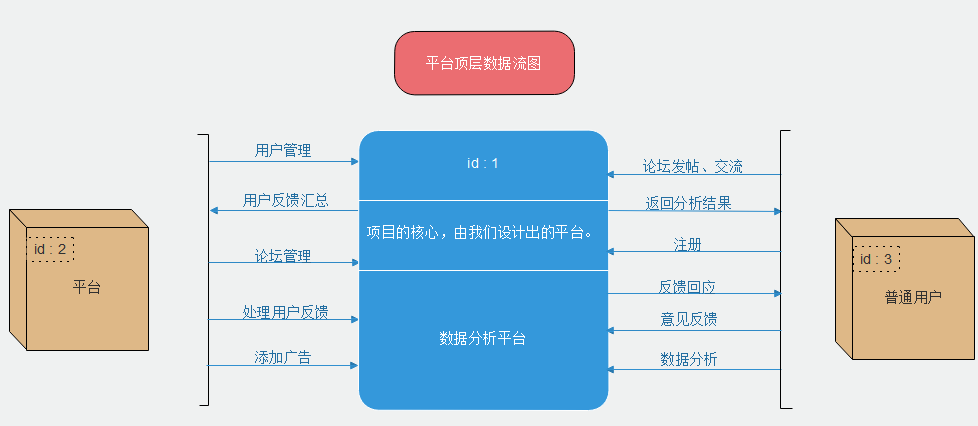
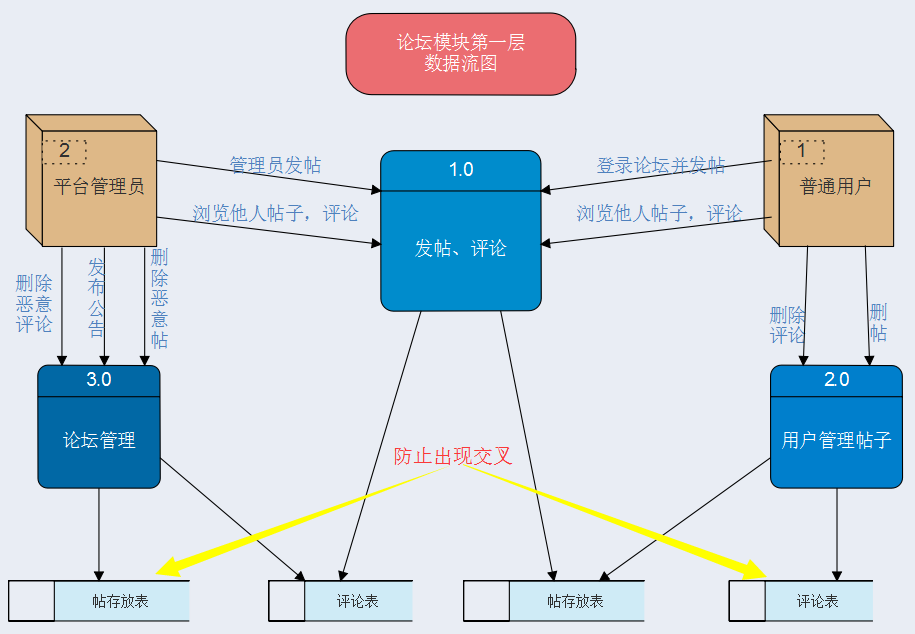
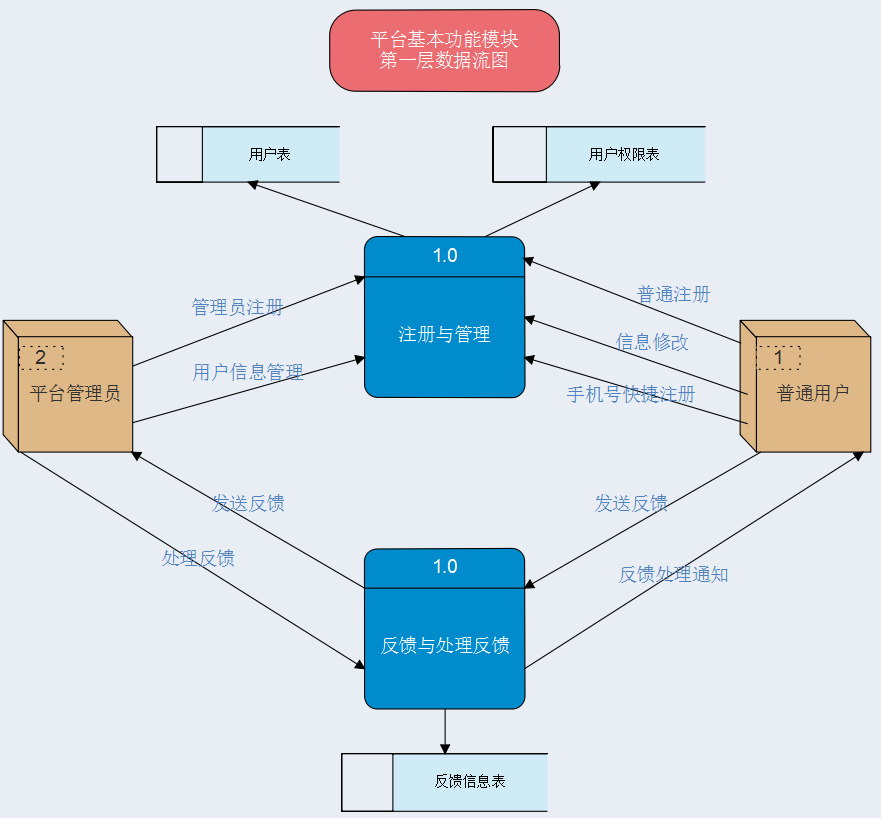
在绘制完平台顶层数据流图以后,针对平台各个模块绘制1级数据流图如下:
② 论坛模块
③平台基本功能模块
④ 数据分析模块

1.1.1 平台的总体实现方案
在绘制数据流图以后,我们通过理解各个模块的数据输入输出流,即可对整个平台的实现有总体的规划,确定总体的实现方案,我们准备从如下三个模块入手:
1.1.1.1 组成系统的物理元素清单
| 总体元素 | 作用与功能 |
| 数据库 | 是平台的基础,反映了平台的设计结构
|
| 数据分析接口 | 是完成平台数据处理功能的模块
|
|
总体平台 | 包括主页面、数据分析页面、用户管理页面、论坛区、用户反馈页面等。整个项目的功能以平台为载体来实现。 |
1.1.1.2 实现进度计划
关于这部分,在上次的作业中我们已经大致规划过了,但由于还未对整个项目进行上述那样详细的功能分析与设计,部分设想需要进行适当修改,结合上面的分析对其进行修改如下:
| 分工 | 负责人 | 实现方式 |
| 前端 | 纪芳 & 廖文静 | HTML + CSS5 + JAVASCRIPT
|
| 后台 | 林光涵 & 林瑞溶(辅助) | PYTHON + MYSQL
|
| 数据库 | 张泽政 & 林瑞溶 | MYSQL
|
| 算法接口 | 刘涛 & 张泽政 (辅助) |
|
| 时间 | 负责人 | 负责任务 |
|
第11-12周 | 刘涛、张泽政 | 完成对项目的配置,确定数据分析的主要实现方式。
|
| 林光涵、林瑞溶 | 学习Python,对过程中已经写好的页面与数据库进行前后台对接。
| |
| 纪芳、廖文静 | 前端页面的编写。
| |
| 张泽政、林瑞溶 | 对数据库进行全面的建立,并根据实际情况对数据库进行修改与重构。 | |
|
|
|
|
|
第13周 | 刘涛、张泽政 | 实现数据分析接口,并进行数据分析的优化。 |
| 林光涵、林瑞溶 | 对后台的逻辑进行补充设计,完善平台功能。 | |
| 纪芳、廖文静 | 对前端页面细节进行优化。 | |
|
|
|
|
|
第14周 |
小组全体成员 | 对基本成型的平台进行审核,平台测试,并发现遇到的问题,及时进行修正、改进。采取调查的方式让其他人体验平台,获取他人意见并进行改进。 |
1.1.1.3 系统流程图(HIPO图)
1.2数据库逻辑结构设计
1.2.1 建表
数据库初步建表如下:
| 表 | 表 名 | 作 用 |
| 用户信息表 | table_user_info | 存储用户的基本信息 |
|
用户权限表 |
