一.抓取页面
url=https://www.xuexi.cn/f997e76a890b0e5a053c57b19f468436/018d244441062d8916dd472a4c6a0a0b.html
1..首先通过分析页面会发现该页面中的新闻数据都是动态加载出来的,并且通过抓包工具抓取数据可以发现动态数据也不是ajax请求获取的动态数据(因为没有捕获到ajax请求的数据包),那么只剩下一种可能,该动态数据是js动态生成的。
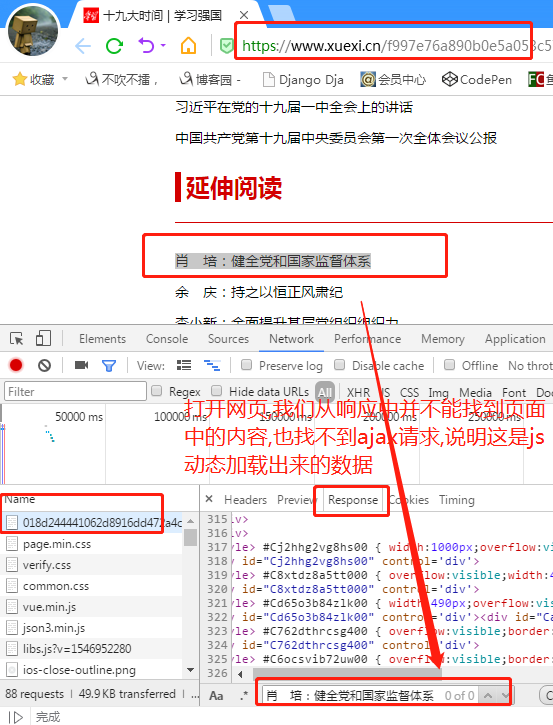
2.通过抓包工具查找到底数据是由哪个js请求产生的动态数据:打开抓包工具,然后对首页url(第一行需求中的url)发起请求,捕获所有的请求数据包。
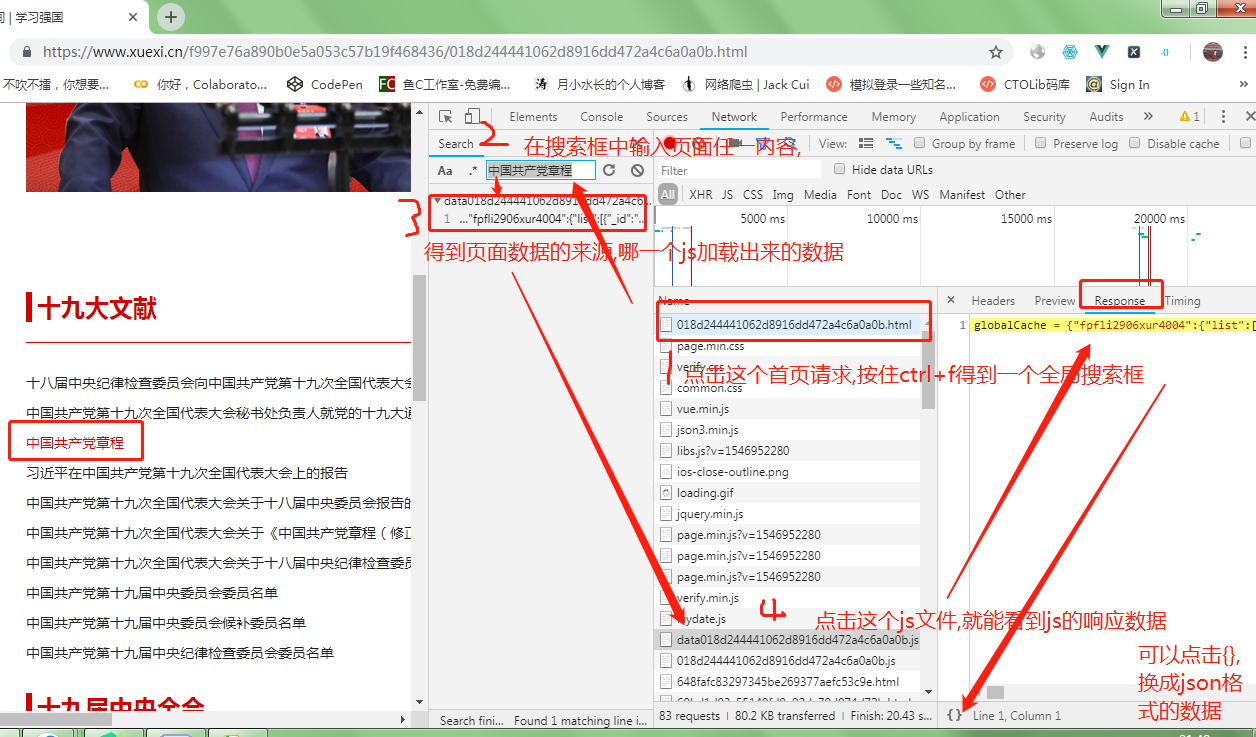
3.分析js数据包响应回来的数据:
该响应数据对应的url可以在抓包工具对应的该数据包的header选项卡中获取。
