相关文章:
【一】MADDPG-单智能体|多智能体总结(理论、算法)
【二】MADDPG多智能体深度强化学习算法算法实现(parl)--【追逐游戏复现】
常见多智能体强化学习仿真环境介绍【一】{推荐收藏,真的牛}
多智能体强化学习算法【一】【MAPPO、MADDPG、QMIX】
多智能体强化学习算法【二】【MADDPG、QMIX、MAPPO】
多智能体强化学习算法【三】【QMIX、MADDPG、MAPPO】
近两年,多智能体强化学习(MARL)的研究日趋火热,和single RL相比,MA问题显然更加复杂 (e.g. non-stationary, credit assignment, communication etc.),那么我们其实就更迫切的需要一些对应的benchmark环境来支撑我们的算法研究,接下来的介绍主要由简单到复杂的顺序:
1. Multi-agent Reinforcement Learning 环境:
链接: https://github.com/Bigpig4396/M
这里边也是提供了多个基于python的grid world小环境,同学们可以找到自己合适的环境进行仿真验证。渲染场景如下:
2. Particle 环境:
Link:https://github.com/openai/multiagent-particle-envs
论文复现链接:https://blog.csdn.net/sinat_39620217/article/details/115299073
简称小球环境,也是MADDPG用的环境,。 在这个环境涵盖了ma里的竞争/协作/场景,你可以根据你的需要设置agent的数量,选择他们要完成的任务,比如合作进行相互抓捕,碰撞等,你也可以继承某一个环境来改写自己的任务。状态信息主要包括agent坐标/方向/速度等,这些小球的的原始动作空间是连续型的,不过在类属性里有个可以强制进行离散的设置,可以把它打开以后小球的动作就可以被离散为几个方向的移动了。此外,在这个环境中,小球之间的碰撞都都是模拟刚体的实际碰撞,通过计算动量,受力等来计算速度和位移。这个环境render出来如下:
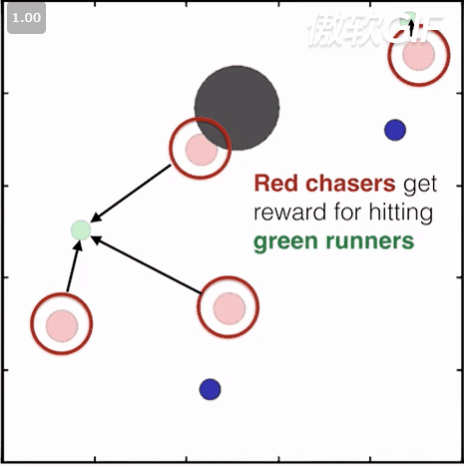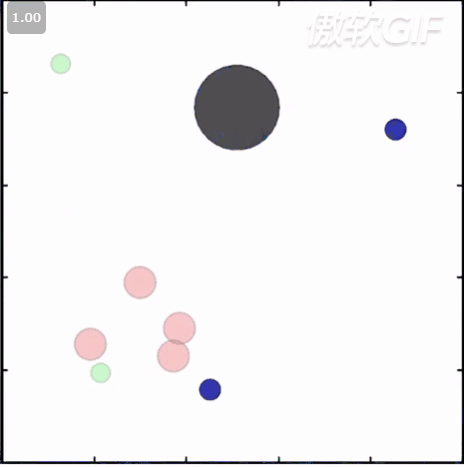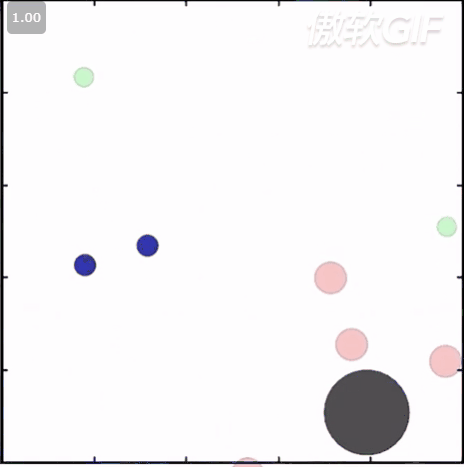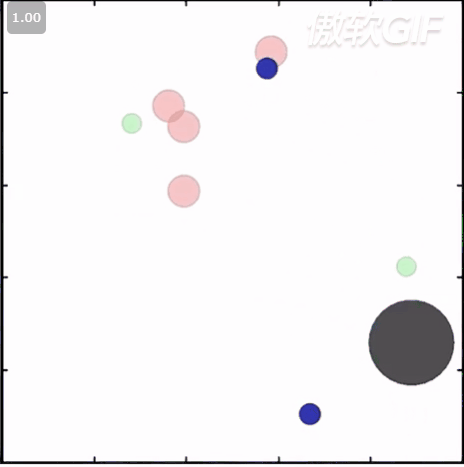
3. MAgent 环境:
Link:https://github.com/geek-ai/MAgent
这个是UCL汪军老师团队Mean Field 论文里用到的环境,主要研究的是当环境由大量智能体组成的时候的竞争和协作问题。也可以看成是复杂的Grid World环境。Render如下:
4. Pommerman 环境:
Link:https://www.pommerman.com/
这个炸弹人环境是NIPS18的比赛挑战项目,可以组队进行参加。环境主要是2v2,每队控制两个agent,agent是partial observable,应该是只能观测到自己附近的环境。此外还有个场景可以进行通讯。