table_user_rights | 记录用户的权限,如普通用户、管理员。 单独列一张表而不是把表分为用户表和管理员表的理由: ① 普通用户和管理员有很多相同的属性,这样可以节省空间。 ② 最主要的原因,管理员可以修改用户信息,假如分为两张表,就意味着管理员可以随意修改用户的权限。 |
|
操作记录表 |
table_op_record | 记录用户在平台的操作以及所使用的数据存放路径,如上传数据、分析数据等,用户进行分析的数据将自动保存,只保存最近的5次操作。 |
|
反馈信息表 |
table_feedback | 用户向平台提出意见,由管理员来接收,管理员根据意见选择性的回应,回应消息由用户接收。 |
| 发贴表 | table_poster | 参考自博客园的博客存放形式,把帖子的内容存放到数据库里。 |
| 图片存放表 | table_picture | 记录用户评论、发帖时使用的图片路径。 |
| 评论表 | table_comment | 用户对某个帖子的回复信息。 |
1.2.2确定各字段的约束条件
在这部分中,我们首先要确定每个表具有哪些字段, 在确定时还可以顺便完成一步我们在物理设计时完成的任务:确定每个字段的类型,如整数,char等,对于char类型要格外注意,既不能把长度开的太大,导致空间的浪费,也不能开的太小,导致部分数据丢失。
①表名:table_user_info
别名:用户信息表
描述:存放用户的基本信息。
| 中文 | 列名 | 数据类型 | 约束条件 | 描述 |
| 用户名 | user_login_name | char(25) | PK | 唯一标识某个用户。 |
|
用户密码 |
user_pwd | char(15) | Not Null, Check(长度≥6 & 不能为纯数字) |
用户的密码,非空. check约束由触发器实现。 |
| 用户昵称 | user_Nick_name | char(20) | Default. | 用户的昵称,在注册时若未指定,使用触发器生成默认值。 |
| 用户手机号 | user_phone | Vachar(11) | Unique | 因为可以通过手机快捷注册,所以该列必须加unique约束。 |
| 用户邮箱 | user_Email | char(25) | - | 服务器脚本检验邮箱的合法性。 |
②表名:table_user_rights
别名:用户权限表。
描述:记录用户的权限,如普通用户、管理员。
| 中文 | 列名 | 数据类型 | 约束条件 | 描述 |
| 用户名 | user_login_name | char(25) | PK,FK | 唯一标识某个用户,外键关联自用户信息表。 |
|
用户身份 |
user_status | char(15) |
Not Null |
用户的权限。 |
③表名:table_op_record
别名:操作记录表
描述:记录用户在平台的操作以及所使用的数据存放路径,用户在平台进行操作(保存数据,数据分析)时,平台自动保存用户使用的数据并生成相应记录。
