目录
- 背景
- 样本抽取
- 样本处理
- 删除异常数据
- 删除重复记录
- 缺失值处理
- 数据转换
- 漏斗指标分析
- 用户行为数据分析
- 用户价值分析
- 总结
- 完整代码
背景
数据源 阿里巴巴云天池
数据集介绍

数据量

可以看的出来数据量级还是很大的,为了方便分析需要对样本进行抽样
分析的主要方向如下
- 交易漏斗指标分析
- 用户行为指标分析
- 用户价值分析
样本抽取
大数据读取:分块处理
抽取原则:随机选取10000名用户的行为数据
#数据集太大,取10000个用户的行为数据做分析
datalist = []
chunksize = 1000000
chuncks = pd.read_csv('UserBehavior_v1.csv',index_col=False,chunksize=chunksize)
print('chunck start!')
a = time.time()
for chunck in chuncks:
datalist.append(chunck)
b = time.time()
del chuncks,chunck
print('chunck end!',b-a)
data = pd.concat(datalist,ignore_index=True)
del datalist
#随机选取10000名用户
user_list = data['user_id'].unique().tolist()
random.shuffle(user_list)
user_list = [user_list[i] for i in range(10000)]
data = data[data['user_id'].isin(user_list)]
样本处理
删除异常数据
#删除时间不在样本范围内的数据
data = data[(data['time']>=to_timestamp('2017-11-25')//1000)&(data['time']<to_timestamp('2017-12-04')//1000)]
#根据user_id,goods_id删除第一条行为数据不是pv的记录
d_ = data.groupby(['user_id','goods_id'])['time'].min().to_frame(name='d')
data.set_index(['user_id','goods_id'],inplace=True)
data = data.join(d_,on=['user_id','goods_id'],how='left')
data = data.loc[data[(data['time']==data['d'])&(data['behavior']=='pv')].index]
data.reset_index(inplace=True)