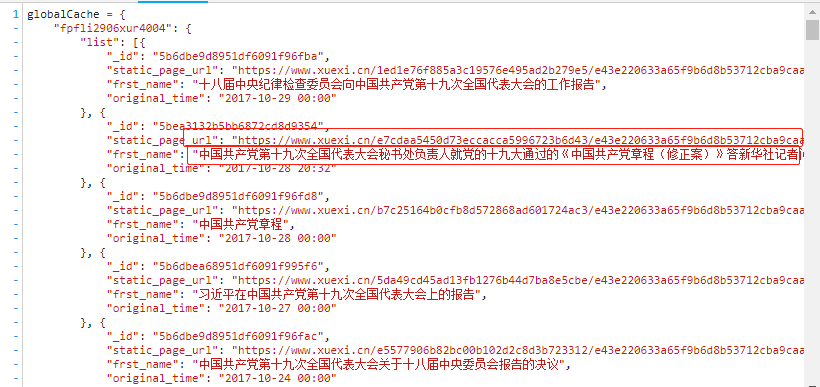
获取url后,对其发起请求即可获取上图中选中的相应数据,该响应数据类型为
application/javascript类型,所以可以将获取的响应数据通过正则提取出最外层大括号中的数据,
然后使用json.loads将其转为字典类型,然后逐步解析出数据中所有新闻详情页的url即可。
4.获取详情页
- 获取详情页中对应的新闻详情数据:对详情页发起请求后,会发现详情页的新闻数据也是动态加载出来的,
因此还是跟上述步骤一样,在抓包工具中对详情页中的局部数据进行搜索,定位到指定的js数据包
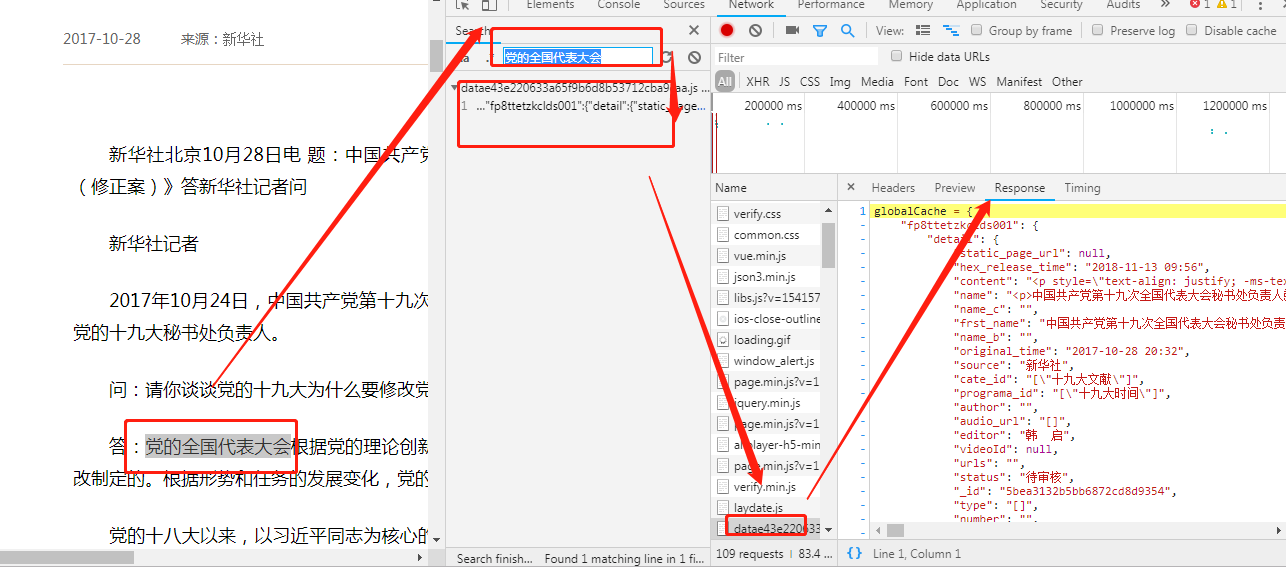
该js数据包的url为:
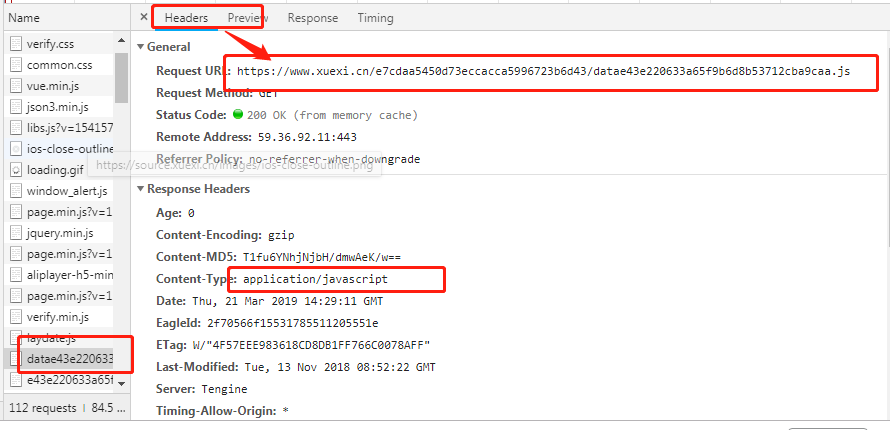
详情页url,获取后,即可请求到该数据包对应的响应数据了,该相应数据中就包含了对应新闻详情数据了。
注意,该响应数据的类型同样为application/javascript,所以数据解析同上!
5.总结发现:
分析首页中所有新闻的详情页url和新闻详情数据对应的js数据包的url之间的关联:
- 首页中某一新闻详情页的url:https://www.xuexi.cn/1ed1e76f885a3c19576e495ad2b279e5/e43e220633a65f9b6d8b53712cba9caa.html
- 该新闻详情数据对应的js数据包的url:https://www.xuexi.cn/1ed1e76f885a3c19576e495ad2b279e5/datae43e220633a65f9b6d8b53712cba9caa.js
- 所有的新闻详情对应的js数据包的粉色选中部分都是一样的只是红色部分各自不同,但是红色部分却和该新闻详情页的url中的红色部分是相同的!!!新闻详情页的url是可以在上述过程中解析出来的。因此现在就可以批量产生出详情数据对应js数据包的url的,然后批量进行数据请求,获取响应数据,然后对响应数据进行解析即可完成最终的需求!
