引言
我们提出一个新的识别结构:bilinear CNN,它是由两个特征提取器组成,它们的输出在对应的位置进行外积相乘,形成优秀的图像表示。这个结构以平移不变的方式对成对的局部特征进行交叉建模。它还概括了各种无序的纹理描述符,如Fisher向量、VLAD和O2P【不懂】。我们实验使用的特征是来自卷积网了提取的。双线性形式简化了计算,可以对两个网络进行端到端的训练。这种结构很适合细粒度识别。我们进行了实验和可视化,分析了fine-tuning和网络选择对这个模型的精度和速度的影响。结果显示这个模型更加容易训练、更加简单。
简介
细粒度识别的类内差距大、类间差距小。类内差距大:可能因为姿势、拍摄位置、光照等噪音带来的差异远大于能够区分物体的特征比如毛色、肢体等细微差异。【那么,我们的任务就可以集中在如何排除噪音、或者如何选择特征?】除了定位然后特征提取,还有一种方法是获得一个鲁邦的图像表达:VLAD 、 Fisher vector、 SIFT features。这是十年前的方法了。
尽管这些方法能够获得局部特征交互【 local feature interactions 也不知道该怎么翻译】,但是这些方法性能低。
我们的方法包含两个CNN网络,它们的输出在对应的像素位置,进行外积相乘。外积能够获得通道特征之间成对的相关性,对局部特征交互进行建模。比如一个是part 探测器,另外一个就是特征提取器。双线性模型还概括了多种纹理描述符。我们的模型和一个视觉假设有关:人的视觉是有两个数据流,ventral stream 告诉人们这个object是什么, dorsal stream 告诉人们这个物体在哪儿。由于,我们的模型在两个CNN的输出是线性的,所以我们命名为biliner CNN。
Bilinear Model
这里介绍一下双线性模型的一般公式,以及当extractor 为CNN的时候的具体情况。
文中的描述不是很具体,所以我还选择看了一下博客。自己描述一下这个过程,参考博客:https://zhuanlan.zhihu.com/p/62532887
f
A
∈
R
M
∗
L
,
f
B
∈
R
N
∗
L
b
(
l
,
I
,
f
A
,
f
B
)
=
f
A
T
(
l
,
I
)
f
B
(
l
,
I
)
∈
R
M
∗
N