del data['d']
删除重复记录
print('删除前:',data.shape[0])
data.drop_duplicates(inplace=True)
print('删除后:',data.shape[0])
data.to_csv('UserBehavior_v1.csv',index=False)
缺失值处理

数据转换
#处理time 转换成字符串日期
def fun_date(s):
t = time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(s))
return pd.Series([t,t[8:10],t[11:13],t[14:16],t[17:]],index=['date','day','hour','minute','second'])
data[['date','day','hour','minute','second']] = data['time'].apply(lambda s:fun_date(s))
data['week'] = data['date'].map(lambda s:datetime.date(int(s[:4]), int(s[5,7]), int(s[8:10]).isocalendar())
data['week'] = data['week'].map(lambda s:s[2])
漏斗指标分析
用户购买流程主要分为:
- 浏览->购买
- 浏览->对商品产生兴趣->购买
浏览到购买过程中商品的转化率:
data_cross = pd.crosstab([data['user_id'],data['goods_id']],data['behavior'])
a = data_cross[((data_cross['cart']+data_cross['fav'])==0) & (data_cross['buy']>0)].shape[0]
b = data_cross.shape[0]
print('直接购买:',a)
print('浏览:',b)
print('转化率:',fun_percent(a/b))

其中,直接购买商品中用户感兴趣的比例
direct_goods_buy = data_cross[((data_cross['cart']+data_cross['fav'])==0)&(data_cross['buy']>0)].reset_index()['goods_id'].nunique()
plt.pie([uninterested_goods_buy,direct_goods_buy-uninterested_goods_buy],labels=['不感兴趣','感兴趣'],autopct='%1.1f%%')