| 中文 | 列名 | 数据类型 | 约束条件 | 描述 |
| 操作时间 | opt_time | datetime | PK | 产生操作的时间。 |
|
用户名 |
user_login_name | char(25) |
FK,PK | 唯一标识某个用户,外键关联自用户信息表。 |
| 操作类型 | opt_type | char(20) | Not Null | 操作的类型(如保存数据、数据分析)。 |
|
数据存放路径 |
opt_data_route |
char(50) |
- | 因为用户使用的数据量会非常大,因此不宜保存在数据库中,这里保存方法是保存在文件中,由数据库指向其存放路径。 |
④表名:table_feedback
别名:反馈表
描述:用户向平台提出意见,由管理员来接收,管理员根据意见选择性的回应,回应消息由用户接收。
| 中文 | 列名 | 数据类型 | 约束条件 | 描述 |
| 消息接收时间 | fbk_receive_time | datetime | PK | 产生操作的时间。 |
|
发送者用户名 |
fbk_sender |
char(25) |
FK,PK | 唯一标识消息的发送者,外键关联自用户信息表。 |
| 接收者用户名 | fbk_recipient | char(25) | FK,PK | 唯一标识消息的接收者,外键关联自用户信息表。 |
| 消息类型 | fbk_info_type | char(25) | Not Null | 发送消息的类型,如用户反馈、管理员回复等。 |
|
消息内容 |
fbk_info_content |
varchar(255) |
- | 消息的内容,一般一条反馈消息不会太长,默认255个字符足够,而考虑到有些特殊情况,这里采用边长的varchar类型,可以根据实际来调整大小。 |
⑤表名:table_poster
别名:发帖表
描述:参考自博客园的博客存放形式,把帖子的内容存放到数据库里。
| 中文 | 列名 | 数据类型 | 约束条件 | 描述 |
|
帖子ID |
post_id |
varchar(60) |
PK | 帖子的ID,该属性是为了方便的标识某个帖子,由用户名和发帖时间拼接生成(保证唯一性),生成操作由触发器实现。 |
|
发贴者用户名 |
fbk_sender |
char(25) |
FK | 唯一标识发帖者,外键关联自用户信息表。 |
| 发帖时间 | post_time | datetime | Default | 发帖的时间,默认为当前时间 |
| 发帖内容 | post_content | varchar(5000) | Not Null | 参考自百度贴吧的帖子,一个帖子的内容最多5000字符。 |
|
帖子标题 |
post_title |
char(80) |
Not Null |
每个帖子应该有一个标题。 |