5. Multiagent emergence 环境:
Link:https://github.com/openai/multi-agent-emergence-environments
这个环境是OpenAI 的捉迷藏环境,主要讲的是两队开心的小朋友agents在玩捉迷藏游戏中经过训练逐渐学到的各种策略。看了一眼,这么有质感的画面居然是基于mujoco的。
参见paper:https://arxiv.org/abs/1909.07528,
blog:https://openai.com/blog/emergent-tool-use/。
哔哩哔哩视频:https://www.bilibili.com/video/BV1ZA411N7jg

6. Quake III Arena Capture the Flag 环境:
Link:https://github.com/deepmind/lab
这个环境来自 DeepMind的lab环境https://arxiv.org/pdf/1612.03801.pdf,是其中一张雷神之锤III竞技场(Quake III Arena)的地图。主要是两队,每队由两个agent组成,在室内和户外两个场景下以第一人称视角竞争玩夺旗的游戏。
他们的论文成果发在了Science https://science.sciencemag.org/content/364/6443/859.fullijkey=rZC5DWj2KbwNk&keytype=ref&siteid=sci,
Blog:https://deepmind.com/blog/article/capture-the-flag-science,Render如下:

7. Google Research Football 环境:
Link:https://github.com/google-research/football
这个环境是google基于之前某个足球小游戏的环境进行改动和封装出来的,主要可以分为11v11 single-agent场景(控制一个active player在11名球员中切换)和5v5 multi-agent场景(控制4名球员+1个守门员)。该环境支持self-play,有三种难度内置AI可以打,你可以人肉去体验下,玩起来和实况,FIFA,绿茵之巅感觉都差不多。游戏状态基于vector的主要是球员的坐标/速度/角色/朝向/红黄牌等,也可以用图像输入,但需要打开render,估计会略慢,动作输出有二十多维,包括不同方向/长短传/加速等。此外环境还提供了所谓“football academy”,你可以自己进行游戏场景和球员坐标的初始化,相当于可以进行课程学习配置。Render如下:

8. Neural MMOs 环境:
Link:https://github.com/openai/neural-mmo
Neural MMOs也是OpenAI开源的一个大型的复杂ma游戏场景,没啥特别的特点,就是大,毕竟是MMO。这张大地图中,由于资源有限,agent要学着合作/竞争活下去,据说科学家们都可以基于此来研究生物进化,种群形成等很多社会性行为的形成过程。由于环境比较大,所以IO甚至都会有点比较大问题,这么多agent的状态的获取等都需要有特殊的方式来进行优化,他们的论文也讲了不少工程方面的事情,中了今年的AAMAS20的短文。Render如下:

9. StarCraft II 环境:
Link:https://github.com/oxwhirl/smac
星际争霸的环境大家应该也已经很熟悉了,作为即时策略的代表环境,DeepMind也研究了很长时间,AlphaStar也取得了很亮眼的表现,另外今天国内启元的星际指挥官的挑战赛,表现也不赖(虽然全屏 ),维京和多线用的666,血虐TIME。也有很多知名算法是基于星际环境,如大Qmix,COMA等。这个SMAC环境比DeepMind的pySC2 https://github.com/deepmind/pysc2 更侧重decentralized场景和单元控制,更易去验证一些ma的算法。场景如下:
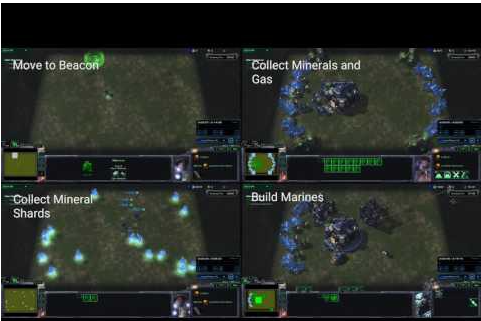
10. Unity ML-Agents Toolkit环境:
Link:https://github.com/Unity-Technologies/ml-agents
准确来讲,这并不仅仅是一个环境,这是一个游戏引擎。什么是游戏引擎呢?说通俗点就是用来做游戏的IDE。目前市场上有不少游戏都是基于Unity的,特别是手游。所以呢,理论上当你掌握了unity,你就可以自己去写任何你需要的炫酷模拟仿真环境,所以,不会用unity的调包侠不是好的炼丹师(手动doge)。参见几个他们论文中展示的环境:

11. Fever Basketball 环境:
Link:https://github.com/FuxiRL/FeverBasketball
最后呢,再上一个彩蛋吧!。潮人篮球(https://chao.163.com/)环境即将开源!我们这里不仅有多种角色多种位置(PG,SG,C,PF,SF)可供选择,更有多种场景(1v1,2v2,3v3)可供训练,还有不同难度的AI陪虐!当然Self play也必须支持滴!是兄弟,就来我们github页面,点亮顶上的watch和star按钮,练好你的Agents
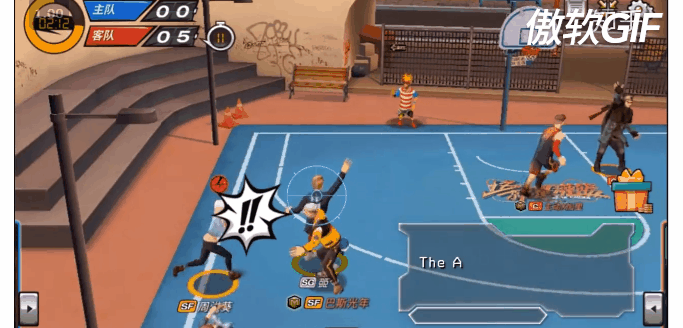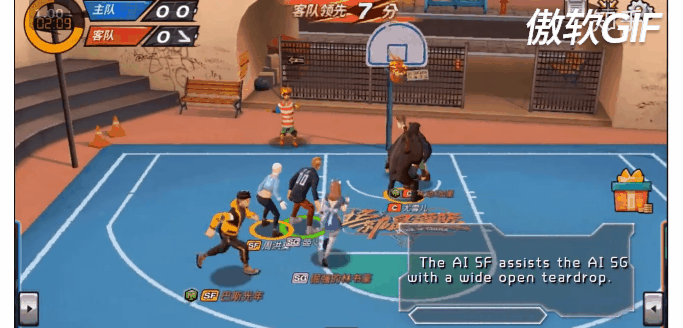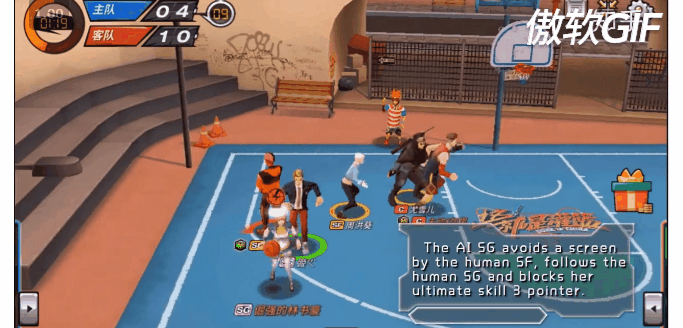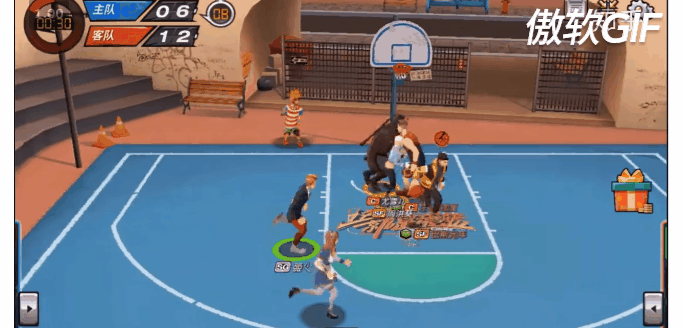
参考链接:https://www.zhihu.com/question/332942236
最后
以上就是飘逸唇膏最近收集整理的关于常见多智能体强化学习仿真环境介绍【一】{推荐收藏,真的牛}1. Multi-agent Reinforcement Learning 环境:2. Particle 环境:3. MAgent 环境:4. Pommerman 环境:5. Multiagent emergence 环境:6. Quake III Arena Capture the Flag 环境:7. Google Research Football 环境:8. Neural MMOs 环境:9. StarCraft II 环境:10的全部内容,更多相关常见多智能体强化学习仿真环境介绍【一】{推荐收藏,真的牛}1. Multi-agent内容请搜索靠谱客的其他文章。








发表评论 取消回复