plt.title('直接购买商品中是否是用户感兴趣商品占比')
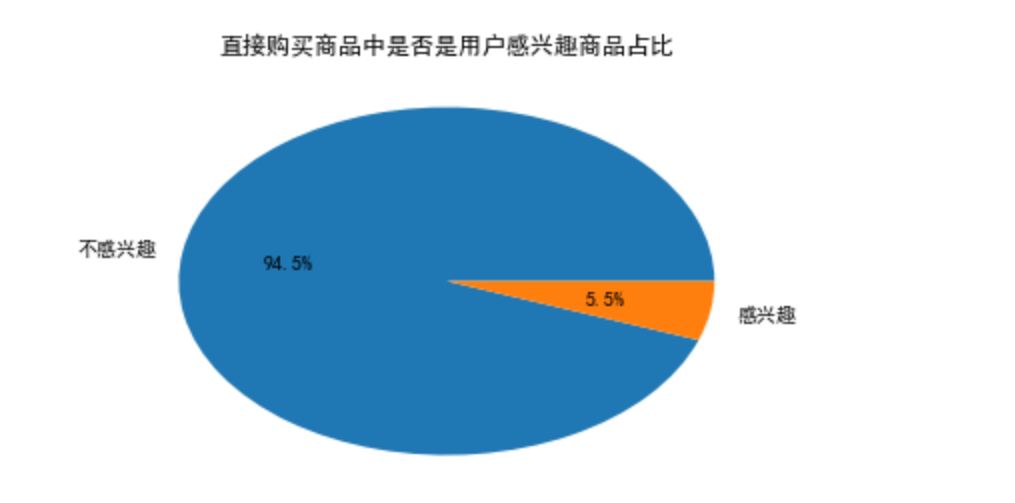
可以看出,用户直接购买的商品中大部分商品在销售中,不需要添加到购物车和收藏中。由此可以看出,精准推荐商品可以简化用户购买路径转化。
再来看看另一种转化情况
#每个环节不去重转化
c = data_cross[(data_cross['cart']+data_cross['fav'])>0].shape[0]
d = data_cross[((data_cross['cart']+data_cross['fav'])>0)&(data_cross['buy']>0)].shape[0]
df_funnel = pd.DataFrame([[b],[c],[d]],columns=['count'])
df_funnel['单一转化率'] = [1]+list(np.array(df_funnel['count'][1:])/np.array(df_funnel['count'][:-1]))
df_funnel['总体转化率'] = [1]+list(np.array(df_funnel['count'][1:])/np.array(df_funnel['count'][0]))
df_funnel['单一转化率'] = df_funnel['单一转化率'].map(fun_percent)
df_funnel['总体转化率'] = df_funnel['总体转化率'].map(fun_percent)
funnel = Funnel("漏斗图", "转化率(%)", width=600, height=400, title_pos='center')
funnel.add("商品交易行环节",
['浏览商品','加入购物车或收藏','购买'],
df_funnel['总体转化率'].map(lambda s:float(s[:-1])),
label_pos="inside",is_label_show=True,
legend_pos='left',legend_orient='vertical')
funnel.render('funnel.html')
df_funnel
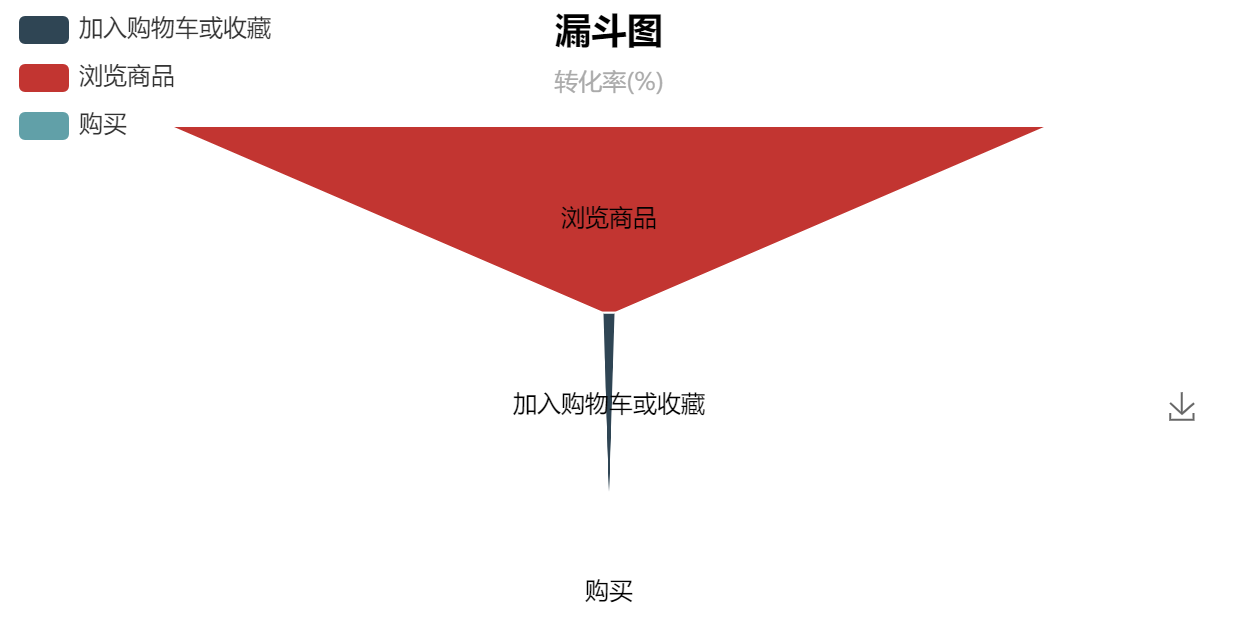

从浏览到加购/收藏的转化极低,由此产生了以下假设:

先来验证第一个猜测
#商品质量偏低,无法满足用户购物需求
#查看商品中用户感兴趣量占比
data['bh'] = data['behavior'].map(lambda s:'cart_fav' if s in ['cart','fav'] else s)
goods_num = data['goods_id'].nunique()