| 帖子类型 | post_type | char(20) | Not Null | 帖子的类型 |
⑥表名:table_comment
别名:帖子评论表
描述:参考自博客园的博客存放形式,把帖子的内容存放到数据库里。
| 中文 | 列名 | 数据类型 | 约束条件 | 描述 |
|
评论ID |
comt_id |
varchar(60) |
PK | 评论的ID,该属性是为了方便的标识某个帖子,由被评论帖子ID和评论时间、评论者用户名拼接生成(保证唯一性),生成操作由触发器实现。 |
|
发贴者用户名 |
comt_commenter |
char(25) |
FK |
唯一标识评论者,外键关联自用户信息表。 |
| 评论时间 | comt_time | datetime | Default | 评论的时间,默认为当前时间 |
| 被评论贴ID | comt_post_id | varchar(60) | FK | 被评论的帖子的ID,外键关联自发帖表。 |
|
评论内容 |
comt_content |
varchar(2000) |
Not Null |
参考自百度贴吧,一个回复最多2000字符。 |
⑦表名:table_picture
别名:图片表
描述:记录用户评论、发帖时使用的图片路径。
| 中文 | 列名 | 数据类型 | 约束条件 | 描述 |
|
链接ID |
pic_id |
varchar(60) |
- | 图片链接到哪个ID,这个ID指的是帖子的ID或评论的ID,以便加载帖子或评论时读取图片。 |
|
图片存放路径 |
pic_route |
char(50) |
- | 一般图片不会直接存放在数据库中,而是存放在物理磁盘上,数据库存放它的路径。 |
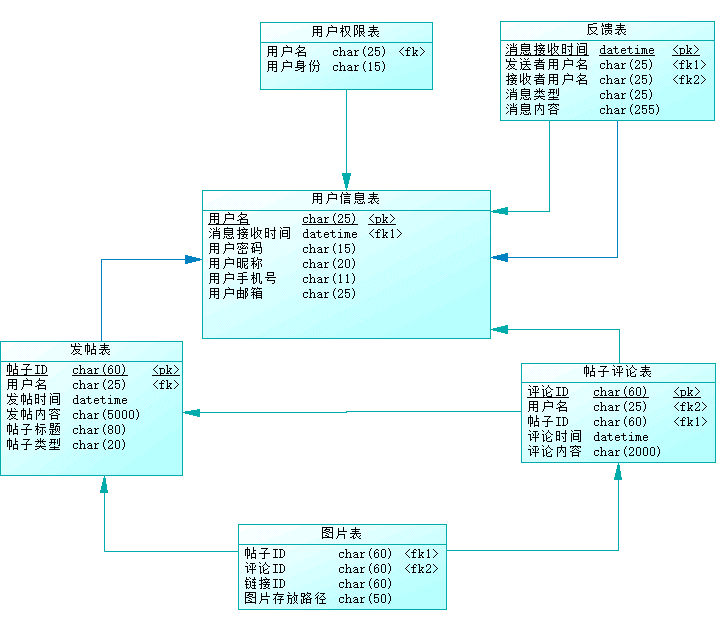
1.2.3 确定表之间的关系
表之间的关系最好通过PDM图来表示,如下:
二、详细设计
2.1 数据库的物理结构设计
在“1.2.2确定各字段的约束条件”中,已经完成了物理结构设计中的重要的一部分,即确定每个字段的类型,如整数,char等,对于char类型要格外注意,既不能把长度开的太大,导致空间的浪费,也不能开的太小,导致部分数据丢失。
在这里,我们进行进一步的物理结构设计: 确定数据库文件的存放路径。
物理模型如下:
物理模型
| 参数 | 参数值 | |
| 数据库名 | Data_analyze_Project | |
| 主文件组 | ||
| 逻辑数据文件名① | PlatForm_Main_1 | |
| 物理数据文件名① | C:PlatForm_Main_1.mdf | |
| 数据文件的初始大小① | 0.5GB | |
| 数据文件的最大大小① | Unlimited | |
| 数据文件增长帐度① | 200MB | |
| 逻辑数据文件名② | PlatForm_Main_2 | |
| 物理数据文件名② | C:PlatForm_Main_2.ndf | |