二.关于该网址的另一个子网页
url=https://www.xuexi.cn/261c9a142ef8e6375ed554815a26d585/f2d8ff735982530b7a8c9bb90fa99f68.html
1. 分析发现他的代码不是js动态加载,而是ajax请求得到的一个json文件
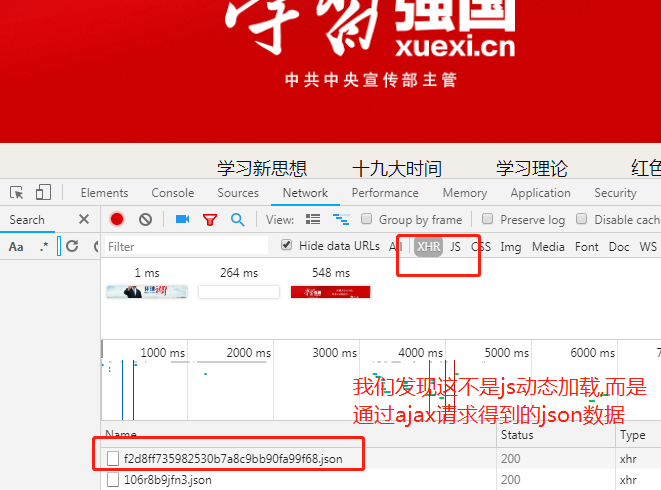
2.再看清一下他的请求头
ajax发起的一个get请求
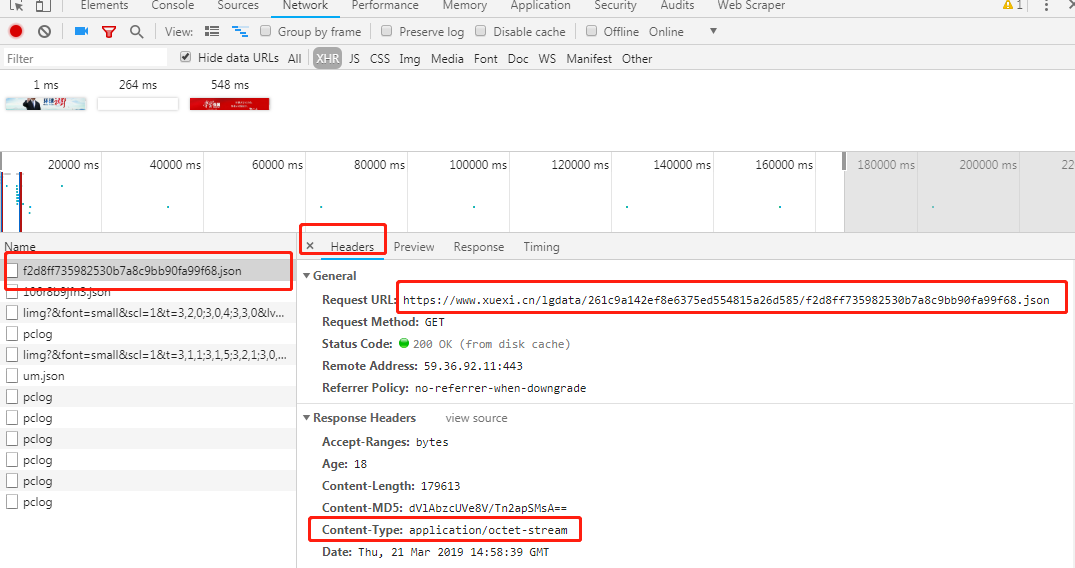
看了一下contentype:
真尼玛的啃爹.老子不认识你啊,怎么解?不知道,先睡觉去
最近有学习了一个新的库,jsonpath,感觉好用,解析这个网站刚刚好哦,只需要返回的是json格式就行
#!/usr/bin/env python # -*- coding: utf-8 -*- #author tom import requests from jsonpath import jsonpath import json import pymongo
#抓取 def get_url(url): info_list=[] data_dic=requests.get(url=url,headers=headers).json() print(type(data_dic)) link_list=jsonpath(data_dic,"$..list..link") text_list=jsonpath(data_dic,"$..list..text") for (text,link) in zip(text_list,link_list): dic={ 'text':text, 'link':link } info_list.append(dic)
save(dic)
#保存到mongodb,其实这样并不好
#最好是采集完数据再一次性写入,对数据库负担才不大,还没想好,怎么弄
#保存数据源函数 def save(dic): # 连接数据库 #指定数据库 client = pymongo.MongoClient(host='127.0.0.1', port=27017) db=client.test collection=db.xuexi collection.save(dic) if __name__ == '__main__': url = 'https://www.xuexi.cn/lgdata/261c9a142ef8e6375ed554815a26d585/f2d8ff735982530b7a8c9bb90fa99f68.json' headers ={'user-agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0'} get_url(url)
转载于:https://www.cnblogs.com/tjp40922/p/10574965.html
最后
以上就是害怕缘分最近收集整理的关于关于抓取js加载出来的内容抓取一.抓取页面 二.关于该网址的另一个子网页的全部内容,更多相关关于抓取js加载出来内容请搜索靠谱客的其他文章。








发表评论 取消回复