interested_goods = data[data['bh']=='cart_fav']['goods_id'].nunique()
uninterested_goods_buy = data[(data['goods_id'].isin(list(set(data['goods_id'])-set(data[data['bh']=='cart_fav']['goods_id']))))&(data['bh']=='buy')]['goods_id'].nunique()
plt.pie([interested_goods,goods_num-interested_goods-uninterested_goods_buy,uninterested_goods_buy],
labels=['感兴趣','不感兴趣不购买','不感兴趣直接购买'],autopct='%1.1f%%')
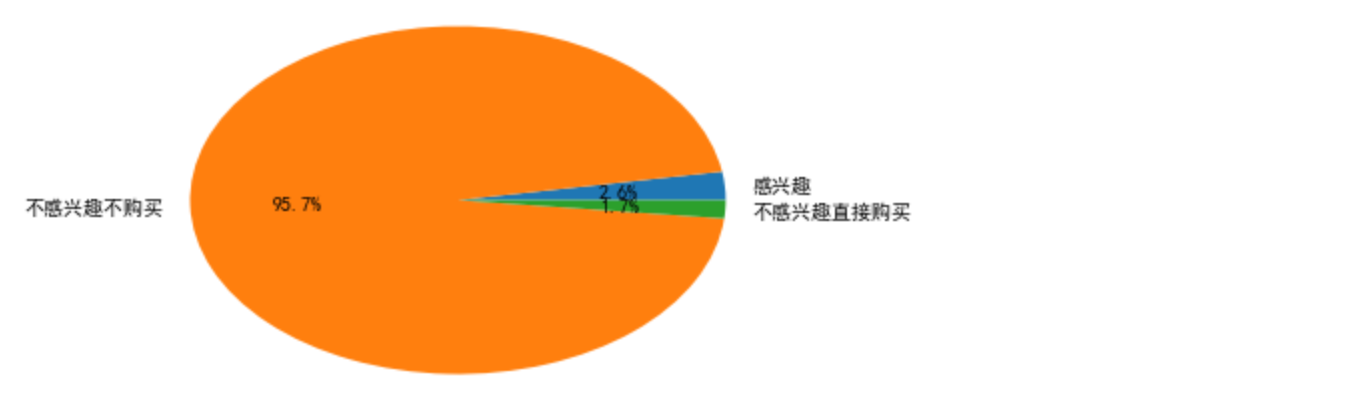
由此可以看出,有95.7%的商品用户不感兴趣也不想购买。商品的购买率极低
考虑到同品类商品内部之间会存在一个竞品关系,再看一下商品品类中的购买率情况
item_num = data['item_id'].nunique()
interested_item = data[data['bh']=='cart_fav']['item_id'].nunique()
uninterested_item_buy = data[(data['item_id'].isin(list(set(data['item_id'])-set(data[data['bh']=='cart_fav']['item_id']))))&(data['bh']=='buy')]['item_id'].nunique()
plt.pie([interested_item,item_num-interested_item-uninterested_item_buy,uninterested_item_buy],
labels=['感兴趣','不感兴趣不购买','不感兴趣直接购买'],autopct='%1.1f%%')
plt.title('商品品类中用户是否感兴趣占比')
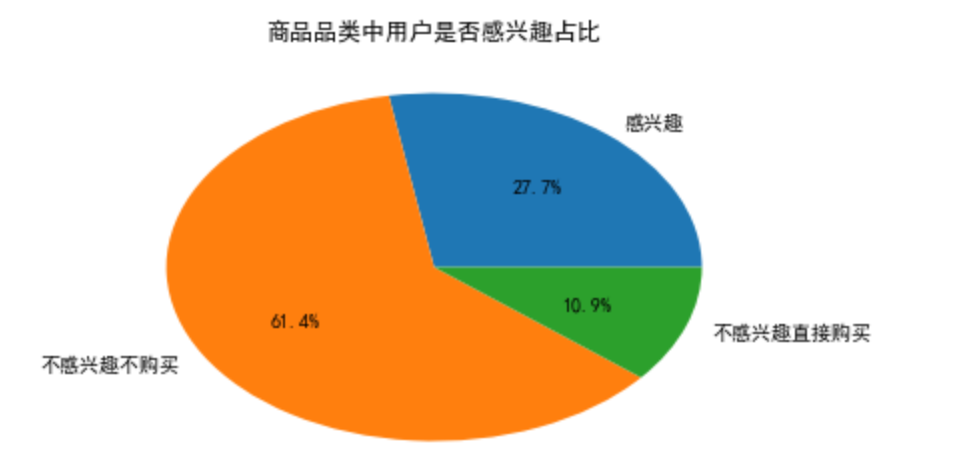
61.4%的商品品类是用户不感兴趣也不想购买的,可能是因为
- 上架商品品类比较冷门,需求量低
- 上架商品不是当季畅销
建议:要审核商品质量,考虑是否下架冷门商品,节省流量资源
接下来,验证第二个假设
#平台推荐商品与用户需求不一致
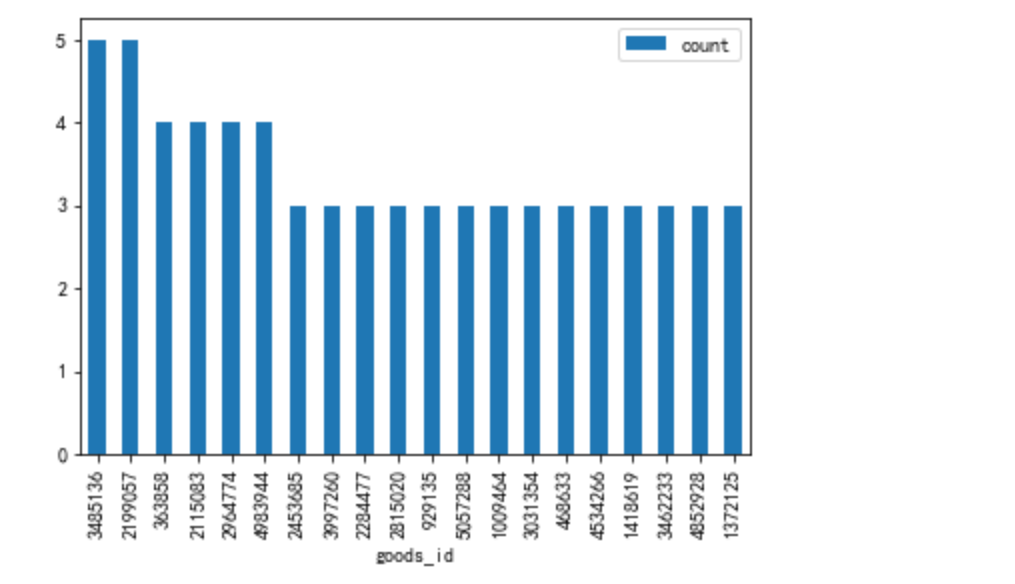
#购买用户数最多的top20商品
