KNN–k近邻学习
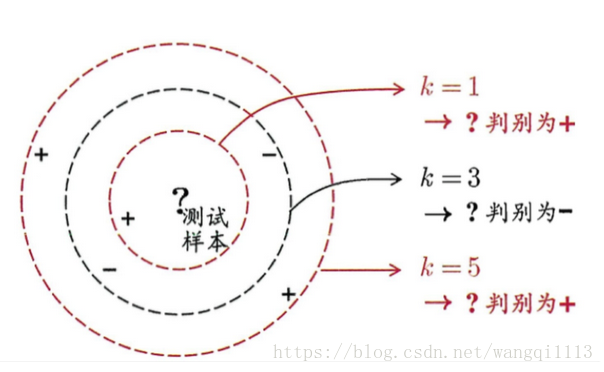
KNN基于某种距离度量在训练集中找出与其距离最近的k个带有真实标记的训练样本,然后基于这k个邻居的真实标记来进行预测
- 分类任务:投票法或者加权投票法(基于距离远近,距离越近的样本权重越大)
- 回归任务:平均法或者加权平均法(基于距离远近,距离越近的样本权重越大)
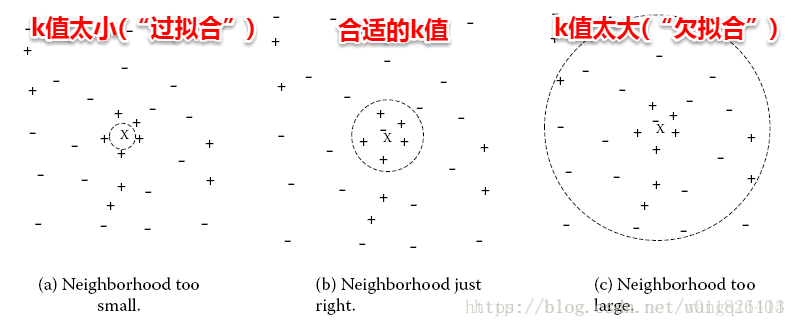
KNN算法的核心在于k值的选取以及距离的度量。k值选取太小,模型很容易受到噪声数据的干扰,例如:极端地取k=1,若待分类样本正好与一个噪声数据距离最近,就导致了分类错误;若k值太大, 则在更大的邻域内进行投票,此时模型的预测能力大大减弱,例如:极端取k=训练样本数,就相当于模型根本没有学习,所有测试样本的预测结果都是一样的。一般地我们都通过交叉验证法来选取一个适当的k值。(??)
KNN的距离度量可以选择欧式距离、马氏距离、曼哈顿距离等
欧式距离
曼哈顿距离
切比雪夫距离
马氏距离
其中S为协方差矩阵,若S为单位矩阵,则马氏距离转换成欧氏距离。
https://my.oschina.net/hunglish/blog/787596这个网址上有各种距离度量公式的介绍
- 优点:精度高,泛化错误率不超过贝叶斯最优分类器的错误率的两倍;对异常值不敏感,无数据输入假定,懒惰式学习,无训练开销
- 缺点:计算复杂度高,空间复杂度高,容易受样本不平衡问题影响。
降维
在高维情形下,数据样本将变得十分稀疏,因为此时要满足训练样本为“密采样”的总体样本数目是一个触不可及的天文数字;训练样本的稀疏使得其代表总体分布的能力大大减弱,从而消减了学习器的泛化能力;同时当维数很高时,计算距离也变得十分复杂,甚至连计算内积都不再容易。
缓解维数灾难的一个重要途径就是降维,(另一个途径是特征选择),即通过某种数学变换将原始高维空间转变到一个低维的子空间。(通过某种数学变化相当于原始高维空间乘以一个矩阵 ),在这个子空间中,样本的密度将大幅提高,同时距离计算也变得容易。这时也许会有疑问,这样降维之后不是会丢失原始数据的一部分信息吗?这是因为在很多实际的问题中,虽然训练数据是高维的,但是与学习任务相关也许仅仅是其中的一个低维子空间,也称为一个低维嵌入,例如:数据属性中存在噪声属性、相似属性或冗余属性等,对高维数据进行降维能在一定程度上达到提炼低维优质属性或降噪的效果。特征选择在于选择和任务相关的特征,去掉无关的特征;而降维则是特征之间有相关性,提取出主要特征。
降维的概念:
采用某种映射方法,将高维空间中的数据点映射到低维度的空间中。降维的本质是学习一个映射函数 f : x->y,其中x是原始数据点的表达,目前最多使用向量表达形式。 y是数据点映射后的低维向量表达,通常y的维度小于x的维度。
MDS算法
要求:原始空间中样本之间的距离在低维空间中得以保持。 即得到多维缩放(multiple Dimensional Scaling,简称MDS)
假定m个样本在原始空间中任意两两样本之间的距离矩阵为D∈R(m*m),我们的目标便是获得样本在低维空间中的表示Z∈R(d’*m , d’< d),且任意两个样本在低维空间d’中的欧式距离等于原始空间d中的距离,即||zi-zj||=Dist(ij)。因此接下来我们要做的就是根据已有的距离矩阵D来求解出降维后的坐标矩阵Z。
变化前后距离矩阵D不变