ξ
(
I
)
=
∑
l
b
(
l
,
I
,
f
A
,
f
B
)
∈
R
M
∗
N
x
=
v
e
c
t
o
r
(
ξ
(
I
)
)
∈
R
M
N
∗
1
x
=
s
i
g
n
(
x
)
∣
x
∣
x
=
x
/
∣
∣
x
∣
∣
2
f_{A} in R^{M*L}, f_{B} in R^{N*L} newline newline b(l, I, f_{A}, f_{B})=f_{A}^{T}(l, I)f_{B}(l, I) in R^{M*N} newline newline xi (I) = sum_{l}b(l,I,f_{A}, f_{B}) in R^{M*N} newline newline x = vector(xi(I) ) in R^{MN*1} newline newline x = sign(x)sqrt{|x|}newline newline x = x/||x||_{2}
fA∈RM∗L, fB∈RN∗L b(l,I,fA,fB)=fAT(l,I)fB(l,I)∈RM∗N ξ(I)=l∑b(l,I,fA,fB)∈RM∗N x=vector(ξ(I))∈RMN∗1 x=sign(x)∣x∣ x=x/∣∣x∣∣2
这段公式的意思:两个特征
f
A
f_{A}
fA和
f
B
f_{B}
fB ,它们的size分别是 M * L 和N * L,这两个特征的位置是对应的,比如都是从同一块图像区域extractor。
f
A
f_{A}
fA和
f
B
f_{B}
fB进行一个外积,然后把所有位置得到的外积求和,之后进行向量化,对得到的向量进行两个归一化(矩归一和L2归一)。
当使用的是卷积特征提取,那么 L=1,因此整个操作是这样的:
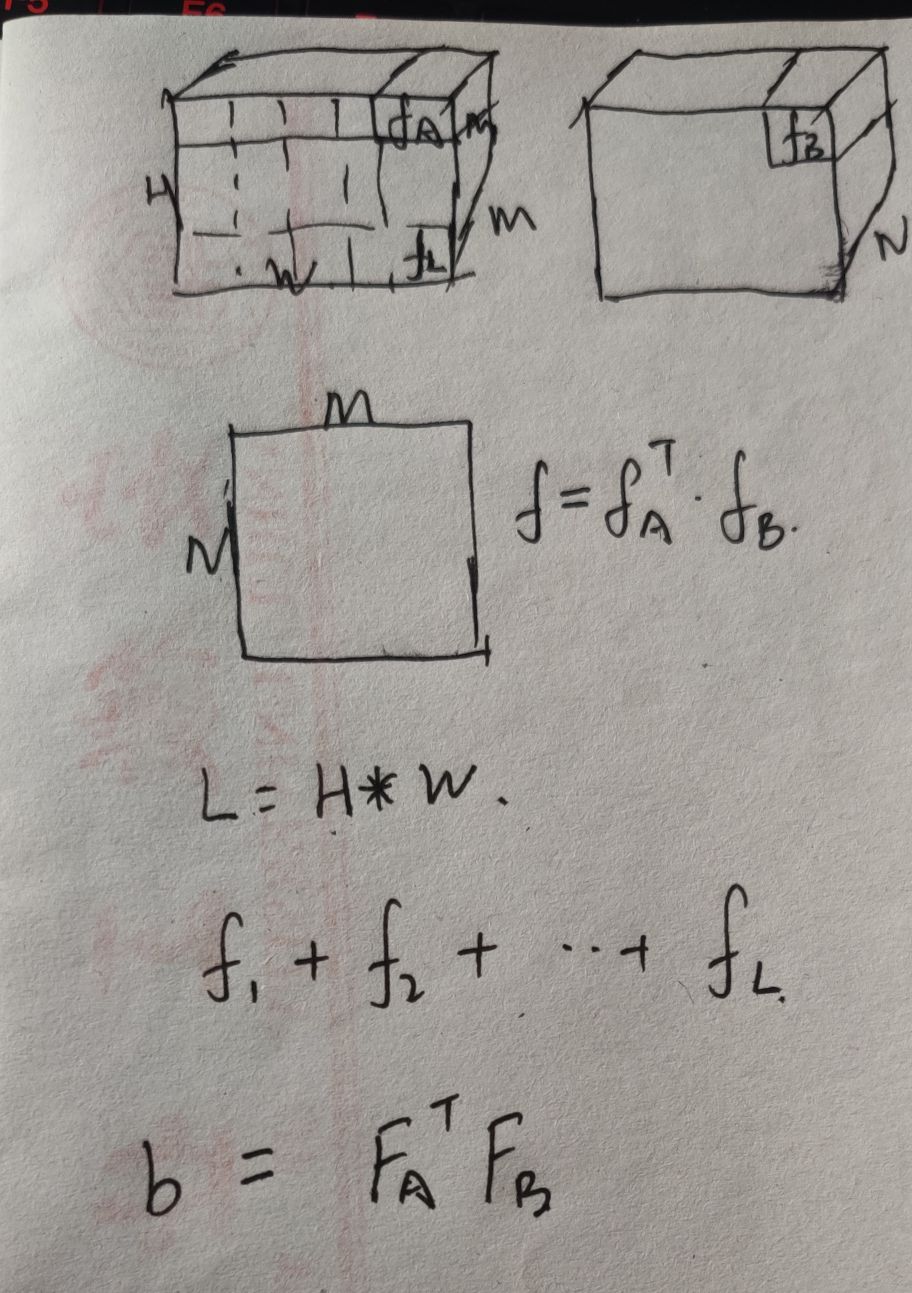
这个模型存在的问题呢,就是M*N,这个维度太高了,所以要想办法降低这个维度。
最后
以上就是老迟到往事最近收集整理的关于Bilinear CNN Models for Fine-grained Visual Recognition-笔记引言简介Bilinear Model的全部内容,更多相关Bilinear内容请搜索靠谱客的其他文章。








发表评论 取消回复