topbuy_goods = data[data['behavior']=='buy'].groupby('goods_id')['user_id'].nunique().to_frame(name='count').sort_values('count',ascending=False)
topbuy_goods[:20].plot.bar()
#访问用户数最多的top20商品
toppv_goods = data[data['behavior']=='pv'].groupby('goods_id')['user_id'].nunique().to_frame(name='count').sort_values('count',ascending=False)
toppv_goods[:20].plot.bar()
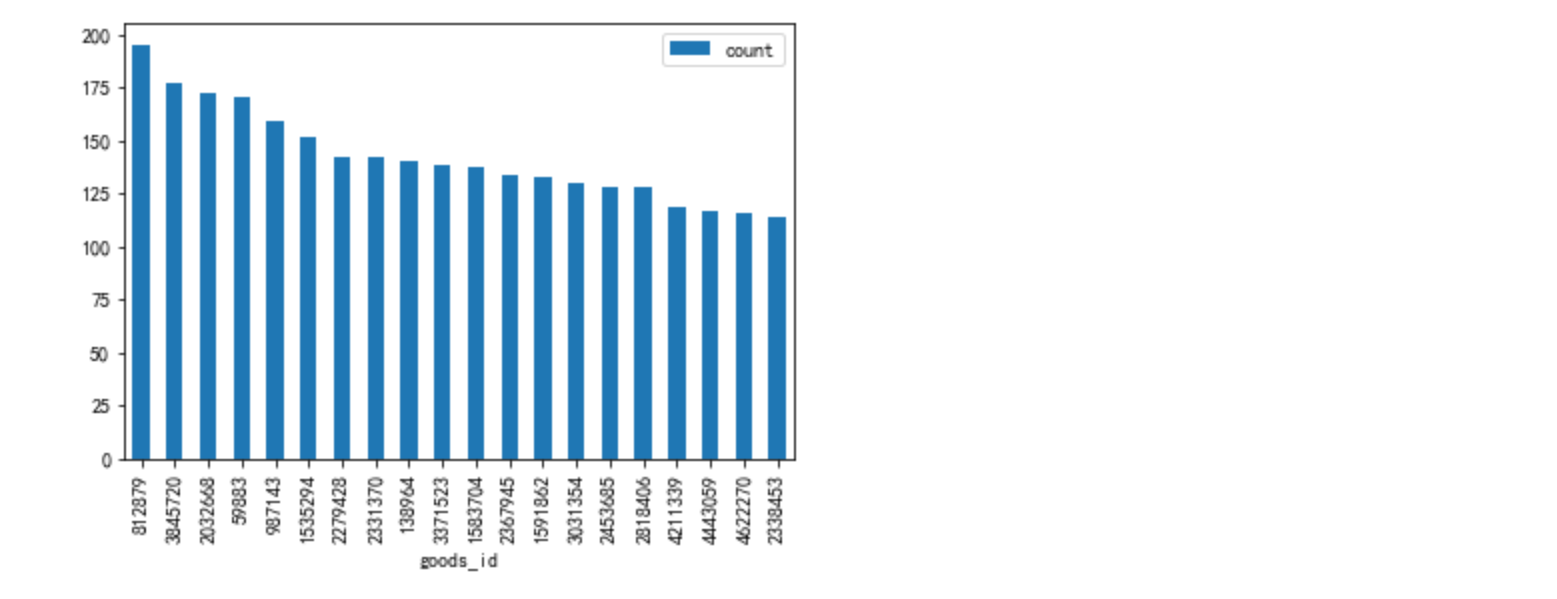
重复商品数为2
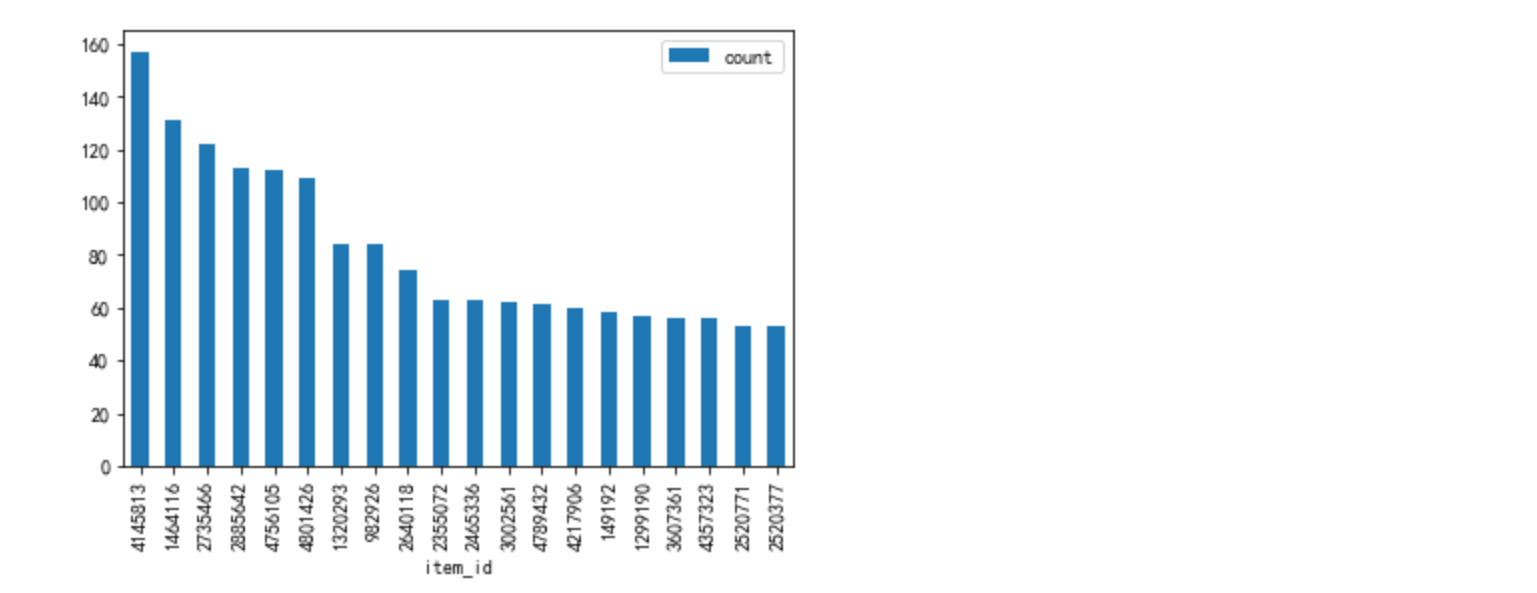
再看一下商品品类
#平台推荐商品与用户需求不一致
#购买用户数最多的top20商品品类
topbuy_item = data[data['behavior']=='buy'].groupby('item_id')['user_id'].nunique().to_frame(name='count').sort_values('count',ascending=False)
topbuy_item[:20].plot.bar()
#访问用户数最多的top20商品品类
toppv_item = data[data['behavior']=='pv'].groupby('item_id')['user_id'].nunique().to_frame(name='count').sort_values('count',ascending=False)
toppv_item[:20].plot.bar()
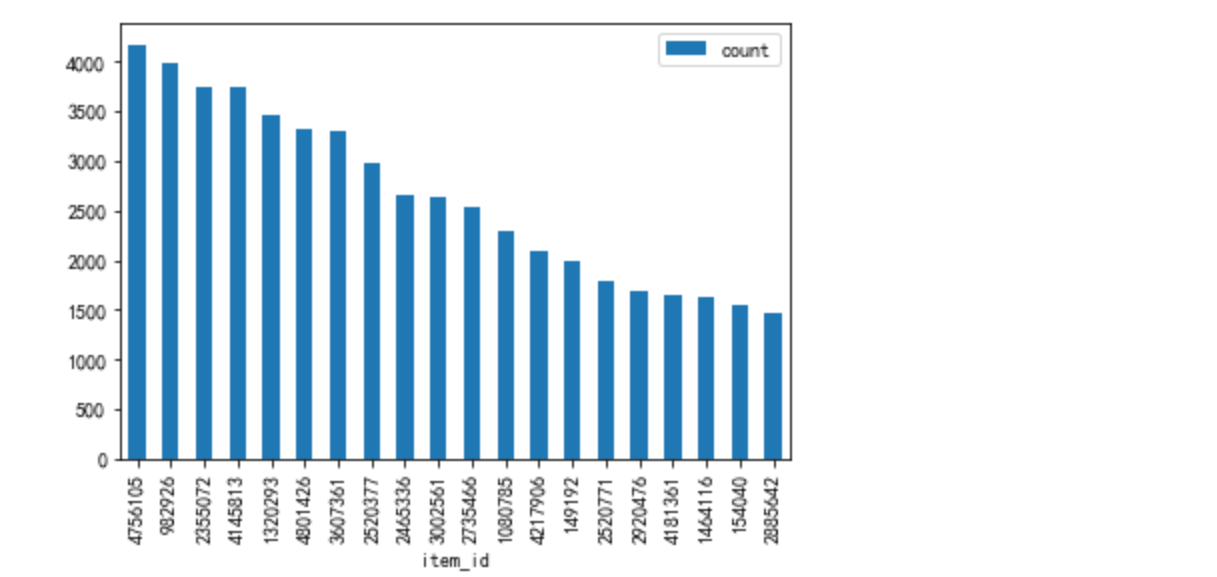
得出结论:
在商品品类推荐上,有16个重复,商品推荐,重复数为仅为2。
商品推荐算法存在很大漏洞,没有把握住用户对商品的偏爱影响因素,造成流量资源的浪费
从用户购买的商品品类和商品上看,用户对商品的购买还是比较集中的,可以考虑加大该品类商品的推荐
#用户感兴趣商品中,仅加购、仅收藏、加购+收藏占比,以及到购买的转化率
l = [[data_cross[(data_cross['cart']>0)&(data_cross['fav']==0)].shape[0],
data_cross[(data_cross['cart']>0)&(data_cross['fav']==0)&(data_cross['buy']>0)].shape[0]],