令降维后的样本坐标矩阵Z被中心化,中心化是指将每个样本向量减去整个样本集的均值向量,故所有样本向量求和得到一个零向量(每列加和为0)。
设tr(B)表示矩阵B的迹(trace),则 tr(B)=∑i=1m||zi||2 t r ( B ) = ∑ i = 1 m | | z i | | 2

故可以根据dist的值求出b的值,也就可以根据矩阵D的值求出内积矩阵B的值
对B进行特征分解, B=QAQT B = Q A Q T ,其中,A = diag( λ1,λ2,...λd λ 1 , λ 2 , . . . λ d )为特征值构成的特征矩阵, λ1>=λ2>=...>=λd λ 1 >= λ 2 >= . . . >= λ d ,选取前d’个特征值构成对角矩阵A’,令Q’为对应的特征向量矩阵,则
当然也可以选取所有的非零特征值构成对角矩阵,根据所选的特征值构造特征向量矩阵求Z。
MDS的算法流程

MDS先求出了低维空间的内积矩阵B,接着使用特征值分解计算出了样本在低维空间中的坐标,但是并没有给出通用的投影向量w。对于新样本,没办法映射到低维空间,现在采用的办法是训练样本的高维空间坐标作为输入,低维空间的坐标作为输出,训练一个 回归学习器进行预测。
一般来说,获得低纬子空间最简单的就是对原始高维空间进行 线性变化(矩阵)。给定d维空间中的样本X,变化之后到d’维空间中的样本
W=[d,d’]是变化矩阵,Z是样本在新空间中的表达。
基于线性变化进行降维的方法称为 线性降维方法。他们都符合上述公式的形式,PCA就是线性降维的典型代表。
主成分分析PCA
主成分分析是通过正交变换将一组可能存在相关性的变量转换为一组线性不相关的变量,转换后的这组变量叫主成分。主成分分析(PCA)直接通过一个线性变换,将原始空间中的样本投影到新的低维空间中。简单来理解这一过程便是:PCA采用一组新的基来表示样本点,其中每一个基向量都是原来基向量的线性组合,通过使用尽可能少的新基向量来表出样本,从而达到降维的目的。PCA可以看作逐渐选择方差最大的方向,使得任何数据投影的第一大方差在第一个坐标(称为第一主成分)上,第二大方差在第二个坐标(第二主成分)上,依次类推。主成分分析经常用减少数据集的维数,同时保持数据集的对方差贡献最大的特征。这是通过保留低阶主成分,忽略高阶主成分做到的。这样低阶成分往往能够保留住数据的最重要方面
假设使用d’个新基向量来表示原来样本,实质上是将样本投影到一个由d’个基向量确定的一个超平面上(即舍弃了一些维度),若新的超平面具有如下性质:
- 最近重构性:样本点到超平面的距离足够近,即尽可能在超平面附近;
- 最大可分性:样本点在超平面上的投影尽可能地分散开来,即投影后的坐标具有区分性。
最近重构性与最大可分性虽然从不同的出发点来定义优化问题中的目标函数,但最终这两种特性得到了完全相同的优化问题:
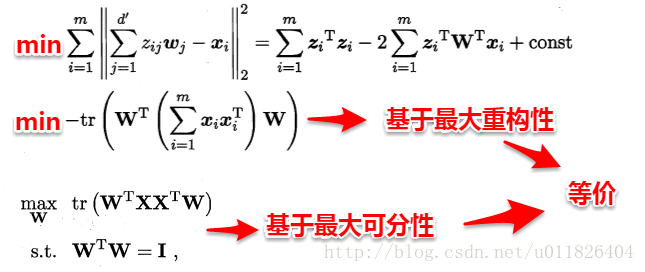
使用拉格朗日乘子法,求得:

PCA的原理介绍(数学公式推导)https://www.cnblogs.com/pinard/p/6239403.html
PCA的算法流程

贴一个博客https://blog.csdn.net/u011826404/article/details/57472730详细介绍了主成分分析以及有一个例子说明
核化线性降维
若我们的样本数据点本身就不是线性分布,(若直接使用线性降维方法对三维空间观察到的样本进行降维,则将丢失原本的低维结构)。那还如何使用一个超平面去近似表出呢?因此也就引入了核函数,即先将样本映射到高维空间,再在高维空间中使用线性降维的方法。下面主要介绍核化主成分分析(KPCA)的思想。核函数的作用就是将样本从低维空间映射到高维空间。
若核函数的形式已知,即我们知道如何将低维的坐标变换为高维坐标,这时我们只需先将数据映射到高维特征空间,再在高维空间中运用PCA即可。但是一般情况下,我们并不知道核函数具体的映射规则,例如:Sigmoid、高斯核等,我们只知道如何计算高维空间中的样本内积,这时就引出了KPCA的一个重要创新之处:即空间中的任一向量,都可以由该空间中的所有样本线性表示。证明过程也十分简单:

zi
z
i
是样本点
xi
x
i
在高维特征空间中的像。设
zi=φ(xi)
z
i
=
φ
(
x
i
)
,其中,
φ
φ
为函数
因为我们不清楚函数 φ φ 的具体形式,故引入核函数 t(xi,xj) t ( x i , x j )
其中,K为核函数 t(xi,xj) t ( x i , x j ) 对应的核矩阵,显然,该问题归结为特征值分解的问题,取K最大的d’个特征值对应的特征向量即可。
对于新样本,其投影后的坐标为
KPCA在计算降维后的坐标表示时,需要与所有样本点计算核函数值并求和,因此该算法的计算开销十分大。
流形学习
流形学习(manifold learning)是一种借助拓扑流形概念的降维方法,流形是指在局部与欧式空间同胚的空间,即在局部与欧式空间具有相同的性质,能用欧氏距离计算样本之间的距离。这样即使高维空间的分布十分复杂,但是在局部上依然满足欧式空间的性质,基于流形学习的降维正是这种“邻域保持”的思想。其中等度量映射(Isomap)试图在降维前后保持邻域内样本之间的距离,而局部线性嵌入(LLE)则是保持邻域内样本之间的线性关系,下面将分别对这两种著名的流行学习方法进行介绍。
等度量映射
保持近邻样本之间的距离
等度量映射的基本出发点是:高维空间中的直线距离具有误导性,因为有时高维空间中的直线距离在低维空间中是不可达的。因此利用流形在局部上与欧式空间同胚的性质,可以使用近邻距离来逼近测地线距离,即对于一个样本点,它与近邻内的样本点之间是可达的,且距离使用欧式距离计算,这样整个样本空间就形成了一张近邻图,高维空间中两个样本之间的距离就转为最短路径问题。可采用著名的Dijkstra算法或Floyd算法计算最短距离,得到高维空间中任意两点之间的距离后便可以使用MDS算法来其计算低维空间中的坐标。
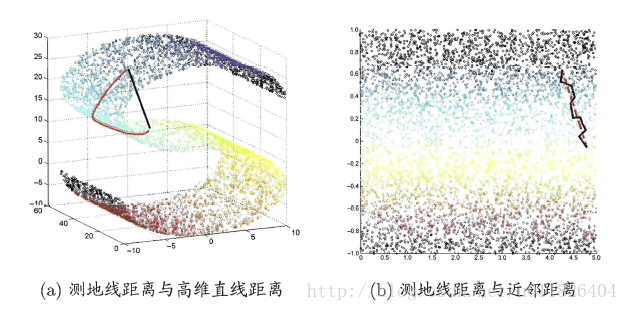
等度量映射的算法流程