| 数据文件的初始大小② | 0.5GB | |
| 数据文件的最大大小② | Unlimited | |
| 数据文件增长帐度② | 200MB | |
| 次要文件组: | ||
| 逻辑数据文件名① | PlatForm_Minor_1_1 | |
| 物理数据文件名① | C:PlatForm_Minor_1_1.ndf | |
| 数据文件的初始大小① | 600MB | |
| 数据文件的最大大小① | Unlimited | |
| 数据文件增长帐度① | 200MB | |
|
| ||
| 逻辑数据文件名② | PlatForm_Minor_1_2 | |
| 物理数据文件名② | C:PlatForm_Minor_1_2.ndf | |
| 数据文件的初始大小② | 600MB | |
| 数据文件的最大大小② | Unlimited | |
| 数据文件增长帐度② | 200MB | |
| 次要文件组: | ||
| 逻辑数据文件名① | PlatForm_Minor_2_1 | |
| 物理数据文件名① | C:PlatForm_Minor_2_1.ndf | |
| 数据文件的初始大小① | 2GB | |
| 数据文件的最大大小① | Unlimited | |
| 数据文件增长帐度① | 400MB | |
|
| ||
| 逻辑数据文件名② | PlatForm_Minor_2_2 | |
| 物理数据文件名② | C:PlatForm_Minor_2_2.ndf | |
| 数据文件的初始大小② | 2GB | |
| 数据文件的最大大小② | Unlimited | |
| 数据文件增长帐度② | 400MB | |
| 日志文件 | ||
| 日志逻辑文件名① | PlatForm_Log1 | |
| 操作系统日志文件名① | C:PlatForm_Log1.ldf | |
| 日志文件初始大小① | 0.5GB | |
| 日志文件增长幅度① | 150MB | |
|
| ||
| 日志逻辑文件名② | PlatForm_Log2 | |
| 操作系统日志文件名② | C:PlatForm_Log2.ldf | |
| 日志文件初始大小② | 0.5GB | |
| 日志文件增长幅度② | 150MB | |
对上述参数进行如下解释:主文件组包括两个文件,用于存放数据库的核心信息、数据字典等,这里核心信息指代用户信息。两个次要文件组,第一个次要文件组存放用户的操作信息,第二个次要文件组开的大小比较大,是为了存放比较占空间的贴子以及评论。
现针对具体参数进一步解释:
①主文件组的一个文件用来存放用户信息,一个文件大小为0.5GB,文件增幅为200MB,而对应一个用户的信息大小为 4 + 25 + 20 + 50 = 99B,也就是说 初始情况下,主文件组能存放的用户信息数量约为 0.5GB/99B = 5422938条,而一次文件增长为200MB,能增加的用户信息数量约为 200MB / 99B = 2118335条,这显然是够用的。