[data_cross[(data_cross['cart']==0)&(data_cross['fav']>0)].shape[0],
data_cross[(data_cross['cart']==0)&(data_cross['fav']>0)&(data_cross['buy']>0)].shape[0]],
[data_cross[(data_cross['cart']>0)&(data_cross['fav']>0)].shape[0],
data_cross[(data_cross['cart']>0)&(data_cross['fav']>0)&(data_cross['buy']>0)].shape[0]]]
df_ = pd.DataFrame(l,columns=['count','buy_count'],index=['仅加购','仅收藏','加购+收藏'])
df_['rate'] = df_['buy_count']/df_['count']
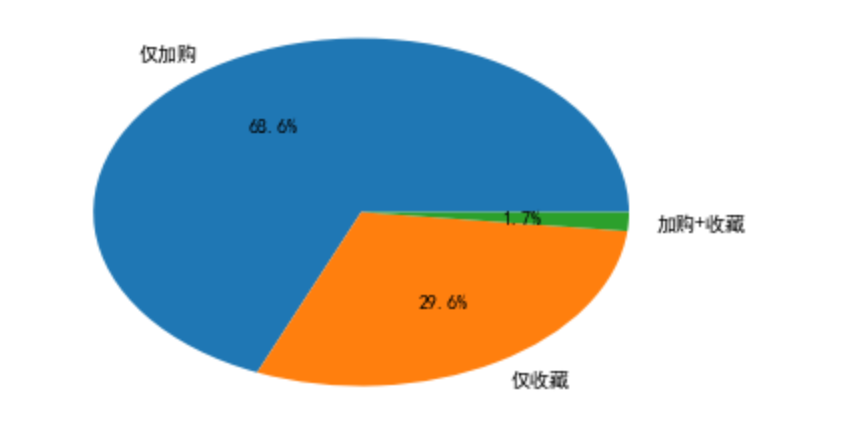
顾客浏览转化到加购的用户偏多,并且加购转化到购买的用户转化率比较大
加购和收藏对购买的转化有叠加效应
总的来说,对购买转化的影响程度上:加购+收藏>仅加购>仅收藏
用户行为数据分析
(1)流量指标:pv,uv,日活跃户数(定义发生购买行为为活跃用户)
#pv
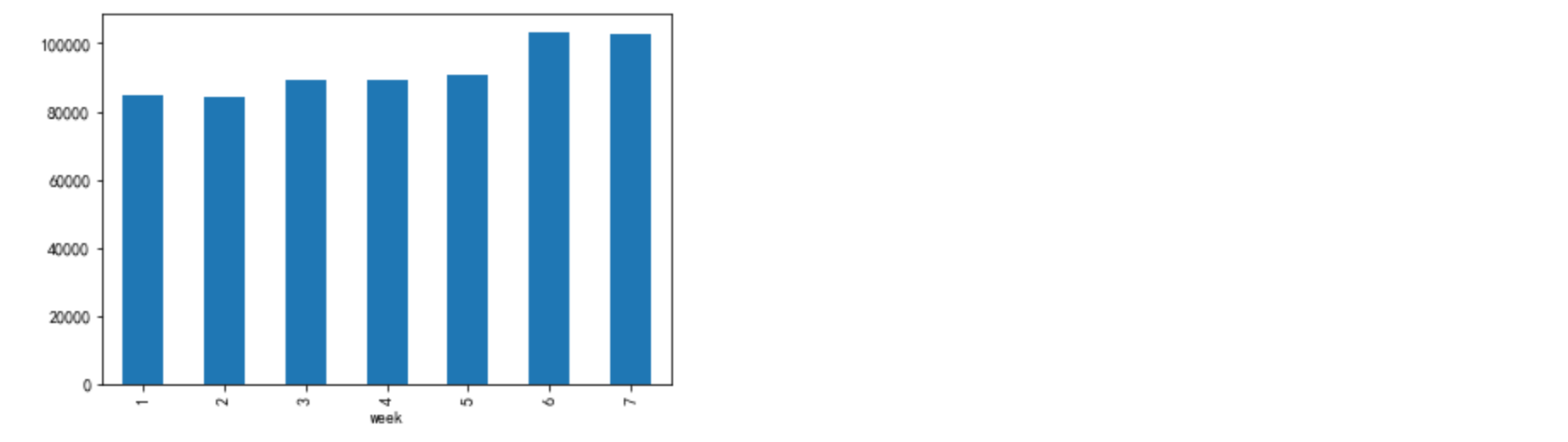
df_ = data[data['bh']=='pv'].groupby(['day','week']).count().reset_index().groupby('week')['user_id'].mean()
df_.plot.bar()
#uv
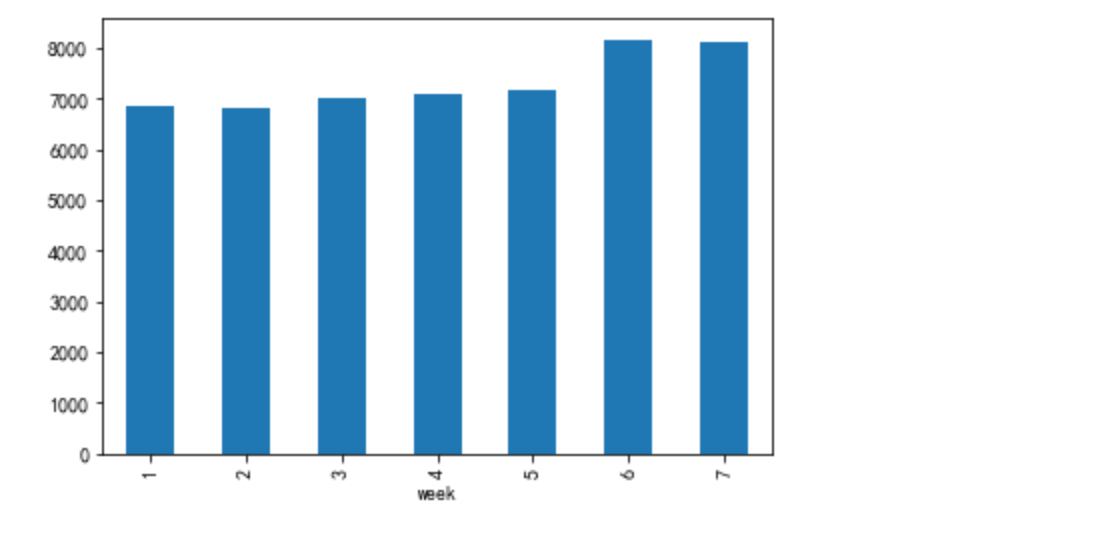
df_ = data[data['bh']=='pv'].groupby(['day','week'])['user_id'].nunique().reset_index().groupby('week')['user_id'].mean()
df_.plot.bar()
#日活用户数
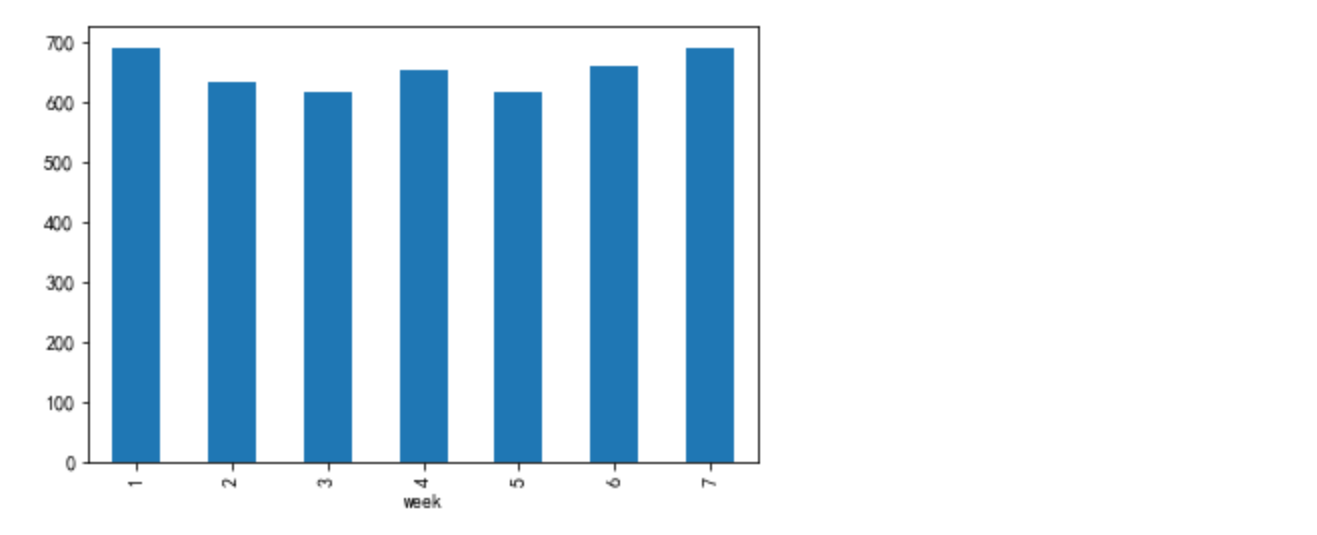
df_ = data[data['bh']=='buy'].groupby(['day','week'])['user_id'].nunique().reset_index().groupby('week')['user_id'].mean()
df_.plot.bar()
#总体活跃用户占比
plt.pie([data['user_id'].nunique(),data[data['bh']=='buy']['user_id'].nunique()],labels=['购买','未购买'],autopct='%1.1f%%')