对于近邻图的构建,常用的有两种方法:一种是指定近邻点个数,像kNN一样选取k个最近的邻居;另一种是指定邻域半径,距离小于该阈值的被认为是它的近邻点。但两种方法均会出现下面的问题:
- 若邻域范围指定过大,则会造成“短路问题”,即本身距离很远却成了近邻,将距离近的那些样本扼杀在摇篮。
- 若邻域范围指定过小,则会造成“断路问题”,即有些样本点无法可达了,整个世界村被划分为互不可达的小部落。
局部线性嵌入LLE
保持邻域内样本之间的线性关系
LLE算法分为两步走,首先第一步根据近邻关系计算出所有样本的邻域重构系数w:
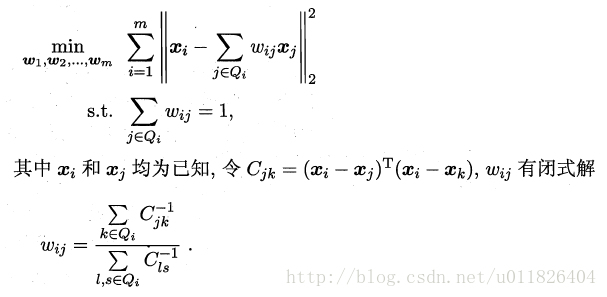
接着根据邻域重构系数不变,去求解低维坐标:
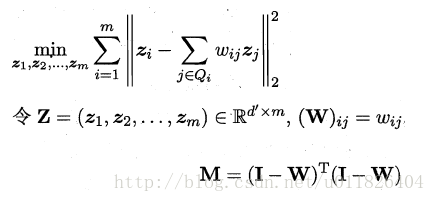
重写为

M特征值分解后最小的d’个特征值对应的特征向量组成Z,LLE算法的具体流程如下图所示:

对于不在
xi
x
i
邻域内的样本
xj
x
j
,无论其如何变化,都不会影响
xi、zi
x
i
、
z
i
度量学习
降维的主要目的是找到一个合适的低维空间,在此空间上进行学习比在原始空间进行学习性能更好。 事实上,每个空间对应了在样本属性上定义的一个距离度量,度量学习就在于寻找这个距离度量。
先要学习出距离度量必须先定义一个合适的距离度量形式。对两个样本xi与xj,它们之间的平方欧式距离为:
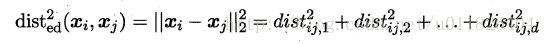
若各个属性重要程度不一样即都有一个权重,则得到加权的平方欧式距离:
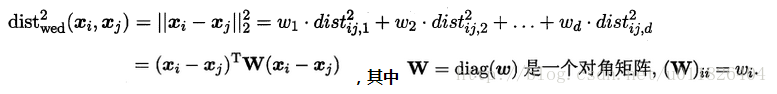
此时各个属性之间都是相互独立无关的(W为对角阵,坐标轴是正交的),但现实中往往会存在属性之间有关联的情形,例如:身高和体重,一般人越高,体重也会重一些,他们之间存在较大的相关性。这样计算距离就不能分属性单独计算,于是就引入经典的马氏距离(Mahalanobis distance):
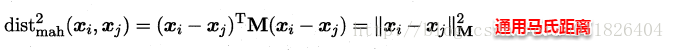
矩阵M也称为“度量矩阵”,为保证距离度量的非负性与对称性,M必须为(半)正定对称矩阵,也就是必有正交基P使用
M=PTP
M
=
P
T
P
成立,这样就为度量学习定义好了距离度量的形式,换句话说:度量学习便是对度量矩阵M进行学习。现在来回想一下前面我们接触的机器学习不难发现:机器学习算法几乎都是在优化目标函数,从而求解目标函数中的参数。
降维是将原高维空间嵌入到一个合适的低维子空间中,接着在低维空间中进行学习任务;度量学习则是试图去学习出一个距离度量来等效降维的效果,两者都是为了解决维数灾难带来的诸多问题。正是因为在降维算法中,低维子空间的维数d’通常都由人为指定,因此我们需要使用一些低开销的学习器来选取合适的d’,使用KNN来确定。
最后
以上就是大方纸鹤最近收集整理的关于降维与度量学习KNN–k近邻学习降维MDS算法主成分分析PCA核化线性降维流形学习度量学习的全部内容,更多相关降维与度量学习KNN–k近邻学习降维MDS算法主成分分析PCA核化线性降维流形学习度量学习内容请搜索靠谱客的其他文章。








发表评论 取消回复