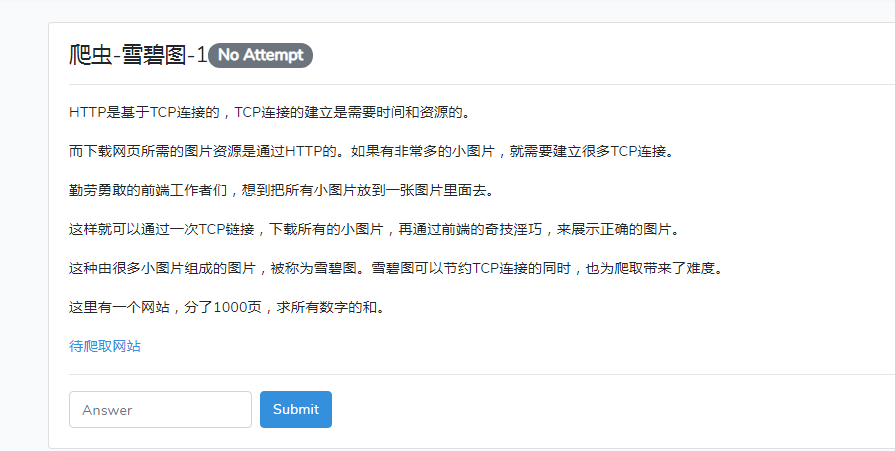
上图就是这次爬虫练习的介绍了。下面可以直接开始了,因为知道是全部都是图片拼成,我们可以直接看一下谷歌浏览器的开发者工具。
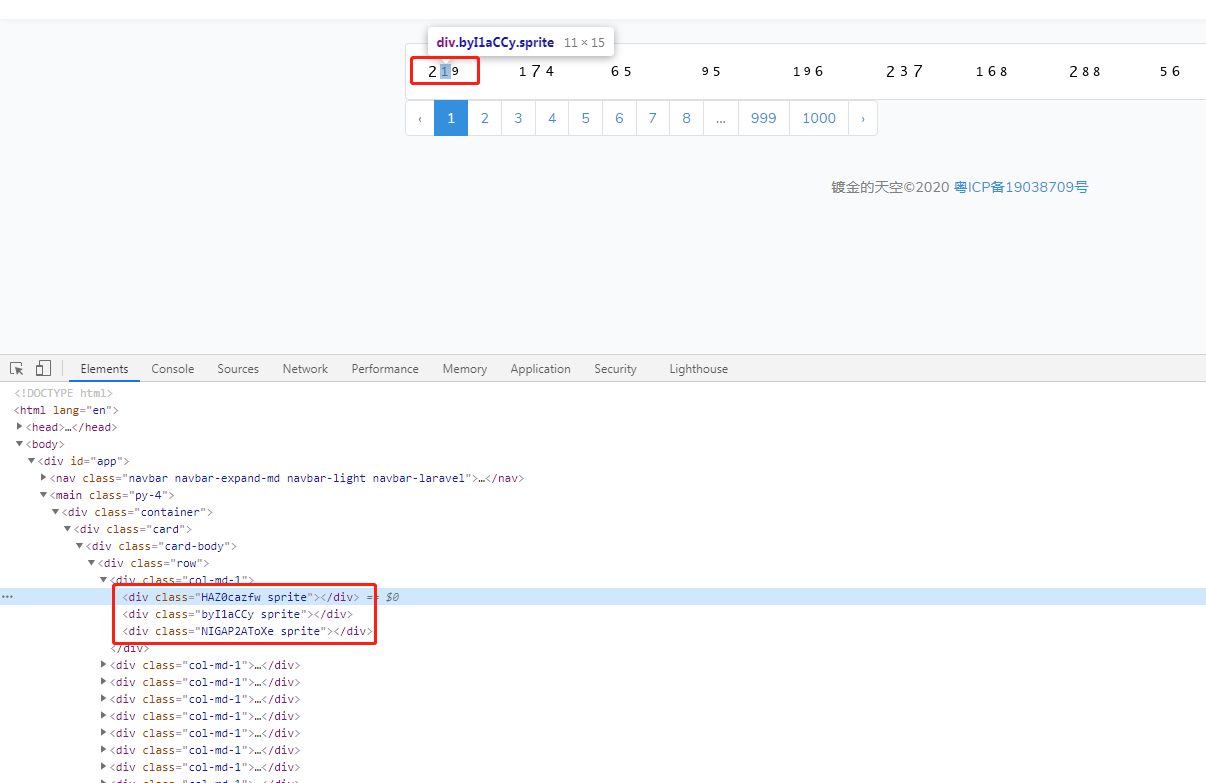
看到真的什么都没有啊,没有数字,只有一个class的属性,因为我们前提是知道是有图片组成的, 所以我们可以看下他的css的组成都是什么意思。
在这里我的想法是看css的样式,可以通过浏览器对css的操作大概看下对网页的影响。
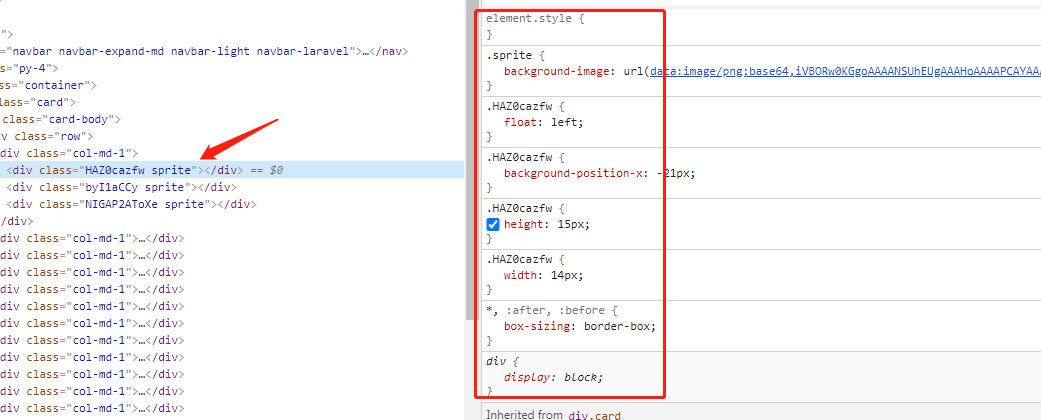
邮编可以直接看到这个class当前的属性,在我吧background-position-x这个样式的对勾取消之后,可以看到数字2变成了数字0,同时我吧width的值修改一下,改的稍微大一点,就会看到数字会多出来,其实只是图片显示的多了而已。
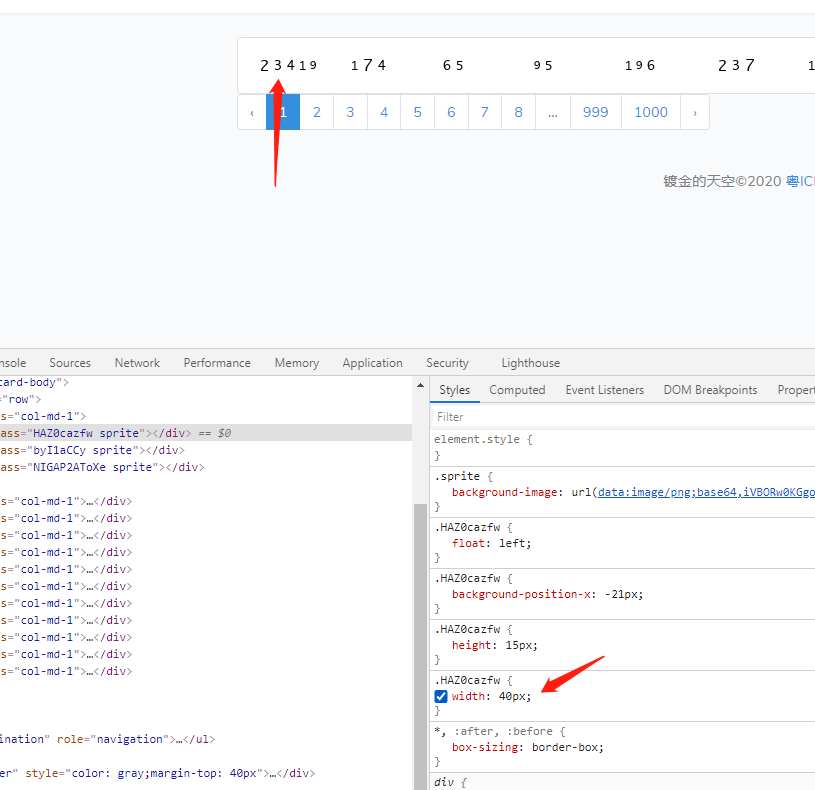
还有一个样式的属性需要注意一下,就是background-image,这个标签的说明是设置body的背景图像。把鼠标放在链接处可以看到图片的样子。
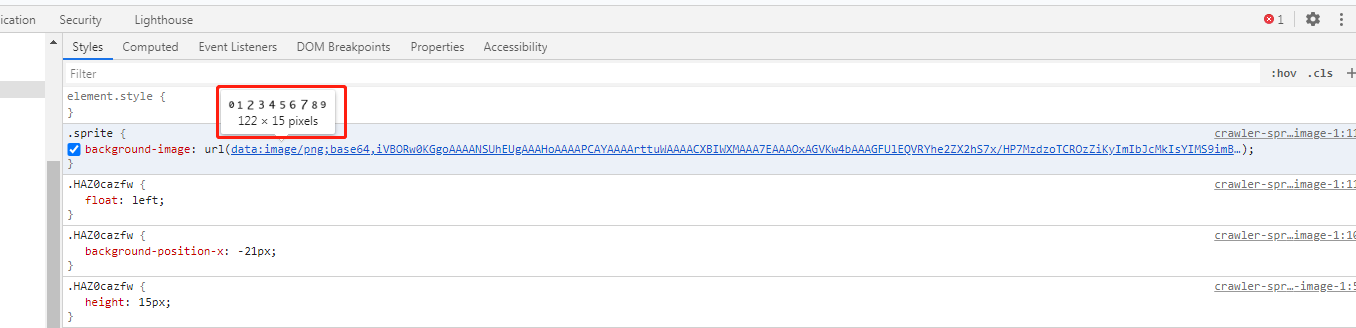
可以看到是一个122*15像素的图片,这样的话我们基本可以确定,这张图片从左向右第21个像素开始,截取一个宽为11像素的图片,刚刚好显示为数字2、
这样我们基本可以确定,主要是background-position-x这个属性来控制,同时在这个页面的源码内有一段这样的style的代码。