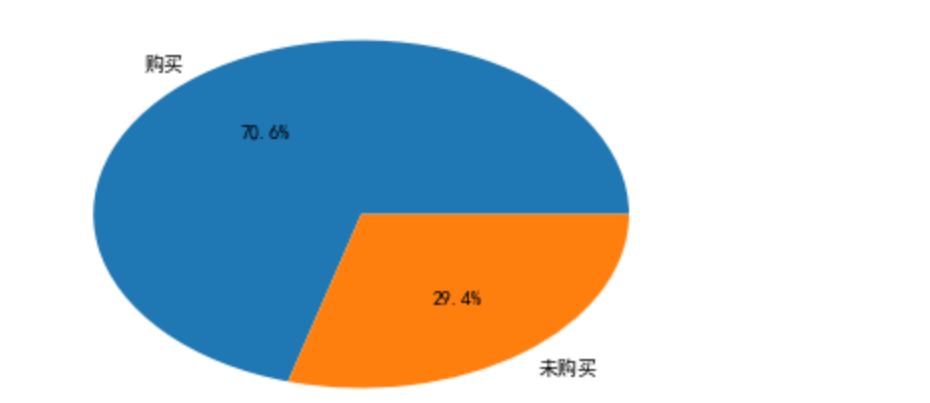
得出结论:到了周末的时候,访问用户数购买用户数都有所提高
周一、周四购买用户数有提高的原因可能是临近双十二,预售活动开启
(2)按照天、时间段维度分析用户活跃时间
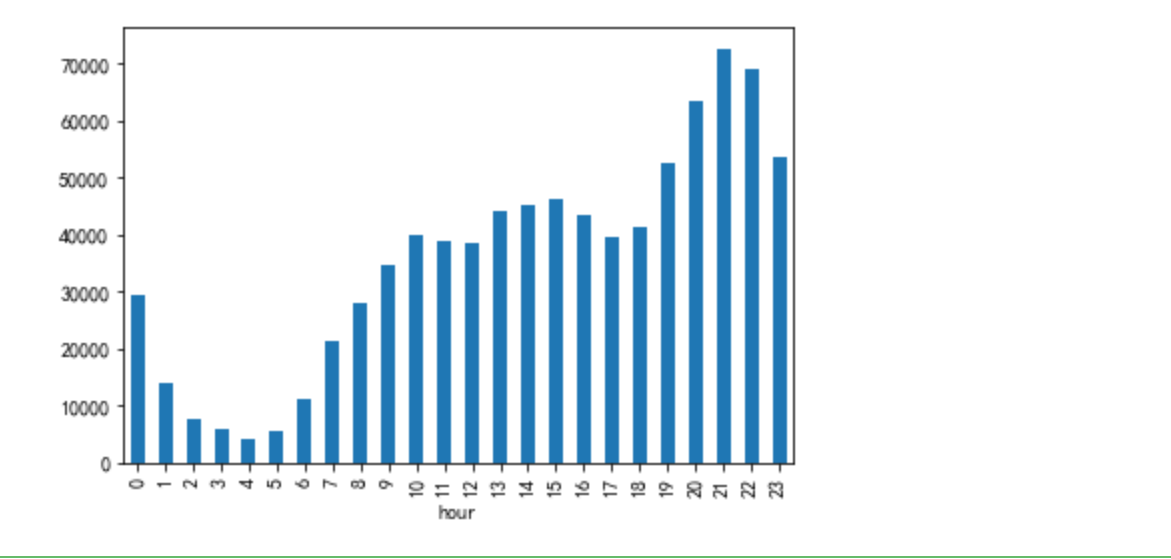
#pv
df_ = data[data['bh']=='pv'].groupby(['hour'])['user_id'].count()
df_.plot.bar()
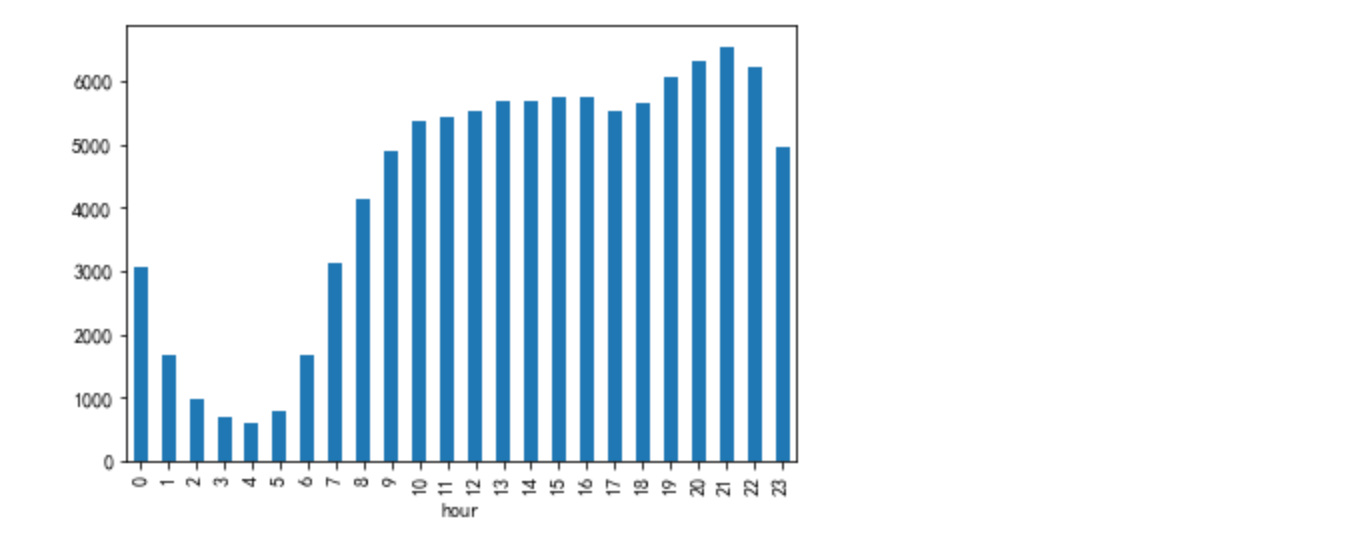
#uv
df_ = data[data['bh']=='pv'].groupby(['hour'])['user_id'].nunique()
df_.plot.bar()
#日活用户数
df_ = data[data['bh']=='buy'].groupby(['hour'])['user_id'].nunique()
df_.plot.bar()
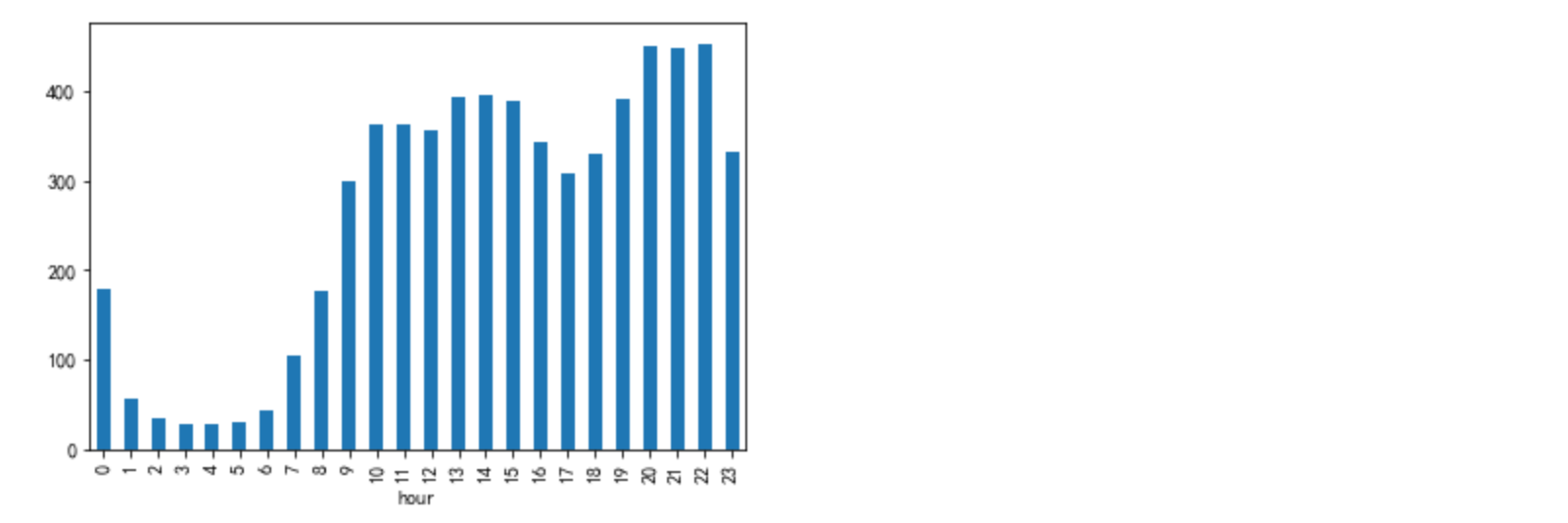
一天当中,1:00至7:00睡眠时间,用户数很少;19:00~23:00是用户活跃时间段
7:00至16:00 工作时间,pv明显有所下降,uv下降幅度比较小,可能大家上班都会刷刷淘宝,但是浏览页面不怎么频繁
用户购买发生在10:0016:00,20:0022:00的比较多
(3) pv次数与是否购买的关系
#pv次数与用户购买关系
df_ = data[data['behavior']=='pv'].groupby(['user_id','goods_id'])['bh'].count().to_frame('pv')
df__ = data[data['behavior']=='buy'].groupby(['user_id','goods_id'])['bh'].count().to_frame('buy')
df_ = df_.join(df__)
df_['buy'] = df_['buy'].map(lambda s:1 if s >0 else 0)
df = df_.groupby(['pv'])['buy'].count().to_frame('count')
df['buy'] = df_.groupby(['pv'])['buy'].sum()
df.plot.bar()
df.reset_index(inplace = True)
df['pv'] = df['pv'].map(lambda s: 5 if s>5 else s)
sns.lineplot(x=df['pv'],y=df['buy']/df['count'])