②第一个次要文件组存放用户的操作信息,包括两个文件,大小分别为600MB,总大小即为约1.2GB,那么初始情况下,能存放的操作信息为 1.2GB/(4+25+20+50) = 13015052条,两个文件各自一次增长加一起为400MB,能存放的信息数量为:4236670条,显然也是合理的。
③第二个次要文件组开的大小比较大,是为了存放比较占空间的贴子以及评论,包括两个文件,大小分别为2GB,总大小即为4GB,假设平均一个帖子有20条评论,共有20张图片,那么一个帖子的总大小为(60+25+5000+80+20+20*(60+25+60+4+2000)+20*(60+50))=50385B,则初始情况下,能存放的贴数为:4GB/50385B = 85242条,一次增加的大小共为800MB,能存放的信息数量为:16649条,一般情况下应该也是足够的。
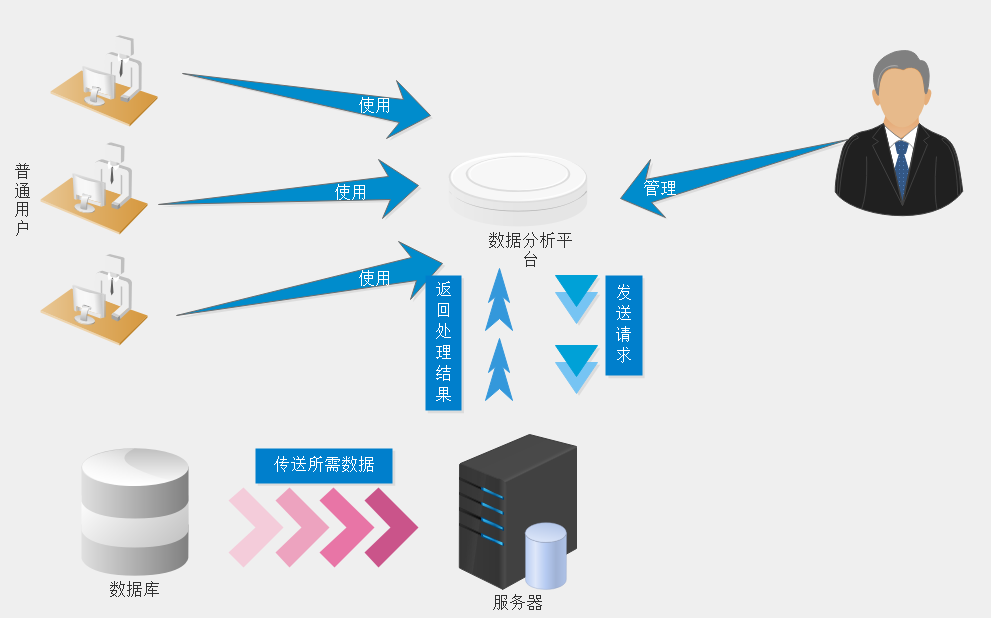
2.2 系统接口设计
2.2.1 外部接口
在此通过外部接口简述硬件输入输出:
2.2.2 内部接口
(1)开发模式:采用flask框架结合前端HTML、CSS、JS、Jquery以及mysql组合而成的MVC开发模式。
(2)开发使用的ide: pycharm
(3)MVC模式以及后台目录结构设计
MVC图如下:

根据MVC设计的目录结构:
一级目录结构:
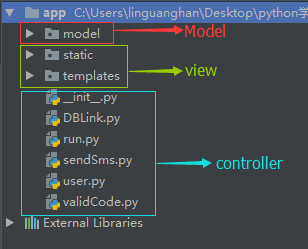
二级目录结构:
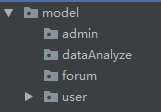
Model层:分为四个模块分别是管理员模块(admin),数据分析模块(dataAnalyze),论坛模块(forum),用户模块(user)
View层:
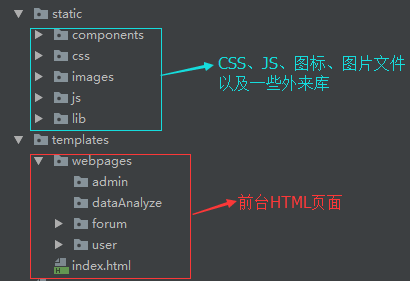
Controller层:
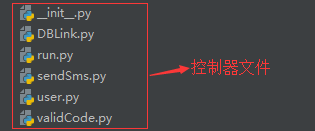
(4)数据传递方式及代码示例:
View层与Controller层的数据传递
1)view通过超链接的方式给Controller层传递数据

2)view通过ajax的方式给Controller层传递数据
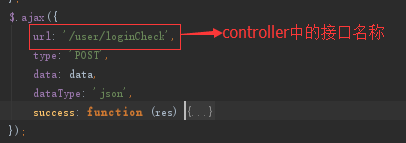
3)Controller层返回数据给view层
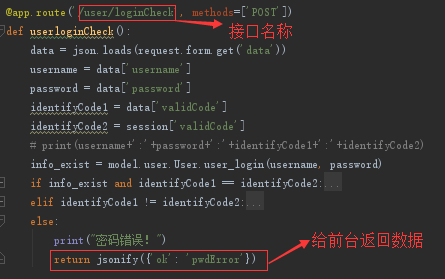
Model层与Controller层的数据传递
Control层给出参数直接调用Model层中的方法
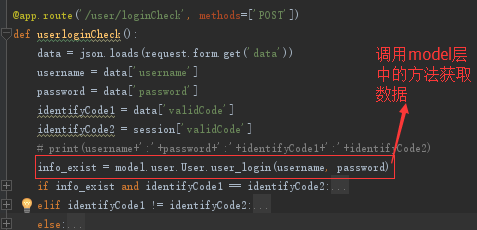
2.2.3 神经网络模型接口
①为什么使用神经网络模型?