可以直接搜索一下这个class的属性,然后去看下是否和我们想要得到的一致。结果肯定是没有问题的啊。这个地方可以通过正则匹配出来。
这样我们接下来可以编写代码了!!
因为每次获取的base64的编码图片大小是不一样的,所以需要每次都去解析,然后获取图片的宽度,一共是10个数字,可以除以10 得到每个数字的宽度,然后去定位当前页面下的所有的class的属性。得到这个class属性的css对应的像素。就可以取到当前位置对应的实际数字了。
首先是讲base64转换为图片,并获取图片的宽度。
def get_img_width(response):
base_img = re.findall(r'data:image/png;base64,(.*?)"', response)
base_img = base_img[0]
imgdata = base64.b64decode(base_img)
with open('./tu.jpg', 'wb') as f:
f.write(imgdata)
img = Image.open('./tu.jpg')
width, height = img.size
width = width / 10
return width
然后去获取本页的所有的理想数字的class
# 我在这里用了xpath去提取。这句定位的是数字外层的div。
list_all = xpath_html.xpath('//*[@id="app"]/main/div[1]/div/div/div/div')
# 然后通过语句在去提取每一个数字的class属性。
for j in list_all:
list_num = j.xpath('./div/@class') # HAZ0cazfw sprite
# 之后得到第一个class的属性,然后去源码页面寻找偏移位
excursion = re.findall(f'{获取到的class的第一个属性} . background-position-x:-(d+)px', html)
# 用偏移位去对应单个的数字
number = round(int(excursion) / width) # 这里的width是单个图片的width,按照四舍五入去计算的。
# 因为获取到的number现在还是单个的数字,要吧当前div下的数字以字符串的形式拼接,才知道到底是几位数,
# 然后去相加就是本页所有数字的和了。
不过这里有个问题,我已经把所有的和求完了,但是去填写的时候确提示不正确。。。。尴尬。可以我随机抽取了几个页面去查看获取的数字,还都是一样的。这我就很为难了!!!后来我吧所有的数字都保存在表格内,然后继续抽查了十几个页面,还是没有错误,但是还是提示总和不对、、、
在经过了老长时间之后,发现有问题,就是四舍五入有时候是不对的。极少数情况下四舍五入会大一位数,比如160会算成150。但是不能保证1000页都不犯错。所以后续我改成了和他的css样式的width去判断,当两次计算的结果相差不是1时或者不是0时,就取第二次获取到的减去1。这样只是能加强一下对数据正确性的校验,但是感觉方法并不是很好。
最后的最后 因为一天提交多次答案 被禁止提交了。但是思路最起码在这里了、。。。。
最后
以上就是干净早晨最近收集整理的关于GlidedSky爬虫雪碧图-1的全部内容,更多相关GlidedSky爬虫雪碧图-1内容请搜索靠谱客的其他文章。








发表评论 取消回复