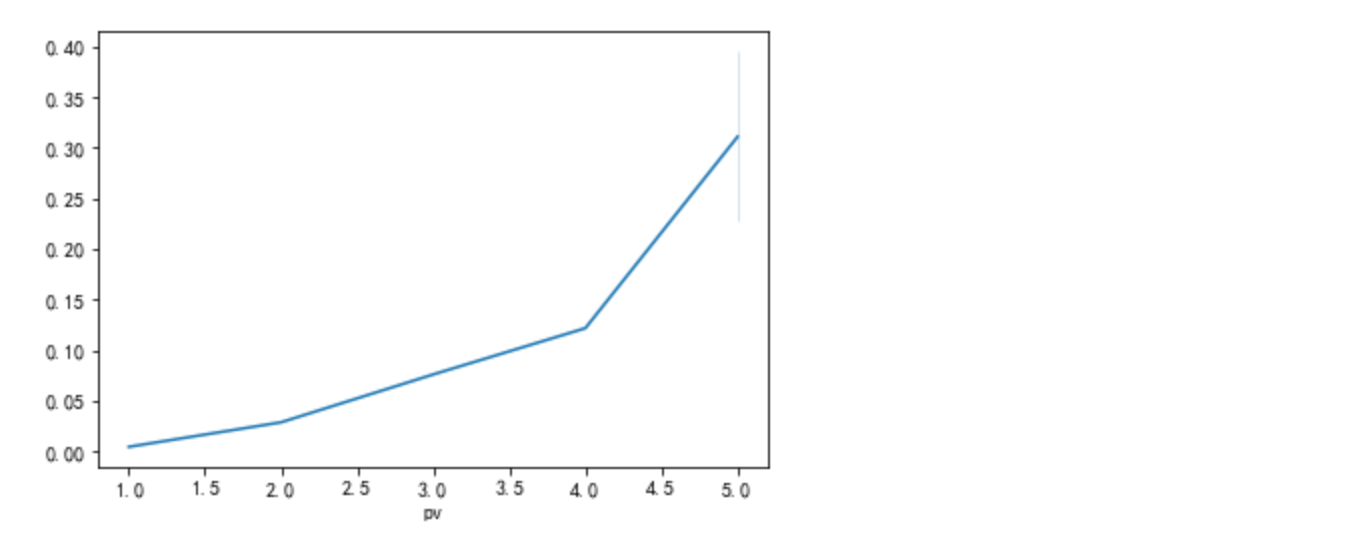
浏览次数越多,购买的几率越大
用户价值分析
(1)复购率
df_ = data[(data['bh']=='buy')&(data['user_id'].isin(data[data['day']==25]['user_id']))&(data['day']!=3)].groupby(['user_id'])['goods_id'].count().to_frame(name='count')
plt.pie([df_[df_['count']>2].shape[0],df_[df_['count']==1].shape[0]],labels=['复购','只够买一次'],autopct='%1.1f%%')
在这里插入图片描述
(2)RFM模型对用户分层
#RFM对用户分层
#以2017-12-04日为观察点,计算R值
df = pd.DataFrame()
df['user_id'] = data['user_id'].unique()
df_ = data[data['bh']=='buy']
df_['day'] = df_['day'].map({25:9,26:8,27:7,28:6,29:5,30:4,1:3,2:2,3:1})
df_ = df_.groupby('user_id').agg({'day':min,'goods_id':'count'}).reset_index()
df = pd.merge(df,df_,how='left',on='user_id')
df.fillna(0,inplace=True)
df['day'] = df['day'].map(lambda s:int(s>=df['day'].mean()))
df['goods_id'] = df['goods_id'].map(lambda s:int(s>=df['goods_id'].mean()))
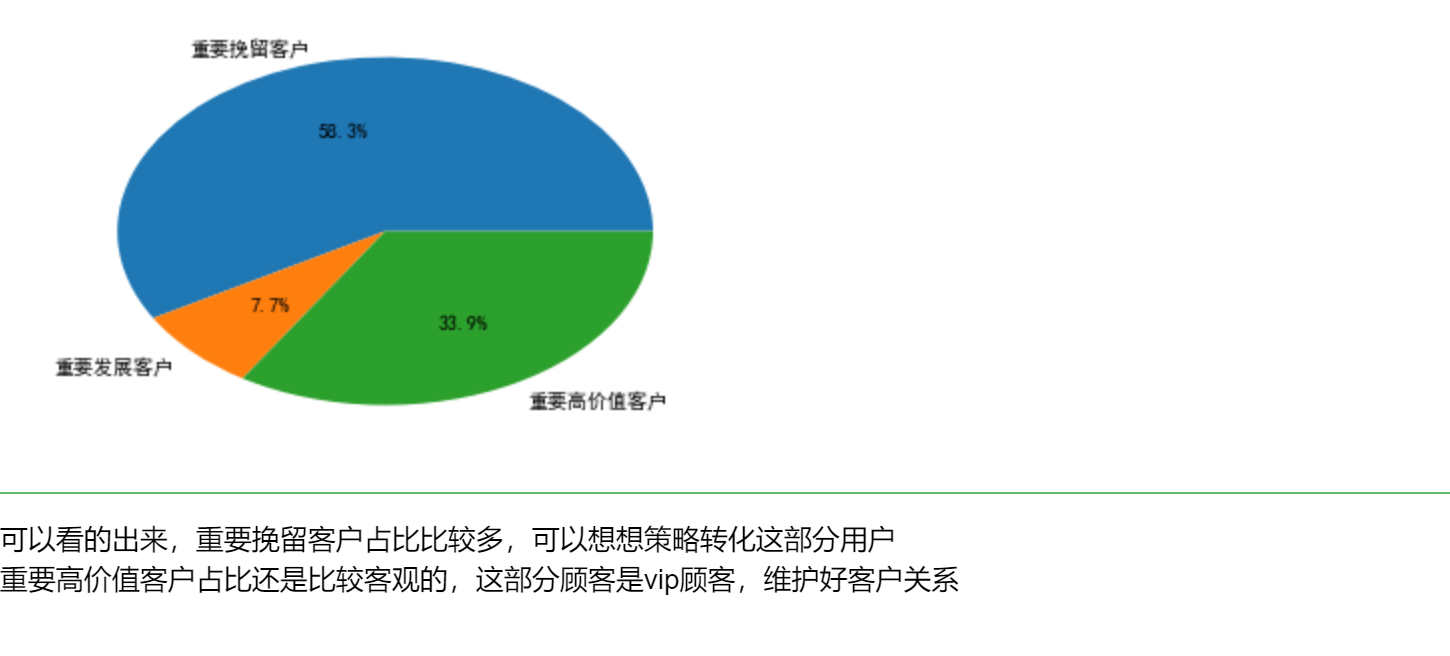
df = df.groupby(['day','goods_id'])['user_id'].count()
plt.pie(df,labels=['重要挽留客户','重要发展客户','重要高价值客户'],autopct='%1.1f%%')
总结

完整代码
github
最后
以上就是着急龙猫最近收集整理的关于淘宝用户行为分析+python可视化背景样本抽取样本处理漏斗指标分析用户行为数据分析用户价值分析总结完整代码的全部内容,更多相关淘宝用户行为分析+python可视化背景样本抽取样本处理漏斗指标分析用户行为数据分析用户价值分析总结完整代码内容请搜索靠谱客的其他文章。








发表评论 取消回复