我们用到的数据分析模型是神经网络模型,数学上已经证明,它具有实现任何复杂非线性映射的功能,也就是说这个模型有能力完成从输入数据到输出数据的映射过程。另外在分类问题上,很多研究论文均使用神经网络的方法或者其变形,包括现在很流行的对于图片的分类也采用这种方法的变形,于是我们基于此种趋势,也选择使用神经网络模型分析数据,挖掘数据的内部结构信息。
②本模型中的神经网络模型的基本原理?
神经网络模型主要是多个神经元相互连接组成的层状结构,结构如下图所示:
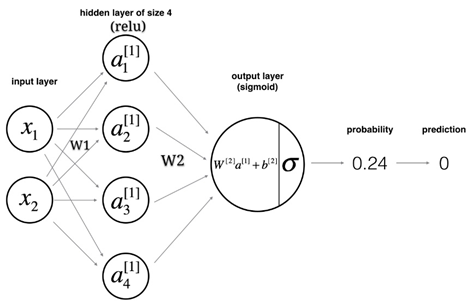
第一层作为数据输入层,此层节点个数等于数据的维度数目;最后一层作为分类层,我们选择是sigmoid作为分类激活函数是因为最后的结果之后两类:0或者1。中间层被称作隐含层,这些层是神经网络能够完成复杂映射的关键。
更加具体的说,我们处理这个问题的整个流程如下图:
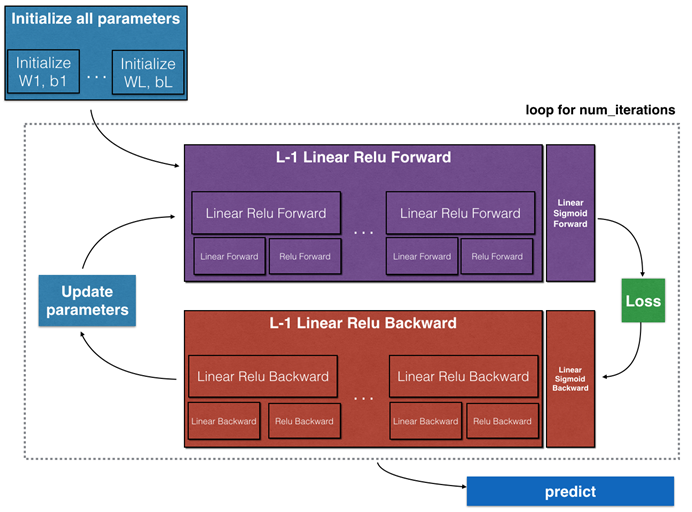
③模型概述:
本模型的使用包括训练阶段与测试阶段:
训练阶段的流程图为:
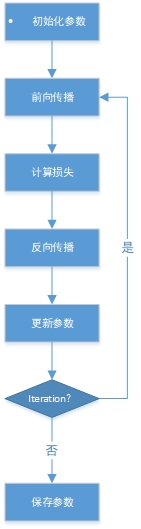
测试阶段为:
训练的模型 + 测试数据→→预测结果(概率)
在我们的项目中,网络的结构设置为11,10,1,这些参数是每一层的神经元的数目,除了最后一层采用sigmoid作为激活函数,第一层(数据层)不处理之外,其他的层均采用relu函数进行激活,增加了网络的非线性映射能力。
④实现方式的优点?
在实现神经网络的时候,我们封装了两个类,一个是NNtrainer类,用于数据的训练,一个是NNpredicter类,用于测试数据的预测。在NNtrainer类中,我们实现从数据的读入,训练,模型的存储全过程,可以很轻松的调用其中功能,实现训练过程。NNpredicter也是如此。
2.3 软件过程设计及用户接口描述
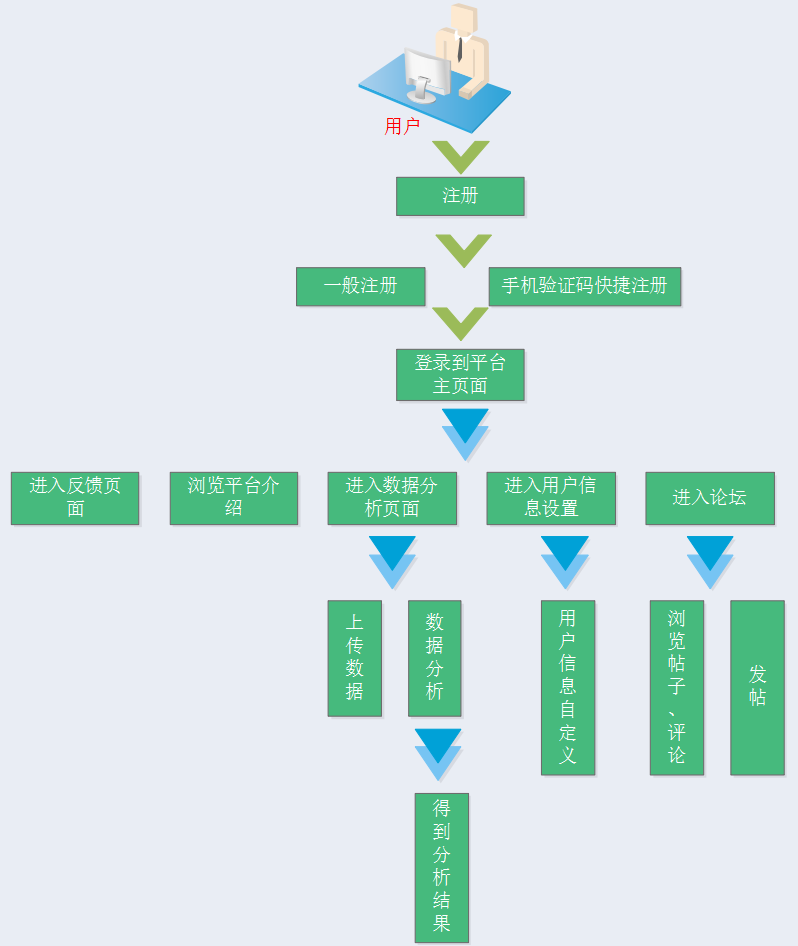
进行上述详细的分析以后,站在普通用户的角度,对平台的用户过程进行如下图示:
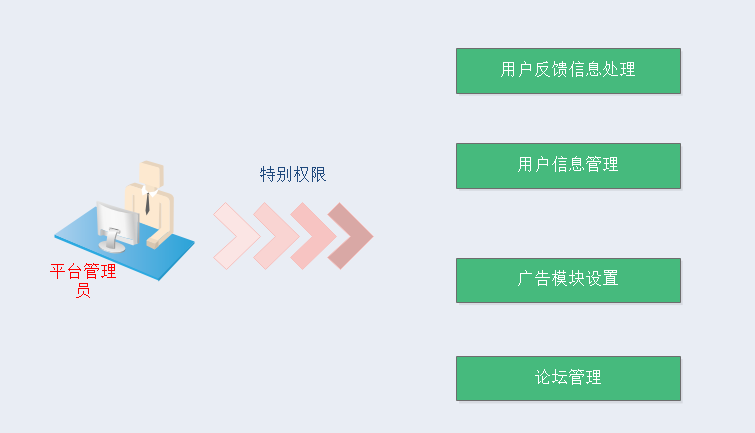
而管理员用户的操作与用户类似,但是管理员会具有一些特别的权限,如下图:
转载于:https://www.cnblogs.com/ylemfei-7797110/p/7899310.html
最后
以上就是含蓄睫毛最近收集整理的关于第五次作业——软件设计第五次作业——软件设计的全部内容,更多相关第五次作业——软件设计第五次作业——软件设计内容请搜索靠谱客的其他文章。








发表评论